

Китайський стартап штучного інтелекту MiniMax відомий реалістичною генеративною моделлю відео Hailuo. Його LLM для програмування MiniMax-M1 вільна для комерційного використання.
MiniMax-M1 з відкритим вихідним кодом розповсюджується з ліцензією Apache 2.0. Це означає, що компанії можуть використовувати її для комерційних застосувань та модифікувати на свій смак без обмежень чи платні. Модель відкритої ваги доступна на Hugging Face та у Microsoft GitHub.
MiniMax-M1 вирізняється контекстним вікном з 1 млн вхідних токенів та до 80 тис. токенів на виході, що робить одною з найширших моделей для завдань контекстного мислення. Для порівняння, GPT-4o від OpenAI має контекстне вікно лише 128 000 токенів. Цього достатньо для обміну інформацією обсягом приблизно як літературний роман за одну взаємодію. З 1 млн токенів MiniMax-M1 може обмінятися інформацією обсягом невеликої колекції книг. Google Gemini 2.5 Pro також пропонує верхню межу контексту токенів у 1 млн, у розробці знаходиться вікно на 2 млн.
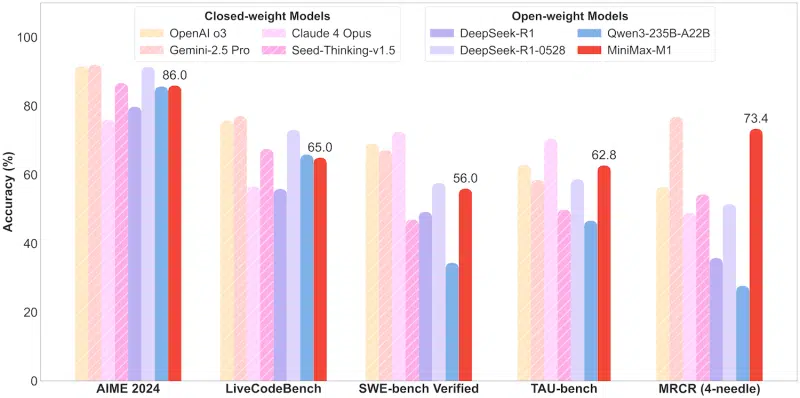
Згідно з технічним звітом, MiniMax-M1 потребує лише 25% операцій FLOP, необхідних DeepSeek R1 під час генерації 100 000 токенів. Модель випускається у варіантах MiniMax-M1-40k та MiniMax-M1-80k, з різним розміром виходу. Архітектура побудована на основі попередньої платформи, MiniMax-Text-01 та включає 456 мільярдів параметрів, з яких 45,9 мільярда активні для одного токена.
Навчання моделі M1 здійснювалося за допомогою інноваційної та високоефективної методики. Це гібридної суміші експертів (MoE) з механізмом блискавичної уваги, розробленим для зменшення витрат на висновок. Вартість навчання склала лише $534 700. Така ефективність пояснюється спеціалізованим алгоритмом CISPO, який обрізає ваги вибірки важливості, а не оновлення токенів, а також гібридною конструкцією уваги, яка допомагає оптимізувати масштабування. Для порівняння, навчання DeepSeek R1 коштувало $5,6 млн (хоча у цьому є сумніви), тоді як вартість навчання GPT-4 від OpenAI за оцінками перевищує $100 млн.
Day 1/5 of #MiniMaxWeek: We’re open-sourcing MiniMax-M1, our latest LLM — setting new standards in long-context reasoning.
– World’s longest context window: 1M-token input, 80k-token output
– State-of-the-art agentic use among open-source models
– RL at unmatched efficiency:… pic.twitter.com/bGfDlZA54n— MiniMax (official) (@MiniMax__AI) June 16, 2025
Це перший реліз у серії MiniMaxWeek, про яку компанія оголосила в X. Вочевидь, користувачів очікує п’ять днів захопливих анонсів.
Джерело: VentureBeat





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: