

У лютому Міністерство цифрової трансформації України оголосило про запуск WINWIN AI Center of Excellence — підрозділу, який займеться інтеграцією ШІ-рішень на державному рівні, а в майбутньому — допоможе створити конкурентів великих мовних моделей (LLM), аналогічних до OpenAI, Anthropic, Google Gemini чи DeepSeek. Ця ініціатива спрямована на розвиток і впровадження новітніх технологій у сфері штучного інтелекту (ШІ), зокрема генеративних моделей, подібних до ChatGPT. Україна має талановитих інженерів та науковців, які працюють у провідних світових компаніях. Але чи достатньо цього для розробки та впровадження національної LLM? І, взагалі, навіщо вона потрібна? Розбирались разом з Мінцифри та Андрієм Никоненком — Manager, Machine Learning & Data Science в Turnitin.
Чи потягне Україна власну LLM? Побачимо вже наприкінці року
Сфера великих мовних моделей (LLM) розвивається надзвичайно швидко, і кілька ключових гравців відіграють провідні ролі. Наразі ринок поділений між кількома гігантами, і четвірку лідерів складають американські компані:
- OpenAI (GPT-4o)
- Anthropic (Claude 3.6)
- Google DeepMind (Gemini 2.5)
-
Meta (Llama 4)
- DeepSeek (DeepSeek-R1) з Китаю та Mistral AI (Le Chat) з Франції.
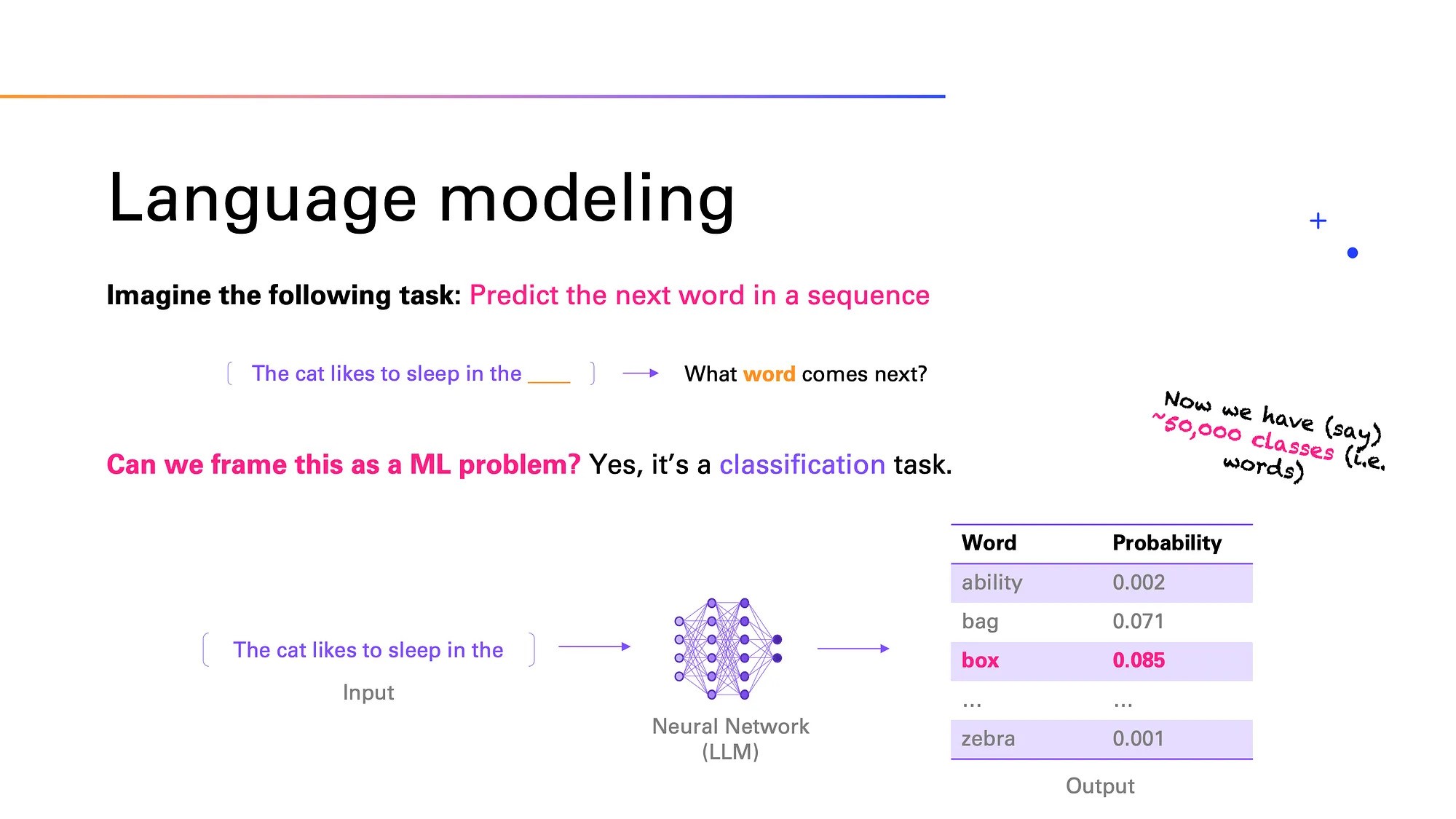
Що таке велика мовна модель (LLM) та як вона працює?
Велика мовна модель (Large Language Model, LLM) — нейронна мережа, натренована на величезних об’ємах текстових даних для розуміння, обробки та генерування природної мови. Нейромережа вміє передбачати наступне слово в реченні, відповідати на запитання, перекладати та створювати зв’язні тексти на будь-яку тему, й при цьому імітувати стиль і логіку живої людської мови. LLM використовуються у чат-ботах, пошукових системах, автоматизованому перекладі та інших сферах.
Розвиток великих мовних моделей (LLM) тісно пов’язаний із тим, як розвивалися способи обробки людської мови та машинне навчання. Спочатку моделі працювали на основі рекурентних нейронних мереж (RNN) і LSTM — технологій, що допомагали «запам’ятовувати» попередні слова. Справжній прорив прийшов у 2017 році, коли Google представив трансформери — нову архітектуру, яка дозволяла краще працювати з текстом. Основа трансформерів — механізм самоуваги (self-attention): модель «розбирає» різні слова у реченні, щоб краще зрозуміти їхній зміст у загальному контексті. Це допомагає ефективно обробляти довгі тексти й враховувати зв’язки між словами, навіть якщо вони знаходяться далеко одне від одного. Завдяки цьому модель може розуміти контекст усього тексту загалом і видавати змістовну та логічно побудовану відповідь.
Наприклад, ChatGPT від OpenAI здатен створювати текст, який важко відрізнити від людського. Ця модель популярна в різних додатках: від чат-ботів до автоматизованого написання статей. А Google Gemini орієнтована на глибоке розуміння контексту, що критично для покращення релевантності (відповідності отриманого результату бажаному) результатів видачі у пошукових системах.
Великі мовні моделі працюють завдяки методу глибокого навчання (deep learning). Цей процес відбувається наступним чином:
- Пошук та підготовка даних
Щоб навчити модель, потрібно багато текстів. Її «тренують» на величезних обсягах текстової інформації — з книжок, форумів, статей, логів вебсайтів тощо. Важливо, що ці дані нерозмічені, тобто в них немає спеціальних міток (labels), які б пояснювали, що означає кожен фрагмент. Завдяки цьому такі дані дешевші й легше доступні для збору. Перш ніж передати тексти моделі, їх очищують: видаляють особисту інформацію, неприйнятний або зайвий контент.
- Токенізація
Машина не сприймає текст так, як людина. Тому перед обробкою текст розбивають на маленькі частини — токени. Це можуть бути окремі слова, частини слів або навіть символи. Потім ці токени перетворюються на числа, з якими й починає працювати нейромережа. Це потрібно для того, щоб модель краще розуміла контекст. Наприклад, якщо використовувати тільки слова, то потрібно зберігати всі можливі форми слова (“працює”, “працював”, “працюватиме”). А якщо працювати з частинами слів, то можна «скласти» будь-яке слово з менших частин. Це економить пам’ять, прискорює роботу і знижує витрати на обчислення.
- Архітектура трансформера
Назва ChatGPT містить абревіатуру GPT — Generative Pre-trained Transformer. Generative — бо модель вміє створювати (генерувати) новий текст. Pre-trained — бо її спочатку навчили на великій кількості тексту, а вже потім додатково адаптували. Transformer — це тип нейромережі, який використовує механізм самоуваги (self-attention).
- Попереднє навчання
На цьому етапі модель навчається розпізнавати закономірності, вчиться передбачати наступне слово в реченні або вгадувати пропущене. Це називається causal language modeling і masked language modeling.
- Тонке налаштування (fine-tuning)
Після того, як модель уже знає багато про певну мову, її «донавчають» під певні завдання — наприклад, щоб вона краще писала медичні статті або допомагала з Python-програмуванням. Також додається навчання на прикладах з оцінками від людей (RLHF — навчання з підкріпленням на основі людського відгуку). Тобто, спеціалісти оцінюються якість відповіді машини.
- Генерація тексту (інференція)
Після введення користувачем запиту (промту), модель починає створювати відповідь (по одному токену за раз). Вона намагається продовжити текст так, щоб він звучав логічно і природно.

LLM — потужний інструмент для генерації тексту, перекладу, аналізу тощо. Проте його створення вимагає колосальних ресурсів, а використання вимагає обережності. Процес навчання великої мовної моделі пов’язаний з потребою у величезній кількості даних, які будуть використані у навчальному наборі. Обробка триватиме місяці або навіть роки, для чого потрібні неймовірні обчислювальні ресурси та електроенергії. Також потрібне розв’язання проблем паралелізму (коли обчислення виконуються одночасно на кількох ядрах процесора або GPU. Тому можуть виникати труднощі з розподілом, синхронізацію і т.п.).
Великі мовні моделі мають й інші недоліки. Головний — галюцинації. Тобто, в їхніх відповідях часто трапляються помилки (модель може вигадати подію або люду). Крім того, великі мовні моделі вимагають величезної кількості обчислювальних ресурсів і електроенергії.
Бо чим більше даних використовується для навчання, тим вища потенційна якість моделі. Проте це також означає довше та дорожче навчання. Інференція (тобто генерація відповіді) буде дешевшою, якщо сама модель менша, бо її запуск вимагає менше ресурсів. Але зазвичай великі обсяги даних використовують саме для створення більших моделей, тобто, інференція таких моделей потребує більше ресурсів. Доводиться дотримуватись балансу між розміром моделі, якістю відповіді та вартістю її використання.
Тож, навіщо взагалі національна українська LLM, якщо це настільки дорого, а більшість міжнародних проєктів використовують вже наявні моделі від лідерів ринку? Ось що нам відповіли в Мінцифри.
Англомовні моделі, на яких базуються найпопулярніші чат-боти ChatGPT, Gemini та інші, показують гірші результати роботи з неангломовним контентом, аніж локальні моделі, натреновані на національних мовах.
Українська LLM даватиме якісніші відповіді, аніж глобальні англомовні моделі, оскільки буде натренована на українських даних. Національна LLM може краще розуміти діалекти, термінологію та контекст в країні, даючи якісніші відповіді як лінгвістично, так і стосовно фактів та ідеологічних запитань, які стосуються історії України, політичної ситуації та війни.
Також національна LLM дозволяє зберігати та обробляти дані всередині країни, що стратегічно важливо для використання ШІ в обороні, урядових організаціях, медицині та фінансовому секторі.
При користуванні іноземними моделями дані, включно з конфіденційними, потрапляють за кордон. Ми як країна не можемо контролювати, як саме компанії їх зберігають та обробляють. Національна LLM розв’яже це питання, адже дані українців і держави будуть зберігатися всередині країни.
Також важливим є національно-ідеологічний аспект. Іноземні моделі тренуються на великих масивах даних з різними наративами, включно із ворожими Україні. Національна LLM буде мати проукраїнський погляд на світ та коректно відповідатиме на сенситивні запитання, пов‘язані з війною, історією тощо.
Розробка української LLM передбачає 6 етапів. Перш за все, це організаційна підготовка: набір експертів у технічний та етичний борди, пошук партнерів. На цьому ж етапі збираємо дані. На другому й третьому етапах передбачені запуски пілотної моделі на 1–3 мільярди токенів та моделі середнього масштабу на 11 мільярдів. Далі вирівнювання й fine-tuning. Після цього планується запуск флагманської моделі та оцінка й розгортання повноцінної моделі.
Плануємо запустити модель у листопаді-грудні 2025 року. Усього це 9 місяців роботи — від організаційної роботи та збору даних для тренування LLM до запуску повноцінної моделі.
Що нам потрібно для створення конкурентоспроможної LLM?
Ключова мета української LLM — задовольнити внутрішню потребу держави й бізнесу, а не змагатися на глобальному ринку з комерційними моделями. Найбільша цінність національної LLM якраз у її локалізації та адаптації під національний контекст.
Разом з тим національна LLM створить конкуренцію між бізнесами всередині країни. Модель змусить компанії конкурувати на новому рівні — зокрема змагатися, чий AI-сервіс та послуга буде зручнішим для користувача. Таким чином це впливатиме і на загальний рівень життя українців, економіку і стан бізнес-сектору.
У нас немає часу і ресурсів, щоб створювати модель з нуля, адже нам потрібно вже запускати ШІ-продукти, які будуть змінювати державні сервіси та бізнес. Тому ми ідемо шляхом pre-training та fine-tuning наявного open-source рішення.
Перш за все потрібні якісні дані, зокрема вичищені та структуровані корпуси текстів, розбиті на токени. По-друге, це технічна інфраструктура для тренування моделі. І звісно фінансування. Досвід інших країн показує, що на створення LLM іде від $1,5 млн до $8 млн. На розробку LLM не будуть використовуватися державні кошти, тому шукаємо інвесторів серед бізнесу. Також розглядаємо співпрацю з Big Tech та ведемо перемовити з кількома міжнародними компаніями. Щодо pre-train моделі, то наявних обчислювальних ресурсів в Україні не вистачає. З інференсом краще: зараз команда WINWIN AI Center of Excellence тестує моделі на H100 і менш потужні GPU, аналізує архітектурні виклики та варіанти масштабування. Проте українські дата-центри готують свої потужності до майбутніх навантажень, пов‘язаних з розробкою ШІ-продуктів.
Крім того, у національних провайдерів інфраструктури є потужності, які можна використовувати для тренування LLM.
Розробка LLM є спільним проєктом держави, бізнесу та ШІ-спільноти, зокрема дослідників, науковців, профільних спільнот тощо. Бізнес стане ключовим провайдером інфраструктури для тренування моделі. Профільні спільноти, університети та наукові установи будуть допомагати зі збором даних. Роль Мінцифри та WINWIN AI Center of Excellence — координувати весь процес.
Як Мінцифри оцінює наявність якісних українських текстових даних? Чи є ініціативи зі створення національного корпусу текстів для ШІ?
Профільні спільноти й університети зібрали базу україномовних даних з відкритих джерел: це новини, дані з Вікіпедії тощо. Датасет «Малюк» є найбільшим, це 113 гігабайтів вичищеного тексту. Також є NER-UK, UA-GEC, БрУК та інші. Їх достатньо для тренування малих моделей, але на більші моделі треба більше даних. Зараз ми спілкуємося з університетами та науковими установами щодо розширення цих даних.
Скільки спеціалістів у галузі ШІ та Data Science, на вашу думку, потрібно для такого проєкту? Чи достатньо їх в Україні зараз? Як війна впливає на можливість залучення ресурсів?
Так, таких спеціалістів достатньо. У нас вже є потенційна команда і стейкхолдери для розробки моделі. Організаційно побудова LLM передбачає створення єдиної команди з кількома підрозділами. Перш за все це технічний борд та команда розробки, які відповідають за технічну сторону моделі і її тренування.
Важливо, щоб модель працювала етично — наприклад, давала коректні відповіді на національно-історичні запитання. Тому буде сформований етичний борд, до якого ввійдуть юристи у сфері авторського права й етики, експерти зі сфери культури й історії та інші спеціалісти, які контролюватимуть, наскільки якісними є дані. Для роботи з даними залучатимемо університети й український бізнес.Вплив війни на кадровий IT-ринок відчутний, але коли ми говоримо про LLM, то профільна спільнота вмотивована працювати над цим проєктом, бо це стратегічна ініціатива. Цікаво, що розробки LLM хочуть долучатися й українці з-за кордону. Тож вбачаємо максимальну участь української професійної спільноти.
Щодо інфраструктури, то у нас і до повномасштабної війни не було обчислювальних потужностей, необхідних для pre-train (попереднього навчання) LLM. Дуже низька ймовірність, що вони з‘являться зараз, адже це потребує великих інвестицій. Хоча українські провайдери мають необхідний обчислювальні потужності для запуску цієї моделі, але не для pre-train.
У чому економічна вигода від створення власної LLM?
Модель розробляється як open-source рішення для некомерційного сектору. Компанії та розробники зможуть завантажити її та створювати чатботи, ШІ-асистентів та інші рішення і таким чином підвищувати власну ефективність та конкурентоспроможність. По-друге, LLM дасть пульс для появи нових стартап-рішень з ШІ, які будуть залучати інвестиції в Україну.
Також запуск української LLM дасть поштовх для появи цілої низки ШІ-рішень для державного сектору. WINWIN AI Center of Excellence при Мінцифрі уже почав роботу над першими продуктами: це ШІ-асистент для Дії, ШІ-інструмент для аналізу нормативно-правових актів, ШІ-інструмент для перекладу та аналізу європейського законодавства та внутрішні HR- та OKR-асистенти для команди міністерства. З появою LLM ШІ-рішень стане більше не лише в Мінцифрі, а й в інших державних структурах.
Також Мінцифра інтегрує штучний інтелект у Мрію. ШІ буде створювати індивідуальні освітні траєкторії для дітей на базі їхніх інтересів, потреб та мотивації. Це працюватиме на базі ШІ-моделі, яка допоможе аналізувати зв’язки між темами, визначати прогалини в знаннях і будувати персоналізований шлях навчання.
Завдяки українській LLM ми зможемо активно інтегрувати ШІ у системи Сил безпеки й оборони й таким чином підвищити ефективність ураження на полі бою та аналізу оборонних даних. Зараз ключовим блокером інтеграції ШІ в оборонні системи є питання безпеки — адже при використанні іноземних моделей дані переходять за кордон. Завдяки українській LLM дані будуть залишатися в Україні.
Наукові та освітні установи зможуть завантажувати її та розгортати на її основі власні рішення — чатботи, ШІ-помічників тощо. Завдяки цьому ШІ стане частиною української освіти й науки та перетвориться на доступний інструмент у навчанні та наукових дослідженнях. Як результат — індивідуальні підхід у навчанні та нові наукові прориви.
Наскільки реальний український ChatGPT?
Навіть Євросоюз наразі не володіє моделями, здатними конкурувати з лідерами ринку. Інвестиції спрямовані лише на певні аспекти, а не на повномасштабні дослідження. Якогось значного прориву поки не досягнуто. Наприклад, згадаємо ШІ-чатбот під назвою Lucie, який отримав підтримку французького уряду, але був закритий через значні недоліки.
Як згадувалось вище, більшість мовних моделей, включно з Llama від Meta, тренуються переважно на англомовних даних, що впливає на якість відповідей іншими мовами. Для розробки української мовної моделі необхідно буде розв’язувати питання збору якісних україномовних даних. Найкращі мовні моделі тренуються на величезних масивах текстових даних.
Для створення якісної української LLM потрібен корпус (В лінгвістиці — підібрана й оброблена за певними правилами сукупність текстів, які використовують як базу для дослідження мови.) текстів розміром у сотні мільярдів слів. Також важливо забезпечити високу якість даних, які включатимуть сучасну літературну, наукову, технічну та розмовну українську мову. Чи вистачить анонсованих Мінцифри даних? Побачимо наприкінці 2025-го.
Експертна думка від Андрія Никоненко — Manager, Machine Learning & Data Science в Turnitin
«Українських текстових даних об’єктивно мало для повноцінного тренування великої мовної моделі. Навіть Llama-2 від Meta була натренована переважно на англомовних корпусах, де частка української була мізерною».

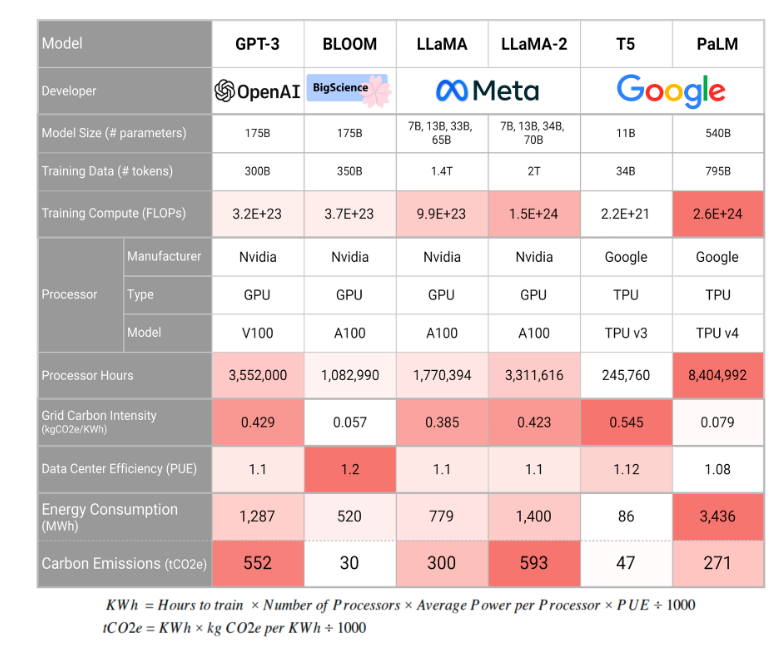
Створення повноцінної української мовної моделі рівня ChatGPT — складне завдання, що вимагає значних ресурсів у кількох ключових напрямках. Щоб навчити велику мовну модель (LLM), необхідні тисячі високопродуктивних GPU або TPU, оптимізованих для ШІ-обчислень. Великі американські компанії, такі як OpenAI чи Google, використовують понад 25 000 графічних процесорів Nvidia для навчання своїх моделей. Саме з цієї причини варто розглянути можливість використання готових моделей із подальшим адаптуванням під українські потреби.
«Великі мовні моделі — не просто алгоритми, а масштабні проєкти, що вимагають інтеграції великої кількості ресурсів. Саме тому навіть великі країни, такі як Німеччина чи Франція, не поспішають створювати власні LLM, а інтегруються у глобальні ініціативи».
Важливо отримати й доступ до багатомовних наборів даних, якщо потрібно, щоб модель могла взаємодіяти й з іншими мовами.
Тож розробка мовної моделі такого рівня вимагатиме комплексного підходу та професійної команди, яка мусить складатись з:
- Комп’ютерних лінгвістів — фахівців, які розуміють структуру української мови та можуть коригувати мовну модель.
- Дата-саєнтистів (data scientists) та інженерів — спеціалістів, які займаються навчанням моделей, оптимізацією обчислювальних процесів та розробкою архітектури ШІ.
- Експертів з етики, бо важливо, щоб мовна модель не була упередженою або некоректною.
На щастя, в Україні є багато спеціалістів та компаній, що займаються штучним інтелектом (AI), машинним навчанням (ML) та обробкою природної мови, наприклад: SoftServe, ELEKS, Neurons Lab, Reface AI та інші.
«Підготовка власного дата-центру під LLM — інвестиція у сотні мільйонів доларів. Головним мотивом створення українського LLM може бути питання безпеки. Проте слід розуміти, що це не лише про тренування моделі, а й про її подальшу підтримку, оновлення та адаптацію. Створення власного дата-центру потребуватиме сотні мільйонів доларів, тоді як співпраця з міжнародними платформами може знизити витрати. Питання безпеки та конфіденційності є критичними: державна модель повинна бути захищена від атак та несанкціонованого доступу».
Українська LLM гарантуватиме національну кібербезпеку та стане рушієм інновацій у сфері ШІ. Власна модель допомогла б використовуватись у державних сервісах та військовій сфері, стимулювала розвиток бізнесів на її основі.
Наприклад, дослідження 2023 року показало, що впровадження штучного інтелекту (ШІ) в фінансовому секторі України може значно підвищити точність звітності та допомогти у подоланні кризових ситуацій. ШІ здатен покращити якість фінансових даних, автоматизувати рутинні завдання, дозволяючи фахівцям зосередитися на стратегічному плануванні. В іншому дослідженні того ж року, науковці підтримали ідею з впровадженням ШІ, оскільки вважають, що у сфері державних фінансів існує чимало проблем, які неможливо вирішити традиційними методами.
Це амбітна, але досяжна мета, яка може стати стратегічним проривом для країни у сфері штучного інтелекту. Реалізація вимагає комплексного підходу, величезних інвестицій та міжнародної співпраці. Не говорячи про питання фізичної безпеки та стабільного енергопостачання. Однак перший і найтяжчий крок вже зроблено. Результати побачимо вже у кінці 2025 року.





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: