ИИ переживает бум: компании в разных отраслях пытаются внедрить его всюду – от клиентской поддержки и продаж до аналитики. Один из популярных сценариев – автоматизация коммуникаций. Здесь ИИ может отвечать на звонки и сообщения, помогать операторам во время разговора или анализировать качество диалогов. Но есть у ИИ особенность, которая иногда становится серьёзной «головной болью» для сервиса – склонность к галлюцинациям.
Вместо точных ответов на вопрос клиенты получают вымышленные факты. Например, робот сообщает: «Вы сегодня говорили с нашим менеджером Олегом…», тогда как в компании нет ни одного Олега. Хорошая новость: галлюцинации можно минимизировать.
Компания IPTel, которая разрабатывает системы для автоматизации коммуникаций, использует в своих продуктах разные ИИ-модели: от локальных – для простых задач голосовых роботов до более гибких LLM – таких как Gemini, DeepSeek, ChatGPT и Llama – в сложных диалогах, ИИ-помощниках и сервисах речевой аналитики.
В партнёрском проекте CEO IPTel Иван Виноградов рассказал, как можно применить ИИ в бизнес-коммуникациях, почему возникают галлюцинации и как их минимизировать.
Содержание
С чего начать внедрение ИИ-модели
Итак, вы прочитали статью про «успешный успех» конкурента, который внедрил ИИ, и подумали: «Хочу так же!». Но первый и самый важный вопрос – не какую модель выбрать, а какую задачу бизнеса должен решить ИИ.
Практика показывает: на старте лучше выбрать 1-2 процесса, где ИИ даст заметный результат. Это могут быть операции с предсказуемым сценарием и ограниченным количеством возможных ответов.
Другой критерий, который упростит выбор и внедрение: процесс должен быть описан – в виде скрипта или регламента. ИИ хуже справляется там, где процессы не формализованы.
В коммуникациях с клиентами внедрение ИИ часто начинают с обработки повторяющихся вопросов. Это делает голосовой робот, который отвечает на звонки или, в связке с системой автообзвона, совершает исходящие. У него «под капотом» локальная LLM модель с жёсткими инструкциями: она формирует реплики в рамках сценария – приветствует клиента по имени, может рассказать про услуги компании и ответить на вопросы вроде «Какие условия рассрочки?» или «Когда будет доставлен заказ?».

Есть и более сложные сценарии в которых голосовой робот должен выбирать, как взаимодействовать с клиентом и что предложить. Один из примеров – мягкое напоминание о задолженности (soft-collection) в финансовом секторе или в коммунальных предприятиях. Система может вести диалог по нескольким траекториям: рассказать про разные варианты оплаты или реструктуризации, либо зафиксировать отказ и выбрать следующий шаг сценария.
Однако ИИ можно использовать не только для автоматизации общения с клиентом, а и для помощи оператору. В таких сценариях ИИ работает с контекстом разговора и данными из внутренних систем, но не ведёт диалог напрямую.
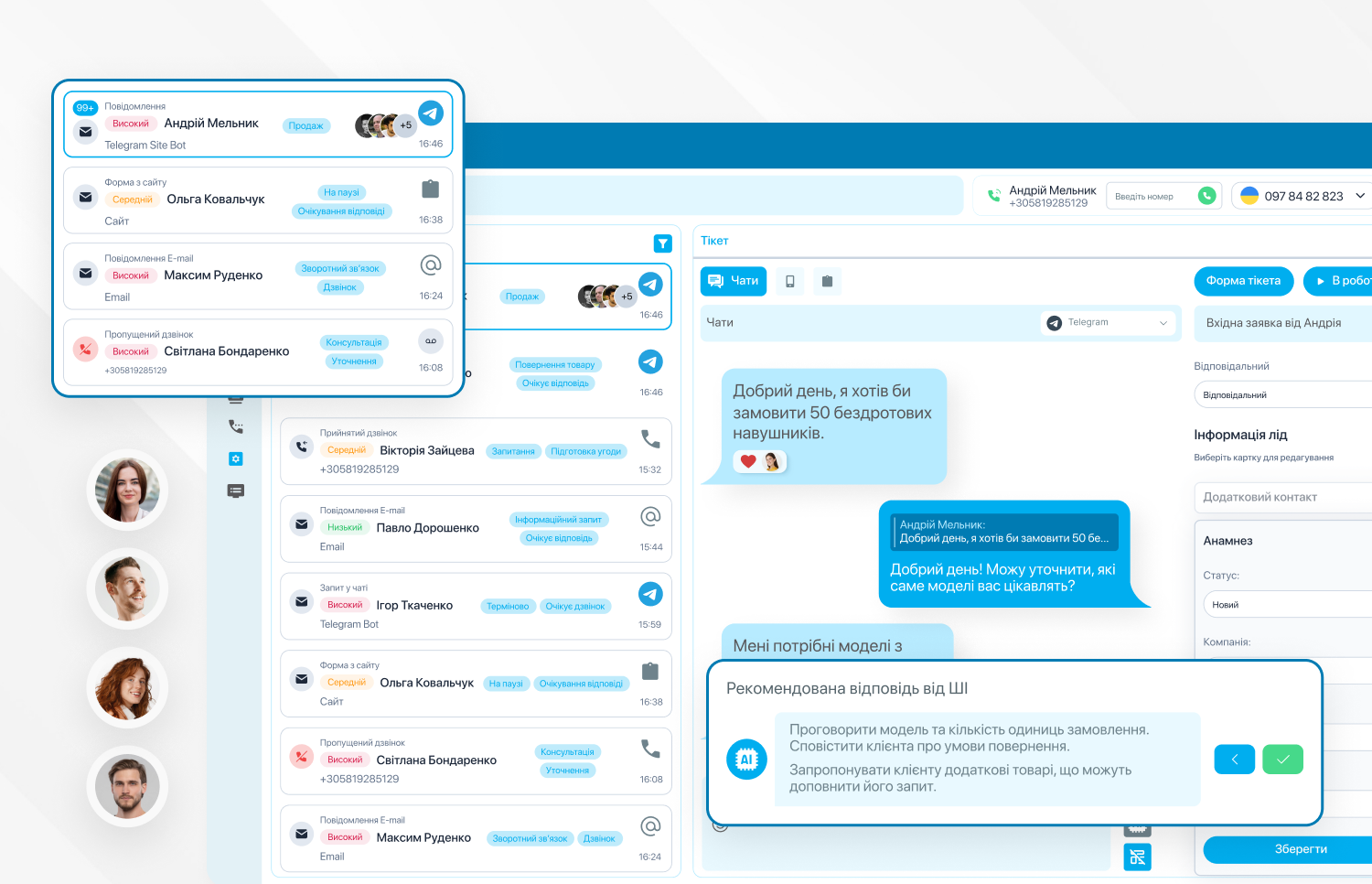
Во время общения с клиентом модель анализирует разговор или переписку и подсказывает оператору, что нужно уточнить или какой следующий шаг предусмотрен сценарием. Кроме того, оператор может сам обратиться к ИИ-помощнику через диалоговое окно и задать вопрос по ходу разговора. В ответ модель сразу возвращает информацию из корпоративной базы знаний. Такое использование ИИ востребовано в сферах с большим объёмом информации, таких как медицина, где оператор должен быстро ответить клиенту, как, например, подготовиться к процедуре или какие есть противопоказания.
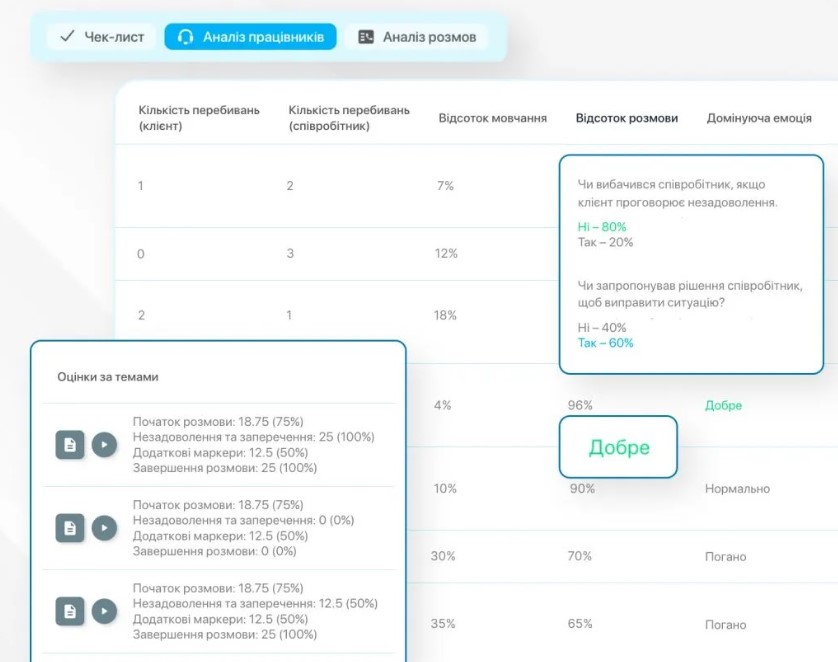
Ещё один тип задач – анализ качества коммуникации. Здесь ИИ расшифровывает запись звонков, разделяет роли «клиент/сотрудник», отмечает ключевые слова, к примеру, упоминания конкурентов, фиксирует жалобы и анализирует эмоции. Это позволяет быстро выявлять проблемы без прослушивания разговоров, что особенно актуально для сферы электронной коммерции, где качество сервиса влияет на продажи.
Как выбрать модель: опыт IPTel
Выбор модели зависит от того, какой скорости обработки, точности и сложности диалога требует ваша задача.
- В задачах, где диалог укладывается в заранее описанную логику, а задержки недопустимы, ключевой фактор выбора – скорость отклика. Тут подходят модели, оптимизированные под работу в реальном времени. В голосовых роботах IPTel, которые должны отвечать на частозадаваемые вопросы, мы используем модели класса Gemini Flash, DeepSeek Lite или локально развёрнутые версии Llama 3.x (8-13B). Они работают в рамках строгих инструкций и формируют ответы по заданным правилам с минимальной задержкой, что идеально подходит для звонков.
- Сложные сценарии, где одного правильного ответа недостаточно, требуют моделей, которые учитывают контекст разговора и на основе этого выбирают следующий шаг. В голосовых роботах, которые должны поддерживать диалог, мы используем модели вроде Gemini, DeepSeek или актуальные версии ChatGPT. Они позволяют строить диалог не по жёсткому скрипту, а в рамках заданных паттернов общения.
- В аналитических задачах для оценки качества коммуникации на первый план выходят стабильность, и способность обрабатывать большие объёмы данных. В сервисе речевой аналитики IPTel мы используем несколько технологий. Для преобразования аудио в текст – речевые модели Whisper или Wav2Vec2. Разделение ролей в диалоге выполняется с помощью PyAnnote. Далее к обработке подключаются языковые модели, которые работают с готовым текстом: формируют резюме разговора и выделяют сигналы для бизнеса. Для этого используются LLM вроде DeepSeek, Gemini или Llama.

Причины галлюцинаций
Однажды во время разговора с клиентом наш голосовой робот внезапно переключился на китайский язык. Но более удивительной оказалась реакция клиента: он знал китайский и спокойно продолжил диалог. Конечно, вероятность, что при следующей такой галлюцинации нам бы повезло наткнуться на полиглота, минимальная. Мы решили проблему специализацией промпта – скорректировали инструкции для нейросети, чтобы она использовала только два языка.
По нашим наблюдениям, примерно в 70% случаев причиной «фантазий» ИИ являются повторяющиеся паттерны в промпте и данных. Представьте себе базу данных, где лежат 20 старых FAQ, в каждом из них есть фраза «срок рассмотрения – 3 дня». ИИ зацикливается на этом, и в дальнейшем на любой вопрос клиента по срокам начинает отвечать «3 дня».
Яркий признак, что база данных имеет пробелы, – ИИ начинает нести чушь. Человек задает вопрос роботу, а данные, как отвечать не загрузили в базу. Тогда нейросеть придумывает ответ, чтобы поддержать разговор. Та же проблема возникает, если в данных шум, противоречия или устаревшая информация.
Примерно в 20% случаев причиной галлюцинаций становится обновление моделей. Технически ИИ может отвечать быстрее, но точность ответов падает: до обновления бот говорил «не знаю, уточню в базе», когда сомневался в ответе, после – уверенно «додумывает».
Как бороться с проблемой
Мы рассматриваем галлюцинации не как единичные ошибки модели, а как системный риск, который нужно снижать на уровне архитектуры. На практике наиболее эффективными оказались следующие подходы:
- RAG-архитектура с принципом «отвечать только на основании контекста». Сначала система подбирает релевантные фрагменты из корпоративной базы знаний и лишь затем передаёт их модели для генерации ответа. В результате он состоит из конкретных фактов, которые можно проверить. В продуктах IPTel этот принцип заложен в работе голосовых роботов: модель отвечает только на основе данных, которые были переданы ей системой.
- Строгие системные инструкции и форматы ответов. Даже при работе с заданным контекстом риск галлюцинаций сохраняется, если модель получает слишком много свободы в формировании ответа. Чёткие правила поведения модели – что «разрешено», что «запрещено» и как действовать при недостатке данных снижают его. В продуктах IPTel такие инструкции дополняются строгими форматами вывода, например JSON с валидацией.
- Проверка ответов. Сразу после генерации ответа модель сравнивает его с альтернативными вариантами и известными данными, и рассчитывает показатель уверенности. Если он ниже заданного порога, ответ не публикуется автоматически, а передаётся оператору или QA-специалисту на проверку. Человек может подтвердить корректность ответа, внести правки или дополнить базу знаний. Мы применяем такой подход в голосовых роботах и ИИ-помощниках. Он позволяет отсеивать сомнительные ответы до того, как они повлияют на клиента или бизнес-процессы.
- Double-check с помощью второй модели. Разные модели ошибаются по-разному, но если ответ сходится, риск ошибки ниже. Поэтому мы используем дополнительную модель для проверки фактов, чисел и соответствия контексту.
- Единая структура транскрипций и метаданных. Если они передаются модели в разном формате, ей приходится интерпретировать структуру самостоятельно, что увеличивает риск ошибок. В продуктах IPTel мы используем единую структуру с фиксированными полями и однозначной логикой, чтобы форматы были однородными. Это снижает шум, упрощает валидацию и делает поведение модели более стабильным.
Кроме этого, мы ведём реестр галлюцинаций, где фиксируем все проблемные кейсы: чего не хватило в данных, где были противоречия, а где модель вышла за рамки инструкций. Это позволяет отслеживать повторяющиеся ошибки и улучшать решения.
Борьба с галлюцинациями – это непрерывный процесс. Модели обновляются, архитектура требует постоянной адаптации, а ИИ – инвестиций. Если у вас есть сильная команда и время – вы сможете самостоятельно предотвращать галлюцинации, комбинируя архитектурные решения, процессы проверки и участие человека.
Если важнее скорость и предсказуемость – проще опереться на подрядчика с опытом внедрения ИИ в бизнес-процессы, чем изобретать все с нуля. Тогда это перестает быть дорогим экспериментом и становится инструментом для роста бизнеса.
Над текстом работали: Анастасия Пономарева, Алена Лебедева
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: