

Яна ЛеКуна називають одним із хрещених батьків штучного інтелекту. Наприкінці 80-х він разом із двома іншими вченими — Джеффрі Хінтоном і Йошуа Бенжіо розробив концепцію згорткових нейронних мереж. Сьогодні це стандарт для розпізнавання та обробки зображень. Вони використовуються для виявлення об’єктів, медичної діагностики, розпізнавання облич, аналізу відео та багатьох інших завдань.
Ян обіймає в Meta посаду головного наукового співробітника з ШІ. Своєю головною метою він вважає створення нового типу штучного інтелекту, який зрівняється з людським і буде міркувати та розуміти світ так, як це роблять люди та тварини. Про те, як до цього дійти, чи зрівняється штучний інтелект із людським і чого дійсно варто боятися, він розповів на конференції AI for Good у Женеві. Я записав найцікавіші моменти з його виступу.
Зміст
LLM у поточному вигляді — глухий кут розвитку ШІ

Якщо ви зацікавлені в створенні надінтелекту або в тому, щоб ШІ зрівнявся з людським інтелектом, то великі мовні моделі (LLM) — це глухий кут. Це не означає, що LLM марні, але якщо ми хочемо досягти більшого, то нам доведеться винайти нові методи та нову архітектуру.
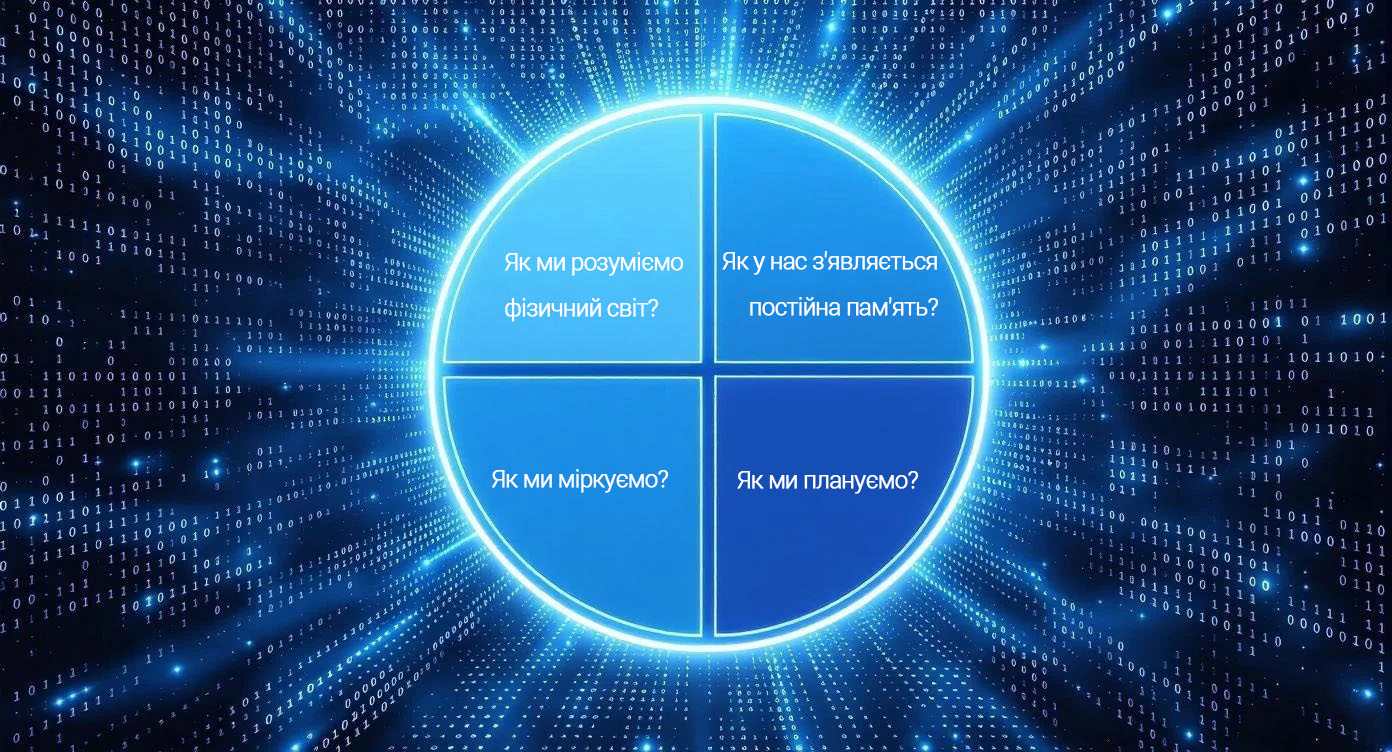
Спробуємо поставити чотири питання. Як ми розуміємо фізичний світ? Як у нас з’являється постійна пам’ять? Як ми міркуємо? Як ми плануємо?
Ці чотири сутності лежать в основі інтелекту. Жодна з LLM, що існує сьогодні, не здатна планувати, робити висновки на потрібному рівні, та й взагалі не володіє такими фундаментальними можливостями, як люди.
Колись ми навчимося створювати системи, які перевершать людський інтелект у більшості сфер, і я сподіваюся, що це станеться протягом наступного десятиліття. Для цього нам потрібно вирішити дві принципово важливі задачі.
Перша — це тип генерації відповіді на запит користувача — інференс. У процесі міркування LLM проходить через фіксовану кількість шарів нейромережі й в кінці видає відповідь, вона ж токен. Кількість обчислень, яку LLM може виконати для вироблення відповіді, — фіксована. І це проблема.
LLM витрачає однакову кількість ітерацій на пошук відповіді на просте питання, де достатньо сказати «так» або «ні», і на складне, де потрібно подумати глибше. І це безглуздо. Адже на просте питання можна відповісти відразу, а на складніше в людей вмикається процес міркування. Під час міркування люди в голові прокручують можливі сценарії розвитку подій, і в них немає потреби щось записувати, за винятком, наприклад, математики чи програмування. У більшості випадків ми міркуємо, плануємо, приймаємо рішення, використовуючи абстрактну модель того, що відбувається, в умі — все те, що психологи називають мисленням другого типу.
Зараз штучний інтелект обчислює відповідь, а ми прагнемо до того, щоб він навчився довго думати й шукати її. Це принципово інший процес.
Друга важлива річ: ШІ треба «заземлити» в нашій реальності. Не обов’язково фізичній — вона може бути віртуальною, але повинна бути якась база, звідки AI отримує інформацію з більшою пропускною здатністю, ніж просто текст. Людина отримує величезний обсяг інформації через зір, слух, дотик. Чотирирічна дитина вже знає стільки ж, скільки LLM, навчена на всіх доступних текстах в інтернеті. Ми не дійдемо до людського рівня AI, якщо не дамо системам зрозуміти реальний світ.
ШІ нового покоління міркуватиме абстрактно, а не намагатиметься вгадати наступне слово
Ми підходимо до головної проблеми — недосконалості сучасних архітектур. Сучасні LLM тренуються передбачати наступний токен, тобто підбирати окремі фрагменти тексту один за одним, а не моделювати навколишню дійсність, як це роблять люди.
Щоб система розуміла світ, потрібна нова архітектура. Я виступаю за JEPA — Joint Embedded Predictive Architecture. Це система, яка корінно відрізняється від LLM. У цій новій системі LLM все одно гратимуть свою роль, адже вони чудово перетворюють наші думки на зв’язний і зрозумілий текст.
Але JEPA — це не LLM, це зовсім інша сутність.
Багатьом це може здатися дивним, але мова — це відносно проста річ, бо вона дискретна: в ній обмежена кількість слів, і не так складно вгадати, яке буде наступне — що й роблять LLM. Але реальний світ набагато складніший. Якщо показати LLM відео конференц-залу і попросити її передбачити, що станеться далі, вона заплутається. Неможливо вгадати кожну деталь, на кшталт того, як виглядає кожна людина в залі чи якого кольору килим.
Ідея JEPA полягає в тому, щоб передбачати не токени, а абстрактні уявлення. Вона оперує вищим рівнем абстракції, ігноруючи деталі, які неможливо передбачити. Завдяки цьому виходить модель, яка краще розуміє, що відбувається.
Чи небезпечний такий ШІ?

Коли ми розберемося, як вийти на рівень ШІ, близький до людського, це не стане квантовим стрибком — ми пройдемо через рівні розуму, як у щурів, котів, собак тощо. У нас буде час зробити такі системи безпечними. ШІ майбутнього — objective-driven, він працюватиме на досягнення чітко заданої мети, і з «обмежувачами», які система не зможе порушити. У нинішніх LLM інша суть роботи, мета задається користувачем у промпті — і це дуже слабка специфікація, повністю залежна від того, як і на чому цю LLM навчали.
У новій архітектурі мета прописана спочатку, і система не може робити нічого, крім як розв’язувати задачу користувача в рамках заданих обмежень. Залишилося зрозуміти, як правильно формулювати ці мети та обмеження — задача складна, але не нездійсненна. Ймовірність, що така система нашкодить, приблизно така ж, як ймовірність вибуху наступного літака, на якому ви полетите, — вкрай мала, бо проєктуванням займаються професіонали, які десятиліттями вдосконалюють системи безпеки.
Це не означає, що треба взяти й зарегулювати ШІ повністю. ШІ, який застосовується для медичної діагностики чи допомоги водію, проходить випробування і перевірки, отримує схвалення держорганів — все як в авіації. Для чат-ботів такого регулювання немає, бо ризики малі, і серйозної шкоди за два роки їх масового використання не сталося.
Майбутнє ШІ — у відкритому коді
Моя роль у Meta — дослідження та довгострокова стратегія. Моя робота — надихати, просувати ідеї, на кшталт JEPA. Саме FAIR, дослідницький підрозділ Meta, виклав Llama у відкритий доступ, як і безліч інших напрацювань — понад тисячу проєктів за 11 років.
Я вірю в те, що ШІ повинен будуватися на основі систем з відкритим кодом. Історично склалося так, що платформи з відкритим кодом — безпечніші, надійніші, гнучкіші. Так працюють інтернет, мобільні мережі. Більше очей — швидше виправляються помилки. Для ШІ це особливо важливо: неможливо перевірити безпеку системи, якщо ти не можеш її модифікувати та тестувати.
На мою думку, найбільша небезпека сьогодні — це не ризики, що ШІ зробить щось не так, а те, що всі наші цифрові взаємодії проходитимуть через один чи два «закритих» ШІ-агентів, і ви отримуватимете всю інформацію з пари джерел. Уже зараз багато з нашого цифрового споживання — це результат роботи машинного навчання: не дуже розумного, але вони пишуть, фільтрують, модерують величезну кількість контенту.
У майбутньому весь наш цифровий раціон надходитиме від ШІ-систем.
Тому нам потрібно різноманіття ШІ-асистентів з різними мовами, культурними цінностями, політичними поглядами. Це можна порівняти з пресою: якщо у нас тільки один монополіст — це погано для суспільства. Та й багато країн не приймуть загрозу того, що вся інформація надходитиме, наприклад, зі США чи Китаю. Відкритий код — єдиний спосіб забезпечити таке різноманіття.

Іноді лунають пропозиції, що, мовляв, open-source — це погано, ось подивіться, китайський DeepSeek навчався на Llama. Можна подумати: «а раптом закрити розробки на Заході й сповільнити поширення ідей, щоб конкуренти відстали?».
Але вони все одно дізнаються, тільки з затримкою. Проблема в тому, що ми будемо повільніше рухатися самі, самі себе гальмуватимемо. Це як стріляти собі в ногу. Треба бути найкращими в умінні брати нові ідеї та впроваджувати їх. До того ж ми, своєю чергою, навчалися у DeepSeek та інших моделей, у тому числі й у китайських колег, які активно викладають свої моделі у відкритий доступ.
Навіть якщо повністю ізолювати Китай інтелектуально, у них все одно відмінні інженери та вчені, і вони швидко наздоженуть, а можливо, навіть обженуть Захід. Приклад DeepSeek став шоком для багатьох у Каліфорнії.
ШІ повинен посилювати, а не замінювати людину
У майбутньому, думаю, ситуація буде схожа на сучасний ринок операційних систем: 2–3 домінуючі платформи, серед яких одна-дві будуть відкритими, плюс ще пара-трійка закритих і нішевих для спецзавдань. Я так вважаю, бо бачу майбутнє, в якому LLM і те, що за ними піде, стануть сховищем усього людського знання та культури. Щоб це реалізувати, їм знадобиться доступ до даних з усього світу, з різних країн і регіонів.

Але країни не готові ділитися даними просто так — їм потрібен ШІ-суверенітет, тобто контроль над власними даними та над тим, як на них навчається та працює штучний інтелект.
Тому єдиний вихід — міжнародне партнерство, при якому майбутні моделі навчатимуться розподілено, обмінюючись не даними, а параметрами моделей. Так вийде загальна консенсус-модель без втрати кожною країною суверенітету над своїми даними. І це обов’язково повинен бути відкритий вихідний код.
Головне: нам потрібен відкритий, безпечний, різноманітний AI, який посилює, а не замінює людину чи створює віртуальних людей.





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: