

В феврале Министерство цифровой трансформации Украины объявило о запуск WINWIN AI Center of Excellence — подразделения, которое займется интеграцией ИИ-решений на государственном уровне, а в будущем — поможет создать конкурентов больших языковых моделей (LLM), аналогичных OpenAI, Anthropic, Google Gemini или DeepSeek. Эта инициатива направлена на развитие и внедрение новейших технологий в сфере искусственного интеллекта (ИИ), в частности генеративных моделей, подобных ChatGPT. В Украине есть талантливые инженеры и ученые, которые работают в ведущих мировых компаниях. Но достаточно ли этого для разработки и внедрения национальной LLM? И, вообще, зачем она нужна? Разбирались вместе с Минцифры и Андреем Никоненко — Manager, Machine Learning & Data Science в Turnitin.
Потянет ли Украина собственную LLM? Увидим уже в конце года
Сфера больших языковых моделей (LLM) развивается чрезвычайно быстро, и несколько ключевых игроков играют ведущие роли. Сейчас рынок поделен между несколькими гигантами, и четверку лидеров составляют американские компании:
- OpenAI (GPT-4o)
- Anthropic (Claude 3.6)
- Google DeepMind (Gemini 2.5)
-
Meta (Llama 4)
- DeepSeek (DeepSeek-R1) из Китая и Mistral AI (Le Chat) из Франции.
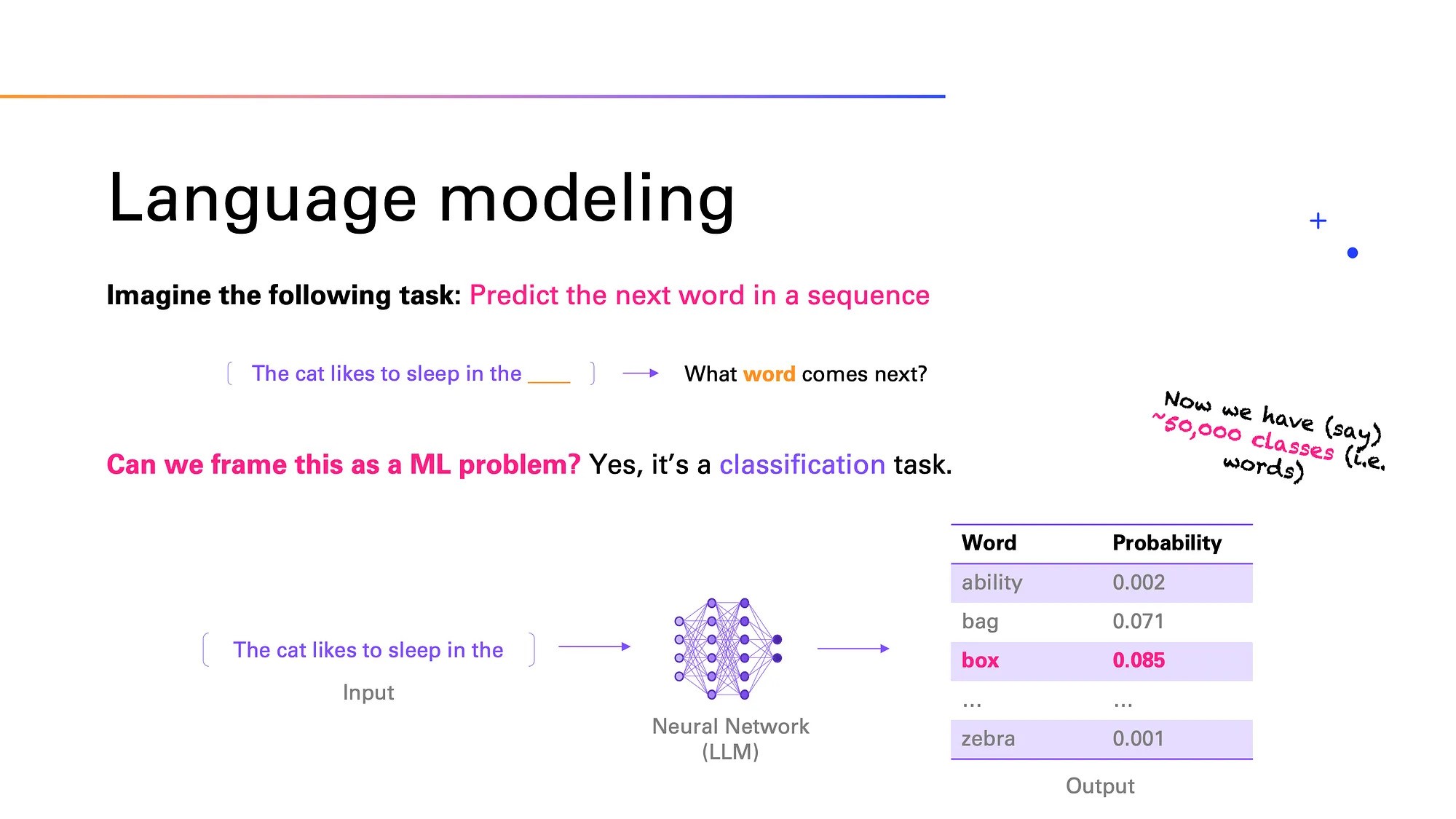
Что такое большая языковая модель (LLM) и как она работает?
Большая языковая модель (Large Language Model, LLM) — нейронная сеть, натренированная на огромных объемах текстовых данных для понимания, обработки и генерирования естественной речи. Нейросеть умеет предсказывать следующее слово в предложении, отвечать на вопросы, переводить и создавать связные тексты на любую тему, и при этом имитировать стиль и логику живой человеческой речи. LLM используются в чат-ботах, поисковых системах, автоматизированном переводе и других сферах.
Развитие больших языковых моделей (LLM) тесно связано с тем, как развивались способы обработки человеческой речи и машинное обучение. Сначала модели работали на основе рекуррентных нейронных сетей (RNN) и LSTM — технологий, которые помогали «запоминать» предыдущие слова. Настоящий прорыв пришел в 2017 году, когда Google представив трансформеры — новую архитектуру, которая позволяла лучше работать с текстом. Основа трансформеров — механизм самовнимания (self-attention): модель «разбирает» разные слова в предложении, чтобы лучше понять их смысл в общем контексте. Это помогает эффективно обрабатывать длинные тексты и учитывать связи между словами, даже если они находятся далеко друг от друга. Благодаря этому модель может понимать контекст всего текста в целом и выдавать содержательный и логически построенный ответ.
Например, ChatGPT от OpenAI способен создавать текст, который трудно отличить от человеческого. Эта модель популярна в различных приложениях: от чат-ботов до автоматизированного написания статей. А Google Gemini ориентирована на глубокое понимание контекста, что критично для улучшения релевантности (соответствия полученного результата желаемому) результатов выдачи в поисковых системах.
Большие языковые модели работают благодаря методу глубокого обучения (deep learning). Этот процесс происходит следующим образом:
- Поиск и подготовка данных
Чтобы обучить модель, нужно много текстов. Ее «тренируют» на огромных объемах текстовой информации — из книг, форумов, статей, логов веб-сайтов и так далее. Важно, что эти данные неразмечены, то есть в них нет специальных меток (labels), которые бы объясняли, что означает каждый фрагмент. Благодаря этому такие данные дешевле и легче доступны для сбора. Прежде чем передать тексты модели, их очищают: удаляют личную информацию, неприемлемый или лишний контент
- Токенизация
Машина не воспринимает текст так как человек. Поэтому перед обработкой текст разбивают на маленькие части — токены. Это могут быть отдельные слова, части слов или даже символы. Затем эти токены превращаются в числа, с которыми и начинает работать нейросеть. Это нужно для того, чтобы модель лучше понимала контекст. Например, если использовать только слова, то нужно сохранять все возможные формы слова («работает», «работал», «работал», «будет работать»). А если работать с частями слов, то можно «составить» любое слово из меньших частей. Это экономит память, ускоряет работу и снижает затраты на вычисления
- Архитектура трансформера
Название ChatGPT содержит аббревиатуру GPT — Generative Pre-trained Transformer. Generative — потому что модель умеет создавать (генерировать) новый текст. Pre-trained — потому что ее сначала обучили на большом количестве текста, а уже потом дополнительно адаптировали. Transformer — это тип нейросети, который использует механизм самовнимания (self-attention)
- Предварительное обучение
На этом этапе модель учится распознавать закономерности, учится предсказывать следующее слово в предложении или угадывать пропущенное. Это называется causal language modeling и masked language modeling
- Тонкая настройка (fine-tuning)
После того как модель уже знает много об определенном языке, ее «дообучают» под определенные задачи — например, чтобы она лучше писала медицинские статьи или помогала с Python-программированием. Также добавляется обучение на примерах с оценками от людей (RLHF — обучение с подкреплением на основе человеческого отклика). То есть, специалисты оценивают качество ответа машины.
- Генерация текста (инференция)
После ввода пользователем запроса (промта), модель начинает создавать ответ (по одному токену за раз). Она пытается продолжить текст так, чтобы он звучал логично и естественно.

LLM — мощный инструмент для генерации текста, перевода, анализа и т. Д. Однако его создание требует колоссальных ресурсов, а использование требует осторожности. Процесс обучения большой языковой модели связан с потребностью в огромном количестве данных, которые будут использоваться в учебном наборе. Обработка займет месяцы или даже годы, для чего потребуются невероятные вычислительные ресурсы и электроэнергия. Также требуется решение проблем параллелизма (когда вычисления выполняются одновременно на нескольких ядрах процессора или GPU. Поэтому могут возникать трудности с распределением, синхронизацией и т.п.).
Большие языковые модели имеют и другие недостатки. Главный — галлюцинации. То есть, в их ответах часто случаются ошибки (модель может выдумать событие или человека). Кроме того, большие языковые модели требуют огромного количества вычислительных ресурсов и электроэнергии.
Потому что чем больше данных используется для обучения, тем выше потенциальное качество модели. Однако это также означает более долгое и дорогое обучение. Инференция (то есть генерация ответа) будет дешевле, если сама модель меньше, потому что ее запуск требует меньше ресурсов. Но обычно большие объемы данных используют именно для создания больших моделей, то есть, инференция таких моделей требует больше ресурсов. Приходится соблюдать баланс между размером модели, качеством ответа и стоимостью ее использования.
Так зачем вообще национальная украинская LLM, если это настолько дорого, а большинство международных проектов используют уже существующие модели от лидеров рынка? Вот что нам ответили в Минцифры.
Англоязычные модели, на которых базируются самые популярные чат-боты ChatGPT, Gemini и другие, показывают худшие результаты работы с неанглоязычным контентом, чем локальные модели, натренированные на национальных языках.
Украинская LLM будет давать более качественные ответы, чем глобальные англоязычные модели, поскольку будет натренирована на украинских данных. Национальная LLM может лучше понимать диалекты, терминологию и контекст в стране, давая более качественные ответы как лингвистически, так и в отношении фактов и идеологических вопросов, касающихся истории Украины, политической ситуации и войны.Также национальная LLM позволяет хранить и обрабатывать данные внутри страны, что стратегически важно для использования ИИ в обороне, правительственных организациях, медицине и финансовом секторе.
При пользовании иностранными моделями данные, включая конфиденциальные, попадают за границу. Мы как страна не можем контролировать, как именно компании их хранят и обрабатывают. Национальная LLM решит этот вопрос, ведь данные украинцев и государства будут храниться внутри страны.Также важен национально-идеологический аспект. Иностранные модели тренируются на больших массивах данных с различными нарративами, включая враждебные Украине.
Национальная LLM будет иметь проукраинский взгляд на мир и корректно отвечать на сенситивные вопросы, связанные с войной, историей и тому подобное.Разработка украинского LLM предусматривает 6 этапов. Прежде всего, это организационная подготовка: набор экспертов в технический и этический борды, поиск партнеров. На этом же этапе собираем данные.
На втором и третьем этапах предусмотрены запуски пилотной модели на 1-3 миллиарда токенов и модели среднего масштаба на 11 миллиардов. Далее выравнивание и fine-tuning. После этого планируется запуск флагманской модели и оценка и развертывание полноценной модели.
Планируем запустить модель в ноябре-декабре 2025 года. Всего это 9 месяцев работы — от организационной работы и сбора данных для тренировки LLM до запуска полноценной модели.
Что нам нужно для создания конкурентоспособной LLM?
Ключевая цель украинской LLM — удовлетворить внутреннюю потребность государства и бизнеса, а не соревноваться на глобальном рынке с коммерческими моделями. Наибольшая ценность национальной LLM как раз в ее локализации и адаптации под национальный контекст.Вместе с тем национальная LLM создаст конкуренцию между бизнесами внутри страны. Модель заставит компании конкурировать на новом уровне — в частности соревноваться, чей AI-сервис и услуга будет удобнее для пользователя. Таким образом это будет влиять и на общий уровень жизни украинцев, экономику и состояние бизнес-сектора.
У нас нет времени и ресурсов, чтобы создавать модель с нуля, ведь нам нужно уже запускать ИИ-продукты, которые будут менять государственные сервисы и бизнес. Поэтому мы идем по пути pre-training и fine-tuning существующего open-source решения.
Прежде всего нужны качественные данные, в частности вычищенные и структурированные корпуса текстов, разбитые на токены. Во-вторых, это техническая инфраструктура для тренировки модели. И конечно, финансирование. Опыт других стран показывает, что на создание LLM уходит от $1,5 млн до $8 млн. На разработку LLM не будут использоваться государственные средства, поэтому ищем инвесторов среди бизнеса. Также рассматриваем сотрудничество с Big Tech и ведем переговоры с несколькими международными компаниями. Что касается pre-train модели, то имеющихся вычислительных ресурсов в Украине не хватает. С инференсом лучше: сейчас команда WINWIN AI Center of Excellence тестирует модели на H100 и менее мощные GPU, анализирует архитектурные вызовы и варианты масштабирования. Тем не менее украинские дата-центры готовят свои мощности к будущим нагрузкам, связанным с разработкой ИИ-продуктов.
Кроме того, у национальных провайдеров инфраструктуры есть мощности, которые можно использовать для тренировки LLM.Разработка LLM является совместным проектом государства, бизнеса и ИИ-сообщества, в частности исследователей, ученых, профильных сообществ и тому подобное. Бизнес станет ключевым провайдером инфраструктуры для тренировки модели. Профильные сообщества, университеты и научные учреждения будут помогать со сбором данных. Роль Минцифры и WINWIN AI Center of Excellence — координировать весь процесс.
Как Минцифры оценивает наличие качественных украинских текстовых данных? Есть ли инициативы по созданию национального корпуса текстов для ИИ?
Профильные сообщества и университеты собрали базу украиноязычных данных из открытых источников: это новости, данные из Википедии и т.д. Датасет «Малыш» является самым большим, это 113 гигабайт вычищенного текста. Также есть NER-UK, UA-GEC, БрУК и другие. Их достаточно для тренировки малых моделей, но на большие модели надо больше данных. Сейчас мы общаемся с университетами и научными учреждениями по расширению этих данных.
Сколько специалистов в области ИИ и Data Science, по вашему мнению, нужно для такого проекта? Достаточно ли их в Украине сейчас? Как война влияет на возможность привлечения ресурсов?
Да, таких специалистов достаточно. У нас уже есть потенциальная команда и стейкхолдеры для разработки модели. Организационно построение LLM предусматривает создание единой команды с несколькими подразделениями. Прежде всего это технический борд и команда разработки, которые отвечают за техническую сторону модели и ее тренировки.
Важно, чтобы модель работала этично — например, давала корректные ответы на национально-исторические вопросы. Поэтому будет сформирован этический борд, в который войдут юристы в сфере авторского права и этики, эксперты из сферы культуры и истории и другие специалисты, которые будут контролировать, насколько качественными являются данные. Для работы с данными будем привлекать университеты и украинский бизнес. Влияние войны на кадровый IT-рынок ощутимо, но когда мы говорим о LLM, то профильное сообщество мотивировано работать над этим проектом, потому что это стратегическая инициатива. Интересно, что к разработке LLM хотят участвовать и украинцы из-за рубежа. Поэтому видим максимальное участие украинского профессионального сообщества.
Что касается инфраструктуры, то у нас и до полномасштабной войны не было вычислительных мощностей, необходимых для pre-train (предварительного обучения) LLM. Очень низкая вероятность, что они появятся сейчас, ведь это требует больших инвестиций. Хотя украинские провайдеры имеют необходимый вычислительные мощности для запуска этой модели, но не для pre-train.
В чем экономическая выгода от создания собственной LLM?
Модель разрабатывается как open-source решение для некоммерческого сектора. Компании и разработчики смогут загрузить ее и создавать чатботы, ИИ-ассистентов и другие решения и таким образом повышать собственную эффективность и конкурентоспособность. Во-вторых, LLM даст пульс для появления новых стартап-решений с ИИ, которые будут привлекать инвестиции в Украину.
Также запуск украинского LLM даст толчок для появления целого ряда ИИ-решений для государственного сектора. WINWIN AI Center of Excellence при Минцифре уже начал работу над первыми продуктами: это ИИ-ассистент для Дії, ИИ-инструмент для анализа нормативно-правовых актов, ИИ-инструмент для перевода и анализа европейского законодательства и внутренние HR- и OKR-ассистенты для команды министерства. С появлением LLM ИИ-решений станет больше не только в Минцифре, но и в других государственных структурах.
Также Минцифра интегрирует искусственный интеллект в Мечту. ИИ будет создавать индивидуальные образовательные траектории для детей на базе их интересов, потребностей и мотивации. Это будет работать на базе ИИ-модели, которая поможет анализировать связи между темами, определять пробелы в знаниях и строить персонализированный путь обучения.Благодаря украинской LLM мы сможем активно интегрировать ИИ в системы Сил безопасности и обороны и таким образом повысить эффективность поражения на поле боя и анализа оборонных данных.
Сейчас ключевым блокером интеграции ИИ в оборонные системы является вопрос безопасности — ведь при использовании иностранных моделей данные переходят за границу. Благодаря украинской LLM данные будут оставаться в Украине.
Научные и образовательные учреждения смогут загружать ее и разворачивать на ее основе собственные решения — чатботы, ИИ-помощников и тому подобное. Благодаря этому ИИ станет частью украинского образования и науки и превратится в доступный инструмент в обучении и научных исследованиях. Как результат — индивидуальные подход в обучении и новые научные прорывы.
Насколько реален украинский ChatGPT?
Даже Евросоюз пока не обладает моделями, способными конкурировать с лидерами рынка. Инвестиции направлены лишь на определенные аспекты, а не на полномасштабные исследования. Какого-то значительного прорыва пока не достигнуто. Например, вспомним ИИ-чатбот под названием Lucie, который получил поддержку французского правительства, но был закрыт из-за значительных недостатков.
Как упоминалось выше, большинство языковых моделей, включая Llama от Meta, тренируются преимущественно на англоязычных данных, что влияет на качество ответов на других языках. Для разработки украинской языковой модели необходимо будет решать вопрос сбора качественных украиноязычных данных. Лучшие языковые модели тренируются на огромных массивах текстовых данных.
Для создания качественной украинской LLM нужен корпус (В лингвистике — подобранная и обработанная по определенным правилам совокупность текстов, которые используют как базу для исследования языка.) текстов размером в сотни миллиардов слов. Также важно обеспечить высокое качество данных, которые будут включать современный литературный, научный, технический и разговорный украинский язык. Хватит ли анонсированных Минцифры данных? Посмотрим в конце 2025-го.
Экспертное мнение от Андрея Никоненко — Manager, Machine Learning & Data Science в Turnitin
«Украинских текстовых данных объективно мало для полноценной тренировки большой языковой модели. Даже Llama-2 от Meta была натренирована преимущественно на англоязычных корпусах, где доля украинского была мизерной».

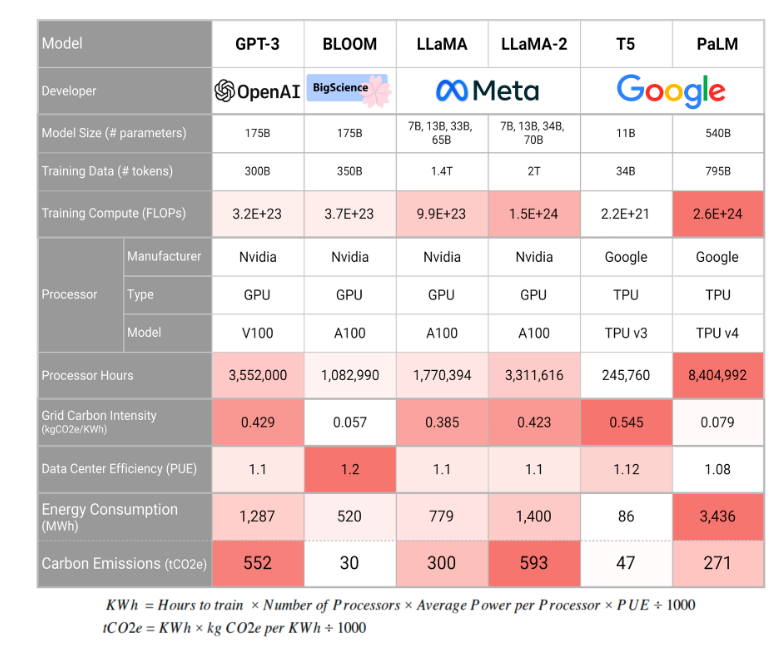
Создание полноценной украинской языковой модели уровня ChatGPT — сложная задача, требующая значительных ресурсов по нескольким ключевым направлениям. Чтобы обучить большую языковую модель (LLM), необходимы тысячи высокопроизводительных GPU или TPU, оптимизированных для ИИ-вычислений. Крупные американские компании, такие как OpenAI или Google, используют более 25 000 графических процессоров Nvidia для обучения своих моделей. Именно по этой причине стоит рассмотреть возможность использования готовых моделей с последующей адаптацией под украинские потребности.
«Большие языковые модели — не просто алгоритмы, а масштабные проекты, требующие интеграции большого количества ресурсов. Именно поэтому даже крупные страны, такие как Германия или Франция, не спешат создавать собственные LLM, а интегрируются в глобальные инициативы».
Важно получить и доступ к многоязычным наборам данных, если нужно, чтобы модель могла взаимодействовать и с другими языками.
Поэтому разработка языковой модели такого уровня потребует комплексного подхода и профессиональной команды, которая должна состоять из:
- Компьютерных лингвистов — специалистов, которые понимают структуру украинского языка и могут корректировать языковую модель.
- Дата-саентистов (data scientists) и инженеров — специалистов, которые занимаются обучением моделей, оптимизацией вычислительных процессов и разработкой архитектуры ИИ.
- Экспертов по этике, потому что важно, чтобы языковая модель не была предвзятой или некорректной.
К счастью, в Украине есть много специалистов и компаний, занимающихся искусственным интеллектом (AI), машинным обучением (ML) и обработкой естественного языка, например: SoftServe, ELEKS, Neurons Lab, Reface AI и другие.
«Подготовка собственного дата-центра под LLM — инвестиция в сотни миллионов долларов. Главным мотивом создания украинского LLM может быть вопрос безопасности. Однако следует понимать, что это не только о тренировке модели, но и о ее дальнейшей поддержке, обновлении и адаптации. Создание собственного дата-центра потребует сотни миллионов долларов, тогда как сотрудничество с международными платформами может снизить расходы. Вопросы безопасности и конфиденциальности являются критическими: государственная модель должна быть защищена от атак и несанкционированного доступа».
Украинская LLM будет гарантировать национальную кибербезопасность и станет двигателем инноваций в сфере ИИ. Собственная модель помогла бы использоваться в государственных сервисах и военной сфере, стимулировала развитие бизнеса на ее основе.
Например, исследование 2023 года показало, что внедрение искусственного интеллекта (ИИ) в финансовом секторе Украины может значительно повысить точность отчетности и помочь в преодолении кризисных ситуаций. ИИ способен улучшить качество финансовых данных, автоматизировать рутинные задачи, позволяя специалистам сосредоточиться на стратегическом планировании. В другом исследовании того же года, ученые поддержали идею с внедрением ИИ, поскольку считают, что в сфере государственных финансов существует немало проблем, которые невозможно решить традиционными методами.
Это амбициозная, но достижимая цель, которая может стать стратегическим прорывом для страны в сфере искусственного интеллекта. Реализация требует комплексного подхода, огромных инвестиций и международного сотрудничества. Не говоря о вопросах физической безопасности и стабильного энергоснабжения. Однако первый и самый тяжелый шаг уже сделан. Результаты увидим уже в конце 2025 года.





Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: