

Нове дослідження виявило обмеження сучасних генеративних моделей штучного інтелекту, таких як ChatGPT чи Midjourney. Моделі, які навчаються на даних, згенерованих ШІ, тексти або зображення, мають тенденцію «божеволіти» після п’яти циклів навчання. Зображення вище показує наочний результат таких експериментів.
MAD (Model Autophagy Disorder) – абревіатура, що використовується дослідниками Райс та Стенфордського університету для опису того, як якість видачі моделей ШІ деградує при багаторазовому навчанні на даних, згенерованих ШІ. Як випливає з назви, модель «поїдає сама себе». Він втрачає інформацію про «хвости» (крайні точки) вихідного розподілу даних і починає виводити результати, які більше відповідають середньому представленню.
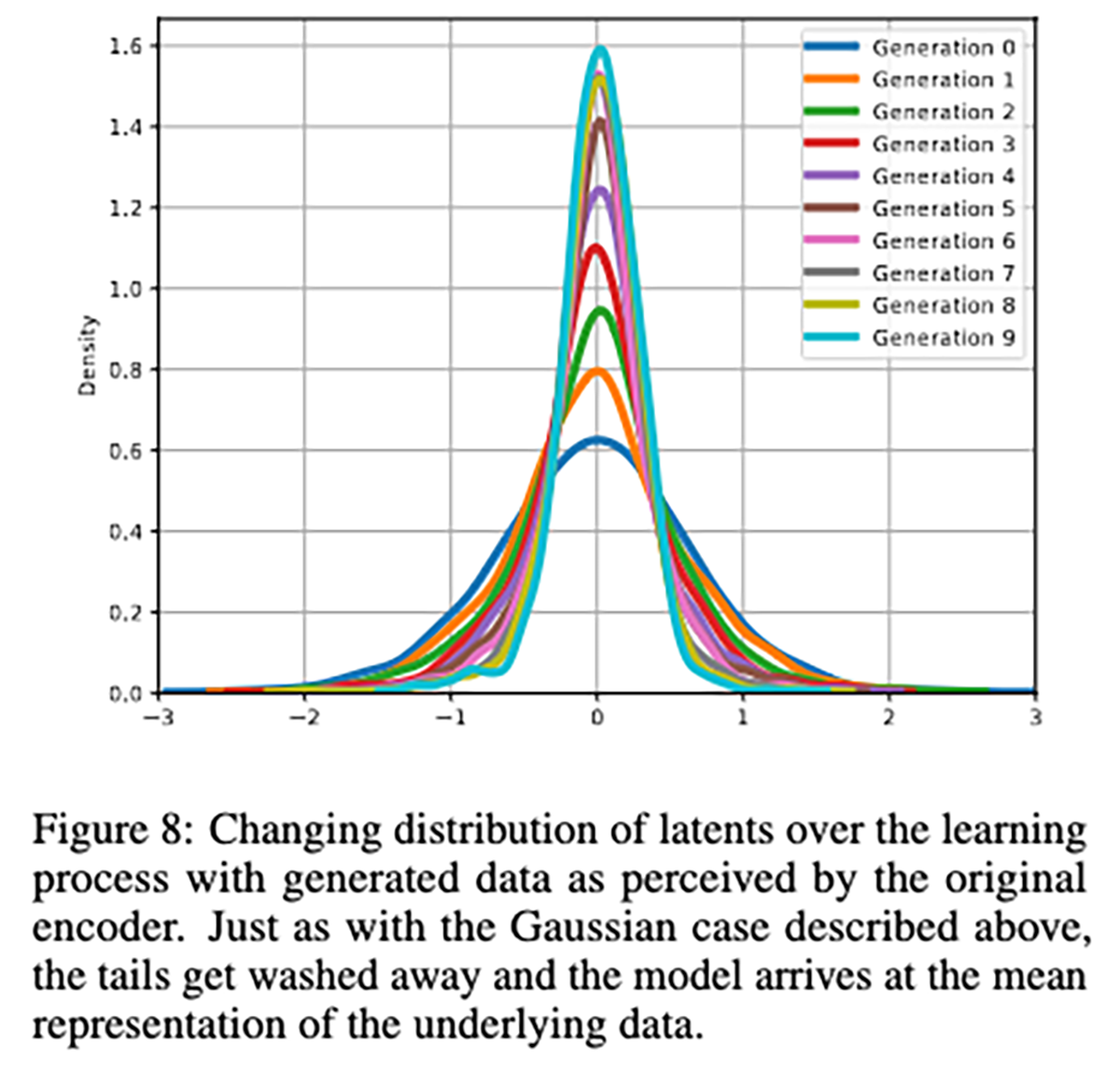
Навчання LLM (великих мовних моделей) на власних (або аналогічних) результатах створює ефект конвергенції. Це легко побачити на наведеному вище графіку, яким поділився член дослідницької групи Ніколас Пейпернот. Послідовні ітерації навчання на даних, згенерованих LLM, призводять до того, що модель поступово (але досить різко) втрачає доступ до даних, які лежать на периферії графіка.
Дані на краях спектра (те, що має менше варіацій і менш представлене) практично зникають. Через це дані, що залишаються у моделі, тепер менш різноманітні та регресують до середнього значення. Згідно з результатами, потрібно близько п’яти ітерацій, допоки «хвости» вихідного розподілу не зникнуть.
Не підтверджено, що така аутофагія впливає на всі моделі ШІ, але дослідники перевірили його на автокодувальниках, змішаних моделях Гауса та великих мовних моделях. Всі вони широко поширені та працюють у різних сферах: передбачають популярність, обробляють статистику, стискають, обробляють та генерують зображення.
Дослідження говорить, що ми не маємо справу з нескінченним джерелом генерації даних: не можна необмежено отримувати їх, навчивши модель один раз і далі ґрунтуючись на її власних результатах. Якщо модель, що отримала комерційне використання, насправді була навчена на власних вихідних даних, то ця модель, ймовірно, регресувала до середнього значення і є упередженою, тому що не враховує дані, які були б у меншості.
Ще одним важливим моментом, висунутим результатами, є проблема походження даних: тепер стає ще важливішим мати можливість відокремити «вихідні» дані від «штучних». Якщо ви не можете визначити, які дані були створені LLM або програмою для створення зображень, ви можете випадково включити їх у навчальні дані для свого продукту.
На жаль, цей «поїзд» багато в чому пішов: існує ненульова кількість немаркованих даних, які вже були створені цими типами мереж і включені в інші системи. Дані, створені ШІ, стрімко поширюються, і 100% способу відрізнити їх немає, тим більше для самих ШІ.
GPT-4 вивчає логіку GPT-2 у дослідженні OpenAI: творці штучного інтелекту не знають, як він працює
Джерело: Tom’s Hardware





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: