Штучний інтелект переживає бум: компанії в різних галузях намагаються впровадити його всюди – від клієнтської підтримки та продажів до аналітики. Один із популярних сценаріїв – автоматизація комунікацій. Тут ШІ може відповідати на дзвінки та повідомлення, допомагати операторам під час розмови або аналізувати якість діалогів. Але є у нього особливість, яка іноді стає серйозним «головним болем» для сервісу – схильність до галюцинацій.
Замість точних відповідей клієнти отримують вигадані факти. Наприклад, робот повідомляє: «Сьогодні ви спілкувалися з нашим менеджером Олегом…», хоча в компанії жодного Олега немає. Хороша новина: галюцинації можна мінімізувати.
Компанія IPTel, що розробляє системи для автоматизації комунікацій, використовує у своїх продуктах різні ШІ‑моделі: від локальних – для простих завдань голосових роботів – до більш гнучких LLM, таких як Gemini, DeepSeek, ChatGPT та Llama, у складних діалогах, ШІ‑помічниках та сервісах мовної аналітики.
У партнерському проєкті CEO IPTel Іван Виноградов розповів, як можна застосовувати ШІ у бізнес-комунікаціях, чому виникають галюцинації та як їх мінімізувати.
Зміст
З чого почати впровадження ШІ‑моделі
Отже, ви прочитали статтю про «успішний успіх» конкурента, який впровадив ШІ, і подумали: «Хочу так само!». Але перше й найважливіше питання – не яку модель обрати, а яку бізнес‑задачу має вирішити ШІ.
Практика показує: на старті краще обрати 1‑2 процеси, де ШІ дасть помітний результат. Це можуть бути операції з передбачуваним сценарієм і обмеженою кількістю можливих відповідей.
Ще один критерій, що спрощує вибір і впровадження: процес має бути описаний – у вигляді скрипта або регламенту. ШІ гірше працює там, де процеси не формалізовані.
У комунікаціях із клієнтами впровадження ШІ часто починають з обробки повторюваних запитань. Це робить голосовий робот, який відповідає на дзвінки або, у зв’язці з системою автообзвону, здійснює вихідні дзвінки. У нього «під капотом» локальна LLM‑модель із жорсткими інструкціями: вона формує репліки в межах сценарію – вітає клієнта на ім’я, розповідає про послуги компанії та відповідає на запитання типу «Які умови розстрочки?» або «Коли буде доставлено замовлення?».

Є й складніші сценарії, де голосовий робот повинен самостійно обирати, як взаємодіяти з клієнтом і що запропонувати. Один із прикладів – м’яке нагадування про заборгованість (soft-collection) у фінансовому секторі або на комунальних підприємствах. Система може вести діалог за кількома траєкторіями: розповісти про різні варіанти оплати чи реструктуризації, або зафіксувати відмову та обрати наступний крок сценарію.
Однак ШІ можна використовувати не лише для автоматизації спілкування з клієнтом, а й для допомоги оператору. У таких сценаріях він працює з контекстом розмови та даними з внутрішніх систем, але не веде діалог напряму.
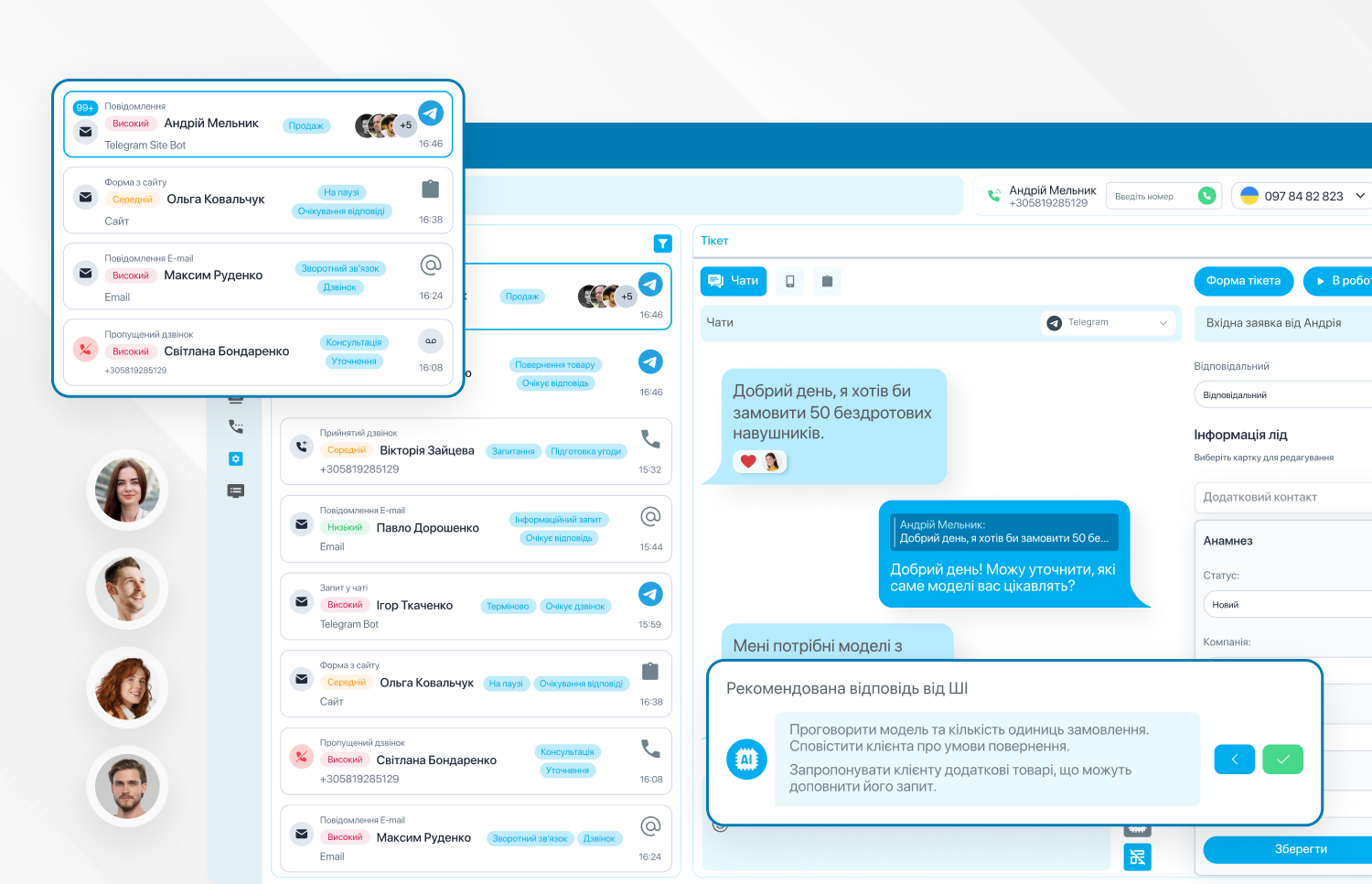
Під час спілкування з клієнтом модель аналізує розмову або переписку та підказує оператору, що потрібно уточнити або який наступний крок передбачений сценарієм. Крім того, оператор сам може звернутися до ШІ‑помічника через діалогове вікно та поставити запитання під час розмови. У відповідь модель миттєво надає інформацію з корпоративної бази знань. Таке використання ШІ має попит у сферах з великим обсягом інформації, наприклад, у медицині, де оператор має швидко відповісти клієнту, як підготуватися до процедури або які існують протипоказання.
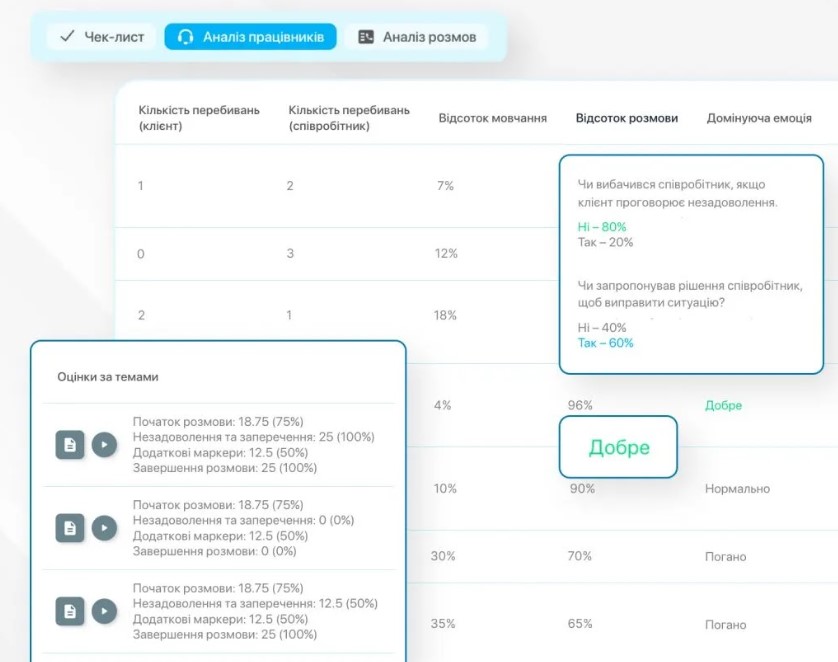
Ще один тип завдань – аналіз якості комунікації. Тут ШІ розшифровує записи дзвінків, розділяє ролі «клієнт/співробітник», відмічає ключові слова, до прикладу, згадки конкурентів, фіксує скарги та аналізує емоції. Це дозволяє швидко виявляти проблеми без прослуховування розмов, що особливо актуально для сфери електронної комерції, де якість сервісу впливає на продажі.
Як обрати модель: досвід IPTel
Вибір моделі залежить від того, яку швидкість обробки, точність і складність діалогу вимагає ваша задача.
- У завданнях, де діалог вписується в заздалегідь описану логіку, а затримки неприпустимі, ключовим фактором вибору є швидкість відповіді. Тут підходять моделі, оптимізовані для роботи в реальному часі. У голосових роботах IPTel, які відповідають на поширені питання, ми використовуємо моделі класу Gemini Flash, DeepSeek Lite або локально розгорнуті версії Llama 3.x (8-13B). Вони працюють у межах суворих інструкцій і формують відповіді за заданими правилами з мінімальною затримкою, що ідеально підходить для дзвінків.
- Складні сценарії, де однієї правильної відповіді недостатньо, потребують моделей, які враховують контекст розмови та на його основі обирають наступний крок. У голосових роботах, які підтримують діалог, ми використовуємо моделі на кшталт Gemini, DeepSeek або актуальні версії ChatGPT. Вони дозволяють будувати діалог не за жорстким скриптом, а в межах заданих патернів спілкування.
- В аналітичних завданнях для оцінки якості комунікації на перший план виходять стабільність і здатність обробляти великі обсяги даних. У сервісі мовної аналітики IPTel ми використовуємо декілька технологій. Для перетворення аудіо в текст – мовні моделі Whisper або Wav2Vec2. Розподіл ролей у діалозі виконується за допомогою PyAnnote. Далі до обробки підключаються мовні моделі, які працюють із готовим текстом: формують резюме розмови та виділяють сигнали для бізнесу. Для цього використовуються LLM, такі як DeepSeek, Gemini або Llama.

Причини галюцинацій
Одного разу під час розмови з клієнтом наш голосовий робот раптово перемкнувся на китайську мову. Але більш дивовижною виявилася реакція клієнта: він знав китайську і спокійно продовжив діалог. Звичайно, ймовірність того, що при наступній такій галюцинації нам пощастило б натрапити на поліглота, мінімальна. Ми розв’язали проблему спеціалізацією промпта – скоригували інструкції для нейромережі, щоб вона використовувала лише дві мови.
За нашими спостереженнями, приблизно у 70% випадків причиною «фантазій» ШІ є повторювані патерни в промптах і даних. Уявіть базу даних із 20 старих FAQ, у кожному з яких є фраза «термін розгляду – 3 дні». ШІ зациклюється на цьому і надалі на будь-яке запитання клієнта щодо термінів починає відповідати «3 дні».
Яскрава ознака того, що база даних має прогалини, – ШІ починає вигадувати. Людина ставить запитання роботу, а дані про те, як відповідати, не завантажили в базу. Тоді нейромережа вигадує відповідь, щоб підтримати розмову. Та сама проблема виникає, якщо в даних є шум, суперечності або застаріла інформація.
Приблизно у 20% випадків причиною галюцинацій стає оновлення моделей. Технічно ШІ може відповідати швидше, але точність відповідей знижується: до оновлення бот казав «не знаю, уточню в базі», коли сумнівався у відповіді, після оновлення – впевнено «додумує».
Як боротися з проблемою
Ми розглядаємо галюцинації не як поодинокі помилки моделі, а як системний ризик, який потрібно знижувати на рівні архітектури. На практиці найбільш ефективними виявилися такі підходи:
- RAG-архітектура з принципом «відповідати лише на основі контексту». Спершу система підбирає релевантні фрагменти з корпоративної бази знань і лише потім передає їх моделі для генерації відповіді. В результаті відповідь складається з конкретних фактів, які можна перевірити. У продуктах IPTel цей принцип закладено у роботі голосових роботів: модель відповідає лише на основі даних, переданих їй системою.
- Суворі системні інструкції та формати відповідей. Навіть при роботі з заданим контекстом ризик галюцинацій зберігається, якщо модель отримує надто велику свободу у формуванні відповіді. Чіткі правила поведінки моделі – що «дозволено», що «заборонено» і як діяти при нестачі даних – знижують цей ризик. У продуктах IPTel такі інструкції доповнюються суворими форматами виводу, наприклад JSON з валідацією.
- Перевірка відповідей. Одразу після генерації відповіді модель порівнює її з альтернативними варіантами та відомими даними й розраховує показник впевненості. Якщо він нижчий за заданий поріг, відповідь не публікується автоматично, а передається оператору або QA-спеціалісту для перевірки. Людина може підтвердити коректність відповіді, внести правки або доповнити базу знань. Ми застосовуємо такий підхід у голосових роботах та ШІ-помічниках. Це дозволяє відсівати сумнівні відповіді до того, як вони вплинуть на клієнта чи бізнес-процеси.
- Double-check за допомогою другої моделі. Різні моделі помиляються по-різному, але якщо відповіді збігаються, ризик помилки нижчий. Тому ми використовуємо додаткову модель для перевірки фактів, чисел і відповідності контексту.
- Єдина структура транскрипцій та метаданих. Якщо вони передаються моделі в різних форматах, їй доводиться самостійно інтерпретувати структуру, що підвищує ризик помилок. У продуктах IPTel ми використовуємо єдину структуру з фіксованими полями та однозначною логікою, щоб формати були однорідними. Це знижує шум, спрощує валідацію і робить поведінку моделі більш стабільною.
Окрім цього, ми ведемо реєстр галюцинацій, де фіксуємо всі проблемні кейси: чого бракувало в даних, де були суперечності, а де модель вийшла за межі інструкцій. Це дозволяє відстежувати повторювані помилки та покращувати рішення.
Боротьба з галюцинаціями – це безперервний процес. Моделі оновлюються, архітектура потребує постійної адаптації, а ШІ – інвестицій. Якщо у вас є сильна команда та час, ви зможете самостійно запобігати галюцинаціям, комбінуючи архітектурні рішення, процеси перевірки та участь людини.
Якщо важливіші швидкість і передбачуваність – простіше покластися на підрядника з досвідом впровадження ШІ в бізнес-процеси, ніж винаходити все з нуля. Тоді це перестає бути дорогим експериментом і стає інструментом для зростання бізнесу.
Над текстом працювали: Анастасія Пономарьова, Альона Лебедєва
Повідомити про помилку
Текст, який буде надіслано нашим редакторам: