

Исследователи компании DeepSeek представили новую экспериментальную модель V3.2-exp, созданную для существенного снижения затрат на вывод при работе с большими объемами контекста. Анонс появился на платформе Hugging Face, а также выложили связанную научную статью с описанием системы на GitHub.
Ключевой особенностью новой модели является система DeepSeek Sparse Attention, сложный механизм, подробно показанный в схеме ниже. Суть в том, что используется модуль под названием «скоростной индексатор», который приоритезирует отдельные фрагменты окна контекста. После этого другая подсистема — «система точного отбора токенов» — отбирает конкретные токены из этих фрагментов для загрузки в ограниченное окно внимания модуля. В сочетании эти механизмы позволяют моделям Sparse Attention эффективно работать с большими фрагментами контекста при относительно небольшой нагрузке на серверы.
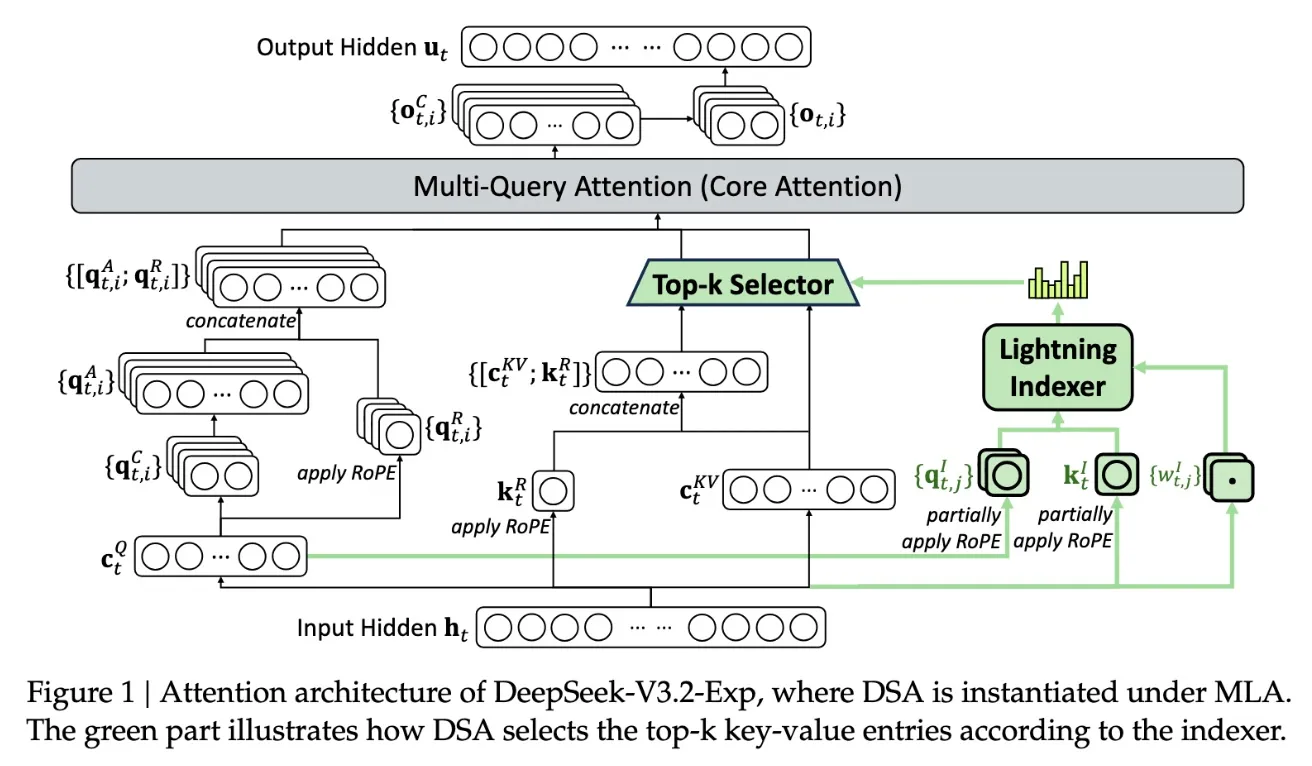
В длинноконтекстных задачах преимущества такого подхода особенно заметны. Предварительное тестирование DeepSeek показало, что цена обычного API-запроса может сокращаться почти вдвое, когда речь идет о работе с большим контекстом. Хотя для получения окончательных выводов требуются дальнейшие исследования, открытость весов модели и ее доступность на Hugging Face позволят сторонним экспертам быстро проверить заявленные результаты.
Новая модель DeepSeek является частью ряда прорывов в сфере оптимизации стоимости вывода — то есть затрат на работу уже натренированной ИИ-модели, что отличается от высоких затрат на этапе ее обучения. В этом случае исследователи стремились заставить базовую трансформерную архитектуру работать эффективнее, и, по их словам, потенциал для улучшения здесь действительно значителен.
Компания DeepSeek, базирующаяся в Китае, имеет особое положение на рынке ИИ, особенно на фоне восприятия этой отрасли как конкурентной борьбы между США и Китаем. В начале года компания привлекла внимание к себе моделью R1 (которая собирает множество данных пользователя и искажает информацию о Китае), обученной преимущественно с помощью методов обучения с подкреплением и при этом с гораздо меньшими затратами, чем у американских конкурентов. Впрочем, ожидаемого прорыва в методах обучения R1 не вызвала, и за последние месяцы DeepSeek отошла от всеобщего внимания.
Новый подход Sparse Attention, скорее всего, не вызовет такого же ажиотажа, как R1. Но он может стать важным уроком для американских компаний, которые пытаются снизить затраты на вывод и сделать работу своих моделей более экономной.
Источник: techcrunch





Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: