

Исследователи из Цюрихского и Амстердамского университетов, Университета Дьюка и Нью-Йоркского университета на основе нового теста установили, что модели на базе искусственного интеллекта легко отличить от людей по слишком дружелюбному эмоциональному тону.
В исследовании проверялись 9 моделей с открытым кодом Llama 3.1 8B, Llama 3.1 8B Instruct, Llama 3.1 70B, Mistral 7B v0.1, Mistral 7B Instruct v0.2, Qwen 2.5 7B Instruct, Gemma 3 4B Instruct, DeepSeek-R1-Distill-Llama-8B и Apertus-8B-2509 на примерах постов в соцсетях X, Bluesky и Reddit. Результаты продемонстрировали, что разработанные классификаторы распознают ответы, сгенерированные ИИ, с точностью до 70-80%.
Авторы представили так называемый «вычислительный тест Тьюринга» для оценки приближенности моделей ИИ к языку, на котором общаются обычные пользователи в интернете. Разработанный фреймворк использует автоматизированные классификаторы и лингвистический анализ для выявления специфических особенностей, отличающих сгенерированный ИИ контент от созданного людьми.
«Даже после калибровки результаты LLM остаются четко отличными от человеческого текста, особенно по эмоциональному тону и эмоциональному выражению», — подчеркивают авторы исследования.
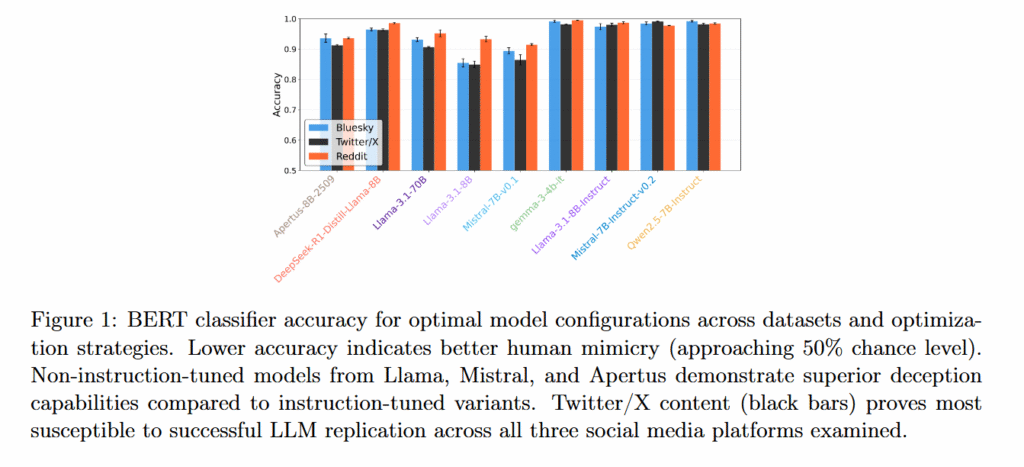
Группа под руководством Николо Пагана из Цюрихского университета протестировала различные стратегии оптимизации, от простых подсказок до тонкой настройки, однако обнаружила, что более глубокие эмоциональные сигналы сохраняются как надежные признаки того, что конкретное текстовое взаимодействие в интернете было инициировано чат-ботом, а не человеком. Когда ИИ предлагали давать ответы на реальные посты в соцсетях, LLM было трудно соответствовать уровню неформального негатива и спонтанного выражения эмоций, присущему постам людей. Показатели токсичности неизменно оказывались ниже, чем у людей.
Для устранения этого недостатка исследователи попытались применить стратегии оптимизации, включая предоставление примеров и поиск соответствующего контента. Эти стратегии должны были уменьшить структурные различия, включая длину предложений, качество слов, однако разница в эмоциональных составляющих оставалась.
«Наши комплексные калибровочные тесты ставят под сомнение предположение о том, что более сложная оптимизация обязательно приводит к более человеческому результату», — отметили в итоге ученые.
Кроме этого был обнаружен неожиданный результат. Модели, настроенные на выполнение определенных инструкций, прошедшие длительное обучение, хуже имитируют человека, чем базовые аналоги ИИ. Такие модели, как Llama 3.1 8B и Mistral 7B v0.1, демонстрировали лучшую имитацию поведения человека без настройки инструкций, обеспечивая точность классификации от 75% до 85%.
Масштабирование моделей также не предоставило никаких преимуществ. LLM Llama 3.1 с 70 млрд параметров продемонстрировала худшие результаты чем меньшие модели с 8 млрд параметров. Когда модели ИИ были настроены на то, чтобы избежать обнаружения путем подражания стилю человеческого письма, они все больше отклонялись от того, что люди действительно писали в ответ на те же сообщения (их семантическая оценка сходства с реальными человеческими ответами снизилась с медианного значения примерно 0,18-0,34 до 0,16-0,28 на разных платформах). После оптимизации на соответствие содержания ответов от людей сгенерированные ИИ тексты стало легче отличать как искусственные.
В исследовании простые методы оптимизации для снижения обнаружения превзошли сложные. Предоставление реальных примеров прошлых публикаций пользователя или получение соответствующего контекста неизменно затрудняло различение текста ИИ от человеческого текста в то время как сложные подходы, такие как предоставление ИИ описания личности пользователя и тонкая настройка модели, имели незначительное или даже негативное влияние на реалистичность.
Различия между социальными платформами также демонстрировали, насколько эффективно ИИ способны имитировать людей. Классификаторы выявляли ответы LLM в X с самой низкой точностью, далее шел Bluesky и Reddit, где тексты ИИ оказалось проще всего отличить от человеческих.
Исследователи предполагают, что эта закономерность отражает как особенности разговорного стиля каждой платформы, так и то, насколько активно данные с каждой платформы использовались в процессе начального обучения моделей. Исследование показывает, что имеющиеся модели сталкиваются с ограничениями, сохраняющимися в улавливании спонтанных эмоциональных проявлений, при этом частота обнаружения остается значительно выше случайной. Это не означает, что ИИ потенциально не может симулировать такой результат, просто это гораздо сложнее, чем ожидали исследователи.
Результаты опубликованы на сервере препринтов arXiv
Источник: ArsTechnica





Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: