

За кілька днів до презентації нового покоління RTX 5000 серії на CES 2025, згадаємо попередні флагмани двох поколінь відеокарт: Nvidia RTX 3090 (Ti) та RTX 4090. Спочатку подивимось на SM блоки кожної генерації і перейдемо до самих чіпів GA102 (Ampere, RTX 3090 (Ti)) та AD102 (Ada, RTX 4090). Подивимось на нові технології в 4000 серії, порівняємо теоретичну продуктивність та ігри на обох поколіннях відеокарт.
Зміст
- 1 Streaming Multiprocessor (SM) блок GA10x (Ampere, RTX 3000)
- 2 GPU GA102 (Ampere, RTX 3000)
- 3 Streaming Multiprocessor (SM) блок AD10x (Ada, RTX 4000)
- 4 GPU AD102 (Ada, RTX 4000)
- 5 Порівняння підсистеми пам’яті двох поколінь
- 6 Новий технологічний процес
- 7 Різниця між Ray Tracing Cores в Ampere та Ada
- 8 Opacity Micromap Engine
- 9 Displaced Micro-Mesh (DMM)
- 10 Shader Execution Reordering (SER)
- 11 DLSS 3 та Optical Flow Acceleration
- 12 Таблиця порівняння RTX 4090 та RTX 3090 Ti
- 13 А як справи в іграх?
- 14 Висновок
Streaming Multiprocessor (SM) блок GA10x (Ampere, RTX 3000)
Трішки теорії не завадить для початку :)
Потоковий мультипроцесор (SM) — це фундаментальний компонент графічних процесорів NVIDIA, що складається з кількох потокових процесорів (CUDA Core), відповідальних за паралельне виконання інструкцій.
Це, скажімо так, базове визначення. Проте з виходом поколінь Volta та Turing, Nvidia додала ще 2 компоненти до SM блоків – Tensor Cores (Тензорні ядра) та Ray Tracing Cores (Трасування променів).
Tensor Cores (Тензорні ядра) — це спеціалізовані виконавчі блоки, розроблені спеціально для виконання тензорних/матричних операцій, які є основною обчислювальною функцією, що використовується в Deep Learning.
Тензорні ядра прискорюють множення матриці на матрицю, що є основою навчання нейронної мережі та функцій логічного висновку. Обчислення логічного висновку є основою більшості графічних програм на основі штучного інтелекту, у яких корисну та релевантну інформацію можна отримати та надати навченою глибокою нейронною мережею (DNN) на основі заданих вхідних даних. Приклади висновків включають покращення якості графіки за допомогою DLSS (Deep Learning Super Sampling), усунення шумів на основі AI, видалення фонового шуму голосових чатів у грі за допомогою RTX Voice, ефекти зеленого екрана на основі AI у механізмі NVIDIA RTX Broadcast, генерація зображень та багато іншого.
Ray Tracing Cores (Ядра Трасування променів, RT) — це прискорювачі, призначені для виконання операцій трасування променів із надзвичайною ефективністю.
Ці RT ядра дозволяють художникам використовувати візуалізацію з трасуванням променів для створення фотореалістичних об’єктів і середовищ із фізично точним освітленням. Проте ми повернемося до SM.
На Зображені №1 нижче, ви можете побачити структуру SM блоку покоління Ampere. GA10x SM розділений на чотири розділи обробки, кожен з яких має реєстровий файл розміром 64 КБ, кеш інструкцій L0, один планувальник деформації, один блок диспетчеризації, а також набори математичних та інших блоків.
Кожен SM у графічних процесорах GA10x містить: 128 ядер CUDA, чотири Тензорних Ядра (Tensor Cores) 3-ого покоління, Файл Реєстру розміром 256 КБ, чотири Блоки Текстур (Texture Units), одне Ядро Трасування Променів (RT Core) 2-ого покоління та 128 КБ L1 / підсистему спільної пам’яті (Shared Memory Subsystem).

Зображення №1. SM архітектури Ampere. Автор: Nvidia.
GPU GA102 (Ampere, RTX 3000)
Однак, SM блоки – це лише маленька частина айсберга. На повний графічний процесор GA102 RTX 3090 / RTX 3090 Ti ви можете подивитися на Зображені №2.
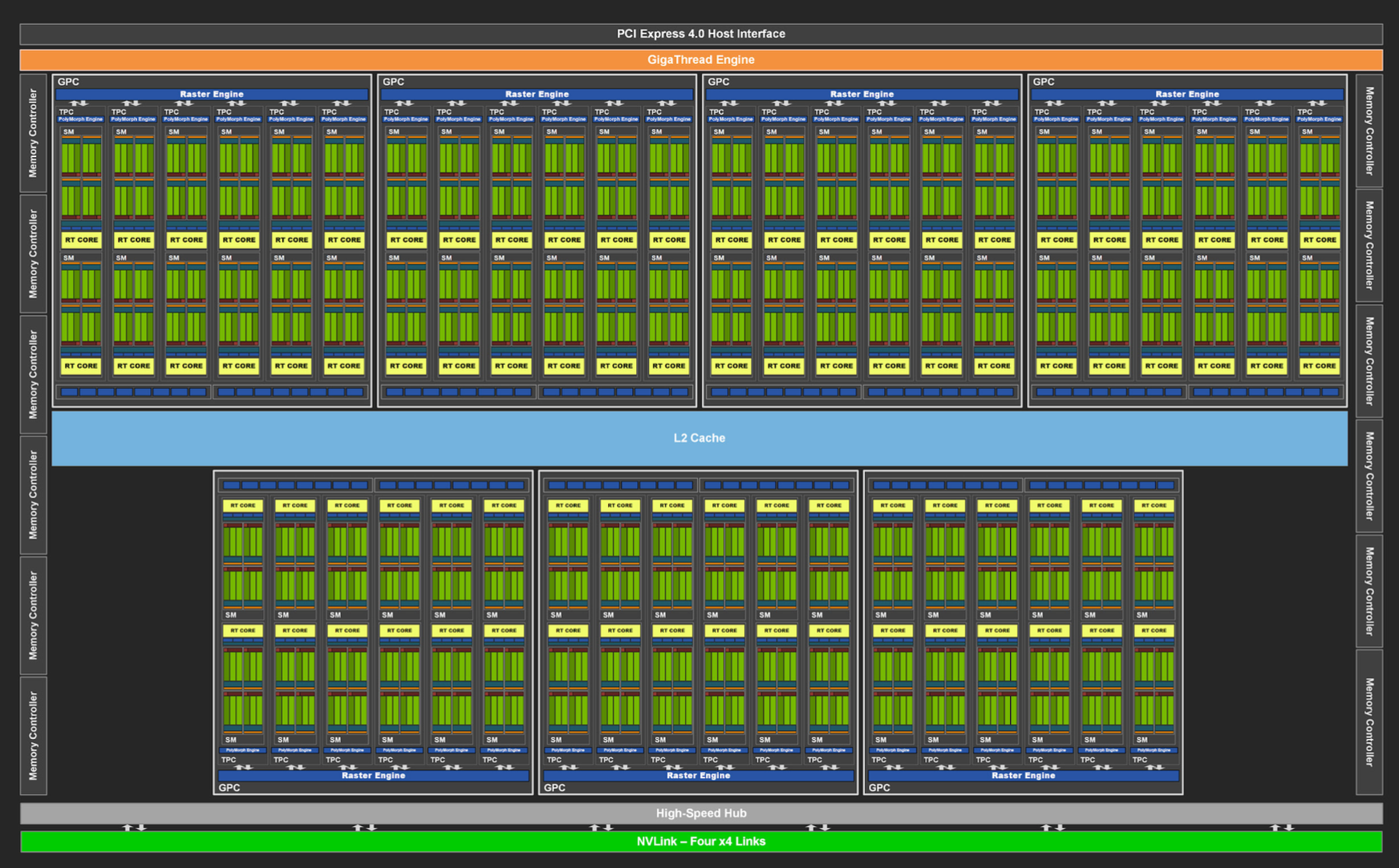
Зображення №2. GPU GA102. Автор: Nvidia.
Як і попередні графічні процесори NVIDIA, GA102 складається з Кластерів Обробки Графіки (Graphics Processing Clusters, GPC), Кластерів Обробки Текстур (Texture Processing Clusters, TPC), Потокових Мультипроцесорів (Streaming Multiprocessor, SM, вже познайомились), Растрових Операторів (Raster Operators, ROPS) і контролерів пам’яті. Повний GPU GA102 містить 7 GPC, 42 TPC та 84 SM.
Відеопроцесор GA102 (саме у RTX 3090 Ti такий і стоїть) включає в себе:
- 10752 ядер CUDA;
- 84 ядра RT;
- 336 тензорних ядер;
- 336 текстурних одиниць;
GPC є домінуючим апаратним блоком високого рівня з усіма ключовими графічними процесорами, які знаходяться всередині GPC. Кожен GPC містить спеціальний Raster Engine, а тепер також містить два розділи ROP (загалом, в одному GPC міститься вісім блоків ROP), що є новою функцією для графічних процесорів NVIDIA Ampere Architecture GA10х. GPC включає шість TPC, кожен з яких містить два SM та один PolyMorph Engine.
Деякі особливо уважні могли задатися 1 питанням: А чому не вставити «знизу» ще хоча б 1 SM блок? Подивитесь далі на GPU AD102. Проте спочатку…
Streaming Multiprocessor (SM) блок AD10x (Ada, RTX 4000)
Проте спочатку подивимося на Зображення №3 і спробуйте візуально знайти різницю з попереднім поколінням. Різниці, м’яко кажучи, не так і багато.
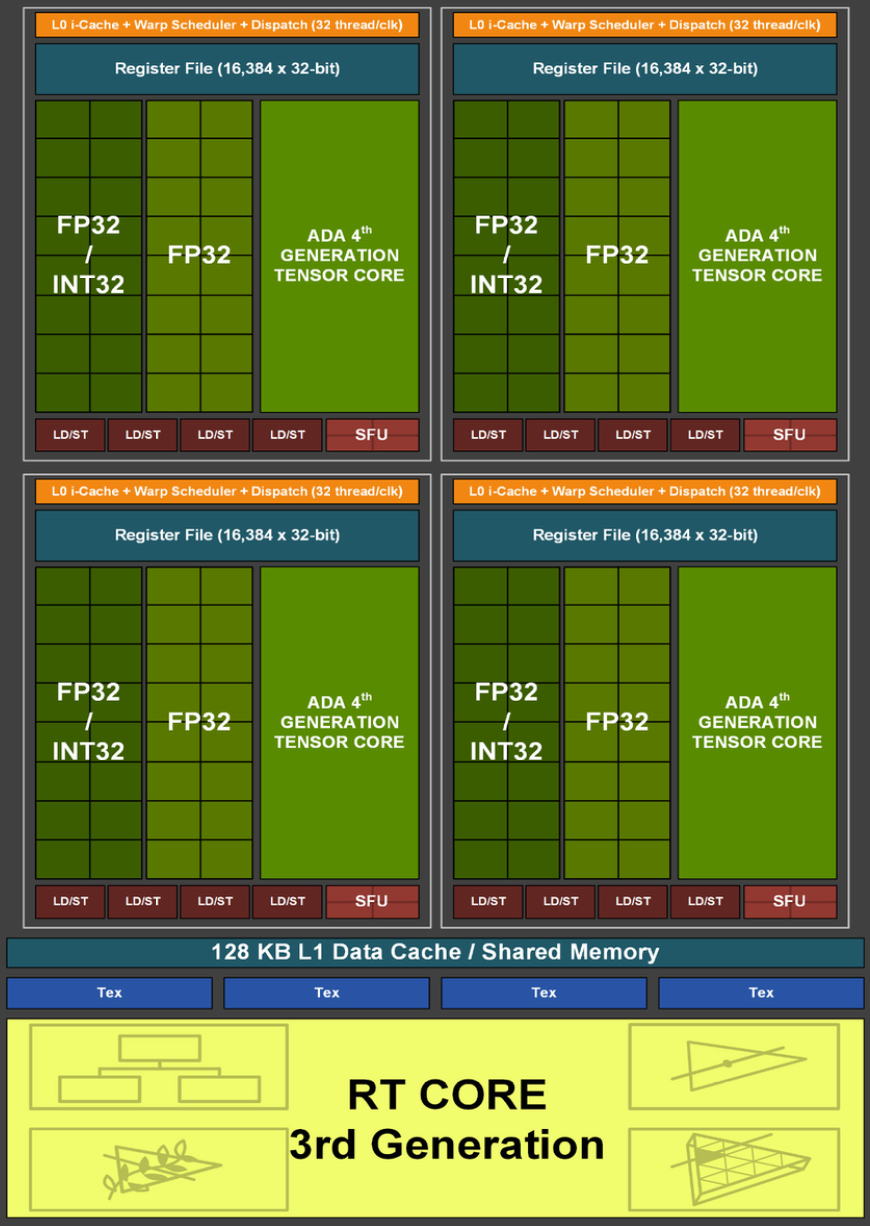
Зображення №3. SM архітектури Ada. Автор: Nvidia.
Кожен SM у графічних процесорах AD10x складається з: 128 ядер CUDA, одне Ядро Трасування Променів (Ray Tracing Core) Ada 3-го покоління, чотири Тензорних Ядра (Tensor Cores) Ada 4-го покоління, чотири Блоки Текстур (Texture Units), Файл Реєстру розміром 256 КБ і 128 КБ L1 / Підсистему Спільної Пам’яті (Shared Memory Subsystem).
І як ви могли самостійно порівняти – різниці майже не видно. Проте вона все ж є: нові Tensor Cores та RT Cores з новими функціями/можливостями. Грубо кажучи, Nvidia в RTX 4000 більше займалася програмними вдосконаленнями, ніж фізично додавала потужності? Фізично також додала, і багатенько.
GPU AD102 (Ada, RTX 4000)
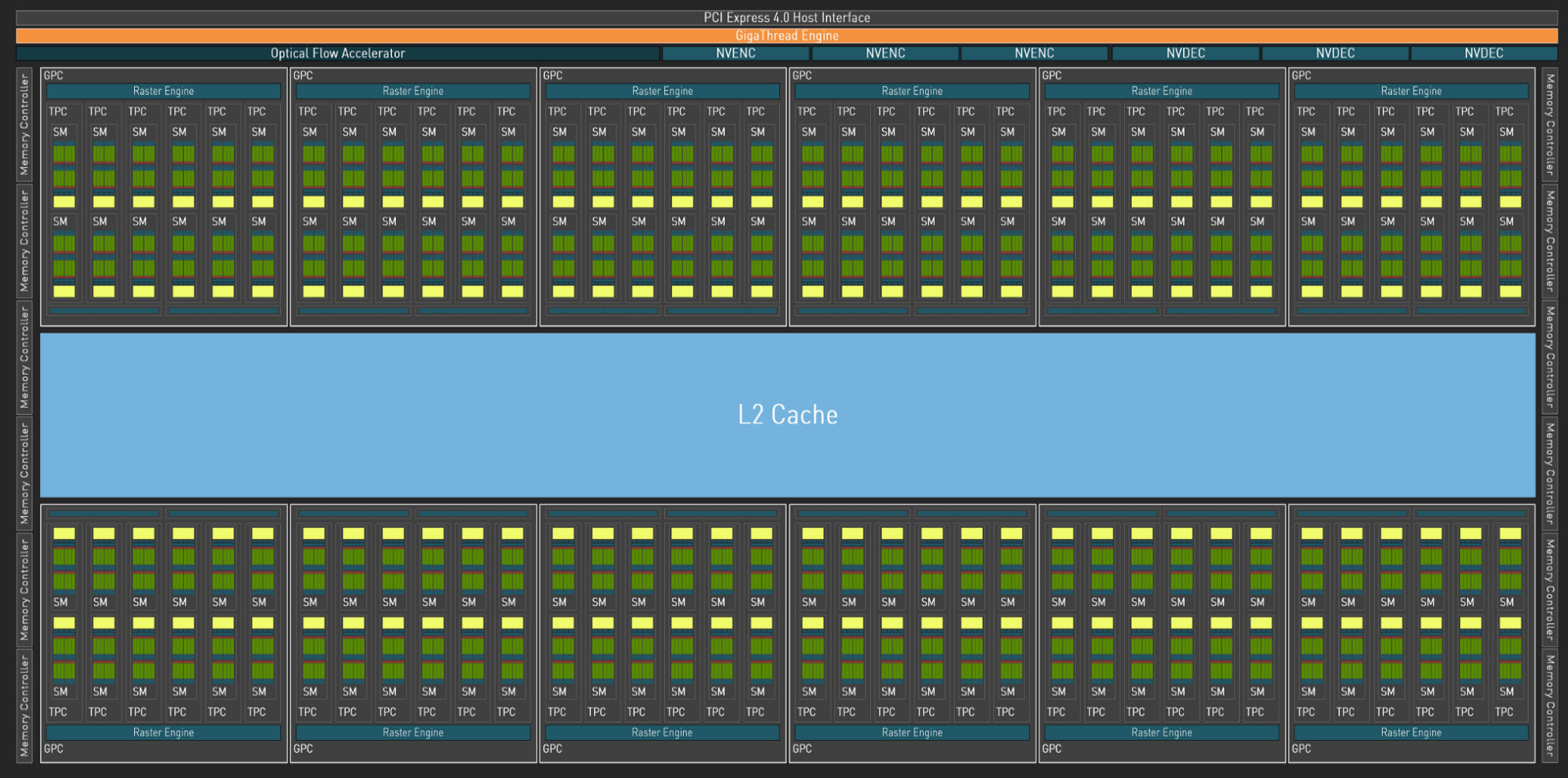
Зображення №4. GPU AD102. Автор: Nvidia.
Повноцінний GPU AD102 включає 12 Кластерів Обробки Графіки (GPC), 72 Кластери Обробки Текстур (TPC), 144 Потокових мультипроцесори (SM) і 384-розрядний інтерфейс пам’яті з 12 32-розрядними контролерами пам’яті. Отже, GPU AD102 містить в собі:
- 18432 ядер CUDA;
- 144 ядра RT;
- 576 тензорних ядер;
- 576 текстурних одиниць;
У RTX 4090 встановлено чіп AD102, проте з одним вимкненим GPC. Саме тому деякі чекали RTX 4090 Ti.
Як і в Ampere, GPC є домінуючим високорівневим апаратним блоком у всіх графічних процесорах сімейства AD10x Ada, при цьому всі ключові графічні процесори знаходяться в GPC. Кожен GPC включає спеціальну Raster Engine, два розділи Raster Operations (ROP), причому кожен розділ містить вісім окремих блоків ROP і шість TPC. Кожен TPC включає один PolyMorph Engine і два SM.
Перейдемо до різниці між Ampere та Ada.
Порівняння підсистеми пам’яті двох поколінь
SM блок в поколінні Ada містить 128 КБ кешу L1. Цей кеш має уніфіковану архітектуру, яку можна налаштувати як кеш даних L1 або Спільну Пам’ять залежно від робочого навантаження. Повний графічний процесор AD102 містить 18432 КБ L1 кешу (у GA102 становить 10752 КБ).
Порівняно з Ampere, L2 кеш Ada був повністю оновлений. AD102 оснащено 98304 КБ кеш-пам’яті L2, що в 16 разів більше, ніж 6144 КБ, які постачалися разом з GA102. Усі програми та ігри виграють від наявності такого об’єму швидкої кеш-пам’яті, а для складних операцій, такі як Трасування Променів (зокрема Трасування Шляху (Path Tracing)), принесе найбільшу користь.
З випуском графічних процесорів GeForce RTX 3090 і 3080 було вперше застосовано відеопам’ять стандарту GDDR6X, які пропонували швидкість до 19,5 Гбіт/с. Через два роки було забезпечено ще більшу швидкість пам’яті для графічних процесорів Ada: GeForce RTX 4080 постачається з пам’яттю 22,4 Гбіт/с GDDR6X; це найвища швидкість серед будь-яких GPU з пам’яттю на основі GDDR. GeForce RTX 4090 пропонує 1 ТБ/с максимальної пропускної здатності пам’яті.
Новий технологічний процес
Графічні процесори Ada виготовляються за технологічним процесом TSMC 4N. За допомогою процесу 4N, NVIDIA змогла розмістити значно більше ядер на кристалі: AD102 містить на 70% більше ядер CUDA, ніж GPU попереднього покоління GA102. Загалом графічний процесор AD102 містить 76,3 мільярда транзисторів, що робить його одним із найскладніших чіпів, коли-небудь створених.
Для тих кому цікаво: Apple M3 Max складається з 92 мільярдів транзисторів.
Відеопроцесори Ada також працюють на високих тактових частотах, порівняно з Ampere. NVIDIA оптимізувала конструкцію графічного процесора, використовуючи високошвидкісні транзистори в критичних шляхах, які інакше могли б обмежити решту чіпа. Працюючи на тактовій частоті GPU Boost 2,52 ГГц, GeForce RTX 4090 постачається з найвищою тактовою частотою будь-якого графічного процесора NVIDIA.
Водночас висока тактова частота та кількість ядер RTX 4090 забезпечують найвищу продуктивність на ват. При роботі з тією ж потужністю, що й RTX 3090 Ti, графічний процесор RTX 4090 забезпечує більш ніж у 2 рази більшу продуктивність.
Для тих, хто не знав – покоління Ampere використовувало 8N від Samsung.
Різниця між Ray Tracing Cores в Ampere та Ada
Порівнюючи Зображення №3 та №4 ви могли помітити, що для RT ядер в поколінні Ada було додано ще 2 “малюнки”. Тепер до попередніх Box Intersection Engine (зліва зверху) та Triangle Intersection Engine (справа зверху) додано ще 2:
- Opacity Micromap Engine – оцінює Непрозорі Мікрокарти (Opacity Micromap), які використовуються для прискорення альфа-обходу;
- Displaced Micro-Mesh Engine – генерує меші/сітки Мікротрикутників, відомих як Displaced Micro-Mesh.
До всього цього, в Ada впроваджується Перевпорядкування Виконання Шейдерів (Shader Execution Reordering, SER). Ця функція інтелектуально планує роботу із затемненням на льоту, щоб ефективніше обробляти складні матеріали, як-от матовий метал.
Тепер перейдемо до кожної технології детальніше.
Opacity Micromap Engine
Розробники часто використовують альфа-канал текстури, щоб економічно вирізати складні форми або, загалом, для представлення напівпрозорості. Листочок дерева можна описати за допомогою пари трикутників, використовуючи альфа-канал текстури для економного захоплення складної форми. Такі характеристики полум’я, як форма та напівпрозорість, також можна приблизно оцінити за допомогою цього параметру.
Раніше розробник міг включати такий вміст у сцену з Трасуванням Променів, позначаючи їх як непрозорі. Коли промінь потрапляє на листок, викликається шейдер, щоб визначити, як обробляти перетин, навіть якщо промінь просто характеризується як попадання або промах. Це спричиняє відчутні витрати продуктивності. Зокрема, коли викривлення променів спрямовується на непрозорі об’єкти, окремі запити променів можуть потребувати кількох викликів шейдерів для вирішення, тоді як інші промені просто зникнуть. Щоб ефективно обробляти такі моменти, NVIDIA додала механізм Opacity Micromap Engine до ядра RT Ada.
Мікрокарта Непрозорості (Opacity Micromap) — це віртуальна меш/сітка мікротрикутників, кожен із яких має параметр Непрозорості, який RT Core використовує для безпосереднього вирішення перетинів променів із непрозорими трикутниками. Зокрема, барицентричні координати перетину використовуються для вирішення параметра непрозорості відповідного мікротрикутника.
Параметр Непрозорості має такі стани, як непрозорий, прозорий або невідомий (якби дивно воно не звучало). Якщо:
- Непрозорий – удар променю записується та повертається;
- Прозорий – удар променю не відбувається і він летить далі в пошуках відбиття;
- Невідомий – RT ядро передає це до керування SM, викликаючи шейдер («anyhit») для програмного вирішення “удару”;
Новий механізм Opacity Micromap Engine оцінює Маску Непрозорості (Opacity Mask), яка є звичайним трикутним мешем/сіткою, визначеною за допомогою барицентричної системи координат, яка використовується для звітування про перетини променів і трикутників. Ці меші/сітки можуть мати розмір від одного до шістнадцяти мільйонів мікротрикутників.
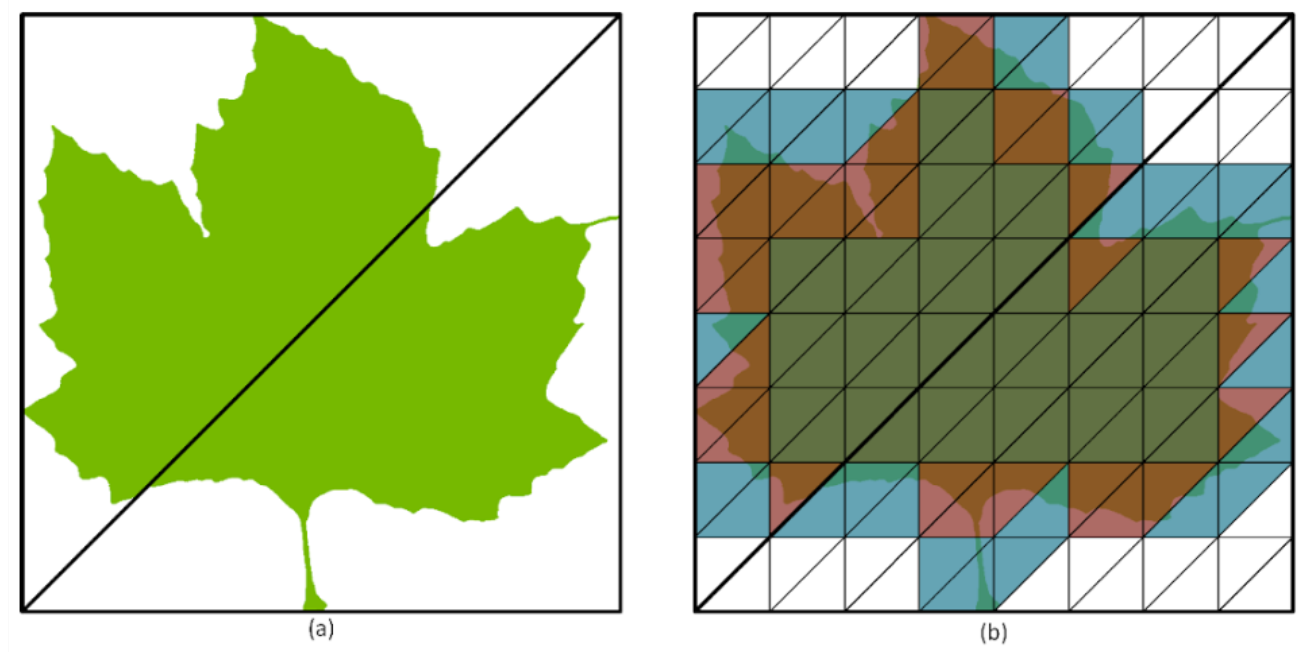
Зображення №5. Два приклади застосування Маски Непрозорості (Opacity Mask). На (b) трикутники мають такі стани: білий (30 штук) – повністю прозорий; темно-зелені (41 штук) – повністю непрозорий; червоні та сині (57 штук) – невідомо. Автор: Nvidia.
Ada RT Core може повністю охарактеризувати ці промені без використання будь-якого шейдерного коду, зберігаючи при цьому повну роздільну здатність і точність оригінальної альфа-текстури. Коли зустрічається невідомий стан, керування повертається шейдеру для вирішення.
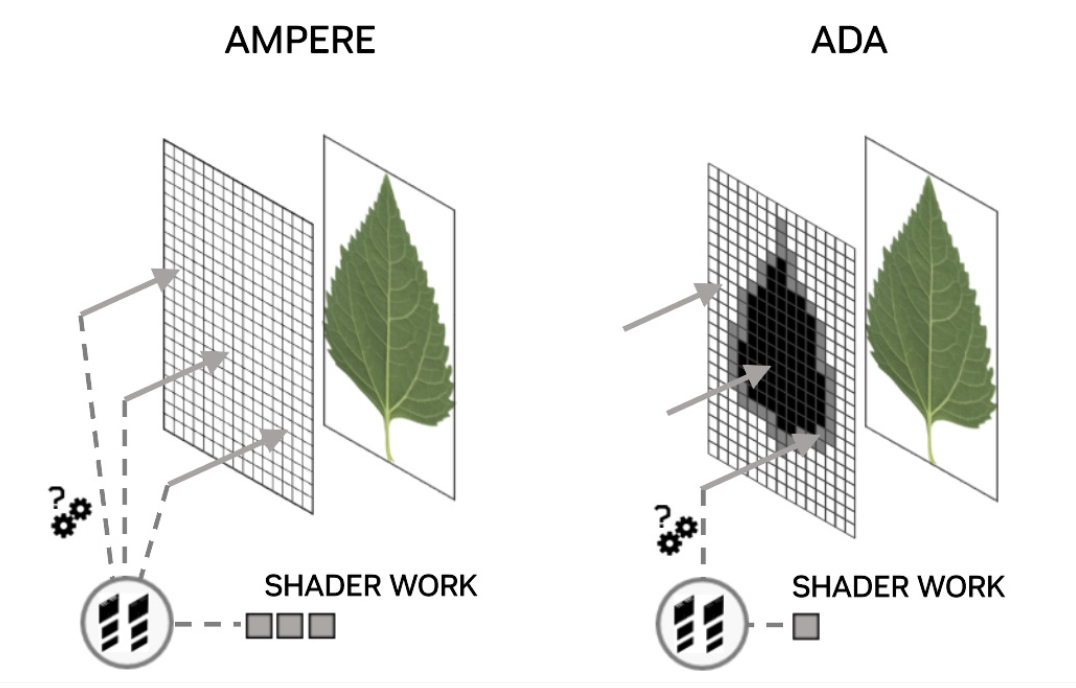
Зображення №6. Порівняння з Ampere. Витрачається менше ресурсів на обробку цього листа. Автор: Nvidia.
З додаванням Opacity Micromap Engine спостерігається подвоєння продуктивності обходу сцени в програмах з альфа-перевіреною геометрією. Підтримка Маски Прозорості в Ada може значно збільшити кількість і точність деталізованої геометрії в межах сцени, піднімаючи планку реалістичності.
Displaced Micro-Mesh (DMM)
Геометрична складність все продовжує зростати з кожним роком, а продуктивність трасування променів добре масштабується зі збільшенням складності сцени. Коли ми трасуємо складні середовища, витрати на трасування зростають повільно: 100-кратне збільшення геометрії може лише подвоїти час трасування. Проте створення структури даних, такої як Ієрархія Обмежувальних Томів (Bounding Volume Hierarchy, BVH) займає дуже багато часу та пам’яті. Збільшення геометрії у 100 разів може означати в 100 разів більше часу на створення BVH. Звісно, пам’яті також знадобиться в 100 разів більше. Нові RT ядра зі Зміщеними Мікромешами (Displaced Micro-Mesh, DMM) суттєво допомагає впоратися з обома проблемами високої геометричної складності – продуктивністю збірки BVH і обсягом пам’яті/сховища. Також зменшуються “тяжкість” асетів та витрати на передачу даних.
Мікромеш (Micro-Mesh) — це новий примітив, який представляє структуровану меш/сітку мікротрикутників, які Ada RT Core обробляє нативно, заощаджуючи зберігання та обробку порівняно з тим, що зазвичай потрібно при описі складних геометрій, використовуючи лише базові трикутники.
Розробники Nvidia розробили зміщену мікромеш як структуроване представлення геометрії, яке використовує просторову когерентність для компактності (стиснення) і використовує її структуру для ефективного рендерингу з внутрішнім рівнем деталізації (Level of Detail, LOD) з легкою анімацією/деформацією. Під час трасування променів використовується зміщена структура мікромешу, щоб уникнути значного збільшення витрат на побудову BVH, зберігаючи при цьому ефективне проходження BVH. Під час растеризації, власна мікромеш LOD перетворюється у примітивів потрібного розміру за допомогою Mesh Shaders або Compute Shaders.
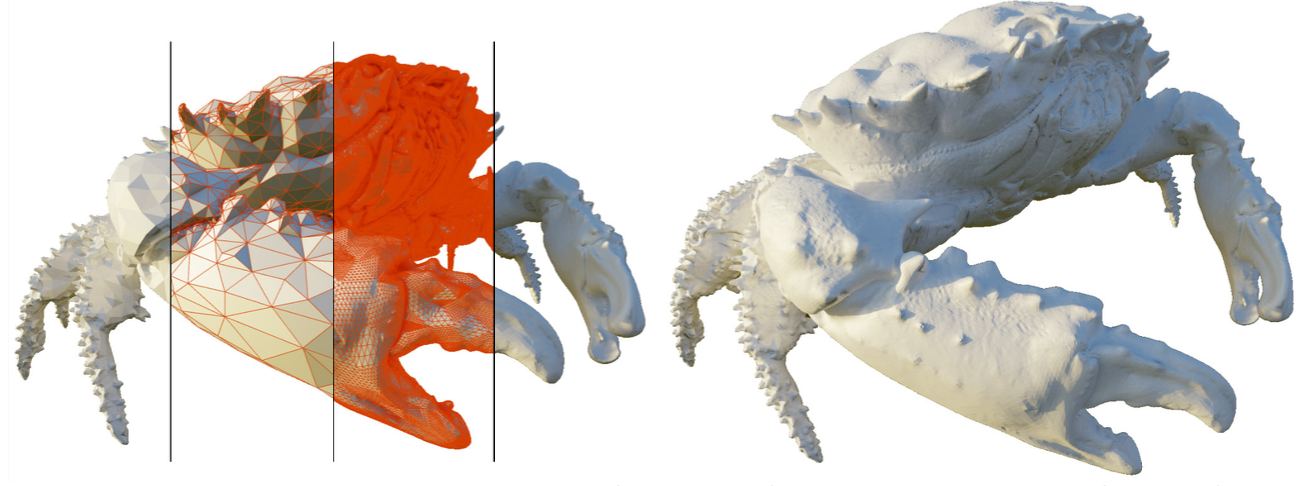
Зображення №7. Displaced Micro-Mesh: Базові (зліва червоні) та мікромеші (справа червоним) та повноцінна модель (справа). Автор: Nvidia.
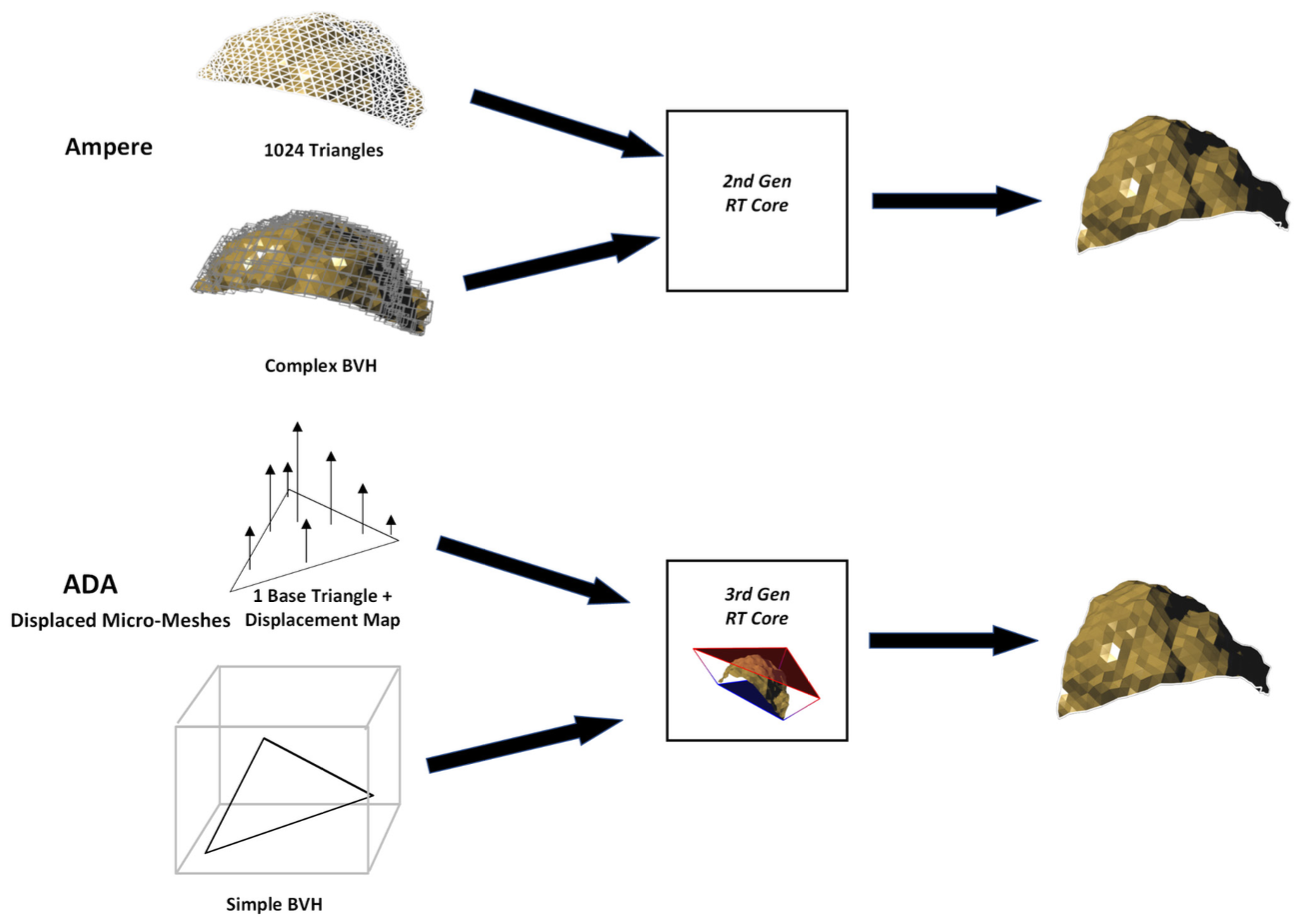
Зображення №8. RT ядро Ada з механізмом Displaced Micro-Mesh використовує простий BVH, 1 базовий трикутник і карту зміщення для створення високодеталізованої геометричної сітки з меншою кількістю необхідних ресурсів, ніж RT ядро Ampere. Автор: Nvidia.

Зображення №9. DMM дозволяє швидше генерувати геометрію та займати менше пам’яті. Автор: Nvidia.
Shader Execution Reordering (SER)
Потужностей RT Core може бути недостатньо для забезпечення високої частоти кадрів при увімкненні Трасування Променів, оскільки робочі навантаження можуть бути обмежені низкою факторів. Зокрема, розбіжні RT-шейдери є одним з таких обмежувачів. Наприклад, під час виконання алгоритмів стохастичного Path Tracing або під час оцінювання складних матеріалів.
Розбіжність має дві форми: розбіжність Виконання, коли різні потоки виконують різні шейдери або код вcередині шейдеру, і розбіжність Даних, коли потоки отримують доступ до ресурсів пам’яті, які важко об’єднати або кешувати. Обидва типи розбіжності виникають природним чином у багатьох сценаріях Трасування Променів. Через це страждає продуктивність, оскільки графічні процесори працюють найефективніше, коли постійно виконується схожа робота.
Перевпорядкування виконання шейдерів (Shader Execution Reordering, SER) — це нова система планування, яка миттєво змінює порядок виконання шейдерів для кращого здійснення та локалізації даних.
Покоління Ada містить нову технологію, призначену для підвищення ефективності виконання шейдерів RT шляхом вирішення проблеми розбіжності. Апаратна архітектура Ada була розроблена з урахуванням SER і включає оптимізації SM і системи пам’яті, спеціально спрямовані на ефективне перевпорядкування потоків.
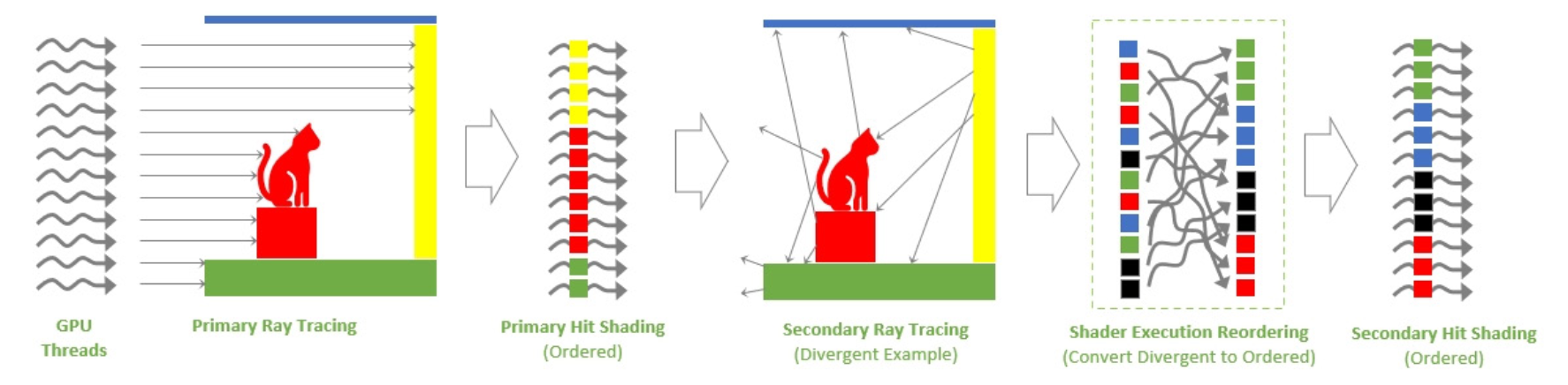
Зображення №10. Розширені методи освітлення, такі як Path Tracing, спричиняють розбіжність шейдерів, оскільки вторинні промені відбиваються від об’єктів у сцені (позначених різними кольорами). У цих сценаріях SER змінює порядок виконання шейдерів для підвищення ефективності. Автор: Nvidia.
Докладніше про Зображення №10. Перші промені, які генерує GPU Threads, є добре впорядкованими через потрапляння на одні і ті ж самі поверхні та запускають однакову програму для обробки шейдерів. Проте потім, промені починають “влучати” у інші об’єкти. Через це починається “хаос” серед потоків. Прикладами створення такого є: Трасування Шляху (Path Tracing), Відбивання (Reflection), Непряме освітлення (Indirect Lighting) та Ефекти Напівпрозорості (Translucency Effects). Робота SER і є розібратися у цьому та впорядкувати.
У грі Cyberpunk 2077 в режимі RT: Overdrive, було зафіксовано приріст продуктивності на 44% за допомоги використання SER.
DLSS 3 та Optical Flow Acceleration
Вже 6 років йде розвиток технології Deep Learning Super Sampling (DLSS). І 2 роки тому Nvidia показала нову по тим часам версію – DLSS 3. На відміну від попередніх версій, які займалися масштабуванням зображення, третє покоління DLSS додає точні синтезовані кадри між кадрами, що існують. Ця технологія збільшує FPS (frames per sec, кадрів/сек) через що покращується плавність зображення.
Взагалі, краще би було написати окрему статтю про DLSS. Все ж таки, вже існує аж 3 покоління (і буде 4). Якщо хочете більше дізнатися про DLSS – ставте “Файно є” вкінці статті. А сьогодні – зовсім трошки про DLSS 3.
Серед звичайних геймерів, такі покращення називають Генератором кадрів. Однак, існує й інша сторона медалі – збільшення Input lag при керуванні в іграх на слабких відеокартах через базову низьку частоту кадрів.
Оцінка Оптичного Потоку (Optical Flow) зазвичай використовується в програмах комп’ютерного зору для вимірювання напрямку та величини видимого руху пікселів між послідовно відтвореними графічними або відеокадрами. У сферах 3D-графіки та відео типові випадки використання включали зменшення затримки в доповненій і віртуальній реальності, покращення плавності відтворення відео, підвищення ефективності стиснення відео та увімкнення стабілізації відеокамери.
Оптичний Потік схожий на компонент оцінки руху при виконанні кодування відео, але з набагато складнішими вимогами до точності та послідовності. Саме тому потрібно використовувати різні алгоритми. Починаючи з архітектури графічного процесора Ampere, GPU мали підтримку автономного Прискорювача Оптичного Потоку (Optical Flow Accelerator, OFA), який застосовує найсучасніші алгоритми для забезпечення високоякісних результатів. Блок OFA в GPU Ada забезпечує 300 TeraOPS (TOPS) роботи Оптичного Потоку (більш ніж у 2 рази швидше, ніж OFA покоління Ampere) і надає важливу інформацію у DLSS 3.

Зображення №11. Для генерування точніших кадрів без відволікаючих артефактів, DLSS 3 поєднує вектори руху ігрового двигуна з полем оптичного потоку OFA Engine.
Таблиця порівняння RTX 4090 та RTX 3090 Ti
Наведемо ВЕЛИЧЕНЬКУ таблицю порівняння обох поколінь Ampere та Ada на прикладі найкращих відеокарт покоління: RTX 4090 та RTX 3090 Ti.
| RTX 3090 Ti | RTX 4090 | Різниця | |
| Назва GPU | GA102 | AD102 | |
| Покоління | Ampere | Ada | |
| GPC, к-ість | 7 | 11 | + 57% |
| TPC, к-ість | 42 | 64 | + 52% |
| SM, к-ість | 84 | 128 | + 52% |
| CUDA ядер, к-ість | 10752 | 16384 | + 52% |
| Tensor ядер, к-ість | 336 | 512 | + 52% |
| RT ядер, к-ість | 84 | 128 | + 52% |
| Boost Частота, MHz | 1860 | 2520 | + 35,4% |
| OFA, TOPS | 126 | 305 | + 142,8% |
| Макс FP16 (без Tensor ядер), TFLOPS | 40 | 82,6 | + 106,5% |
| Макс FP32 (без Tensor ядер), TFLOPS | 40 | 82,6 | + 106,5% |
| Макс INT32 (без Tensor ядер), TFLOPS | 20 | 41,3 | + 106,5% |
| RT, TFLOPS | 78,1 | 191 | + 144,5 % |
| Макс FP16 (з Tensor ядрами), TFLOPS | 160 / 320 | 330,3 / 660,6 | + 106 % |
| Макс FP32 (з Tensor ядрами), TFLOPS | 40 / 80 | 82,6 / 165,2 | + 106,5 % |
| К-ість відеопам’ять, GB | 24 (GDDR6X) | 24 (GDDR6X) | 0 |
| ROP, к-ість | 112 | 176 | + 57% |
| Pixel Fill-rate (Gigapixel/sec) | 208,3 | 443,5 | + 112,9 % |
| Блоки Текстур, к-ість | 336 | 512 | + 52 % |
| Texel Fill-rate (Gigatexel/sec) | 625 | 1290,2 | + 106 % |
| L1 Кеш / Спільна пам’ять, KB | 10752 | 16384 | + 52% |
| L2 Кеш, KB | 6144 | 73728 | + 1100 % |
| Розмір реєстру, KB | 21504 | 32768 | + 52% |
| TGP (Total Graphics Power), W | 450 | 450 | 0 |
| К-ість транзисторів, мільярдів штук | 28,3 | 76,3 | + 169,6 % |
| Розмір чіпу, мм2 | 628,4 | 608,5 | – 3 % |
| Тех процес | Samsung 8 nm 8N | TSMC 4N |
Як бачимо, хоча і фізично відеочіп став менший, проте елементів всередині нього стало більше. Тому і став більш ПОТУЖНИМ. Дякуємо TSMC!
А як справи в іграх?
Ну що ж. Залишається зробити останній крок – порівняння продуктивності в іграх. Візьмемо RTX 3090 та RTX 4090. І саме цікаве: ми тут з вами довго сиділи та розмовляли, а на скільки ж збільшились результати в іграх? Тому я візьму 3 гри:
- S.T.A.L.K.E.R. 2 – після виходу гри, жоден тест/огляд не може бути легітимним без неї 🙂
- God of War: Ragnarök – Як одна з ігор від Sony та багато хто захоче її пройти;
- Black Myth: Wukong – На мою думку, найбільш реалістична та красивіша графіка цього року. “Витискає всі соки” з відеокарти.
S.T.A.L.K.E.R. 2. Налаштування графіки – Epic. Результати взяті ЗВІДСИ.
| RTX 3090 | RTX 4090 | Різниця продуктивності | |
| FullHD, середній FPS | 66 | 102 | + 54% |
| FullHD, 0,1% | 54 | 61 | + 13% |
| 2K, середній FPS | 53 | 88 | + 66% |
| 2K, 0,1% | 40 | 59 | + 47,5% |
| 4K, середній FPS | 34 | 59 | + 73% |
| 4K, 0,1% | 24 | 40 | + 66% |
God of War: Ragnarök. Налаштування графіки: Ultra. Результати взяті ЗВІДСИ.
| RTX 3090 | RTX 4090 | Різниця продуктивності | |
| FullHD, середній FPS | 107 | 159 | + 48% |
| FullHD, 0,1% | 96 | 141 | + 47% |
| 2K, середній FPS | 83 | 138 | + 66% |
| 2K, 0,1% | 72 | 123 | + 70% |
| 4K, середній FPS | 57 | 98 | + 72% |
| 4K, 0,1% | 49 | 84 | + 71,5% |
Black Myth: Wukong. Графіка: Cinematic. Результати взяті ЗВІДСИ.
| RTX 3090 | RTX 4090 | Різниця продуктивності | |
| FullHD, середній FPS | 53 | 90 | + 70% |
| FullHD, 0,1% | 44 | 63 | + 43% |
| 2K, середній FPS | 43 | 73 | + 70% |
| 2K, 0,1% | 37 | 59 | + 59% |
| 4K, середній FPS | 27 | 48 | + 77,7% |
| 4K, 0,1% | 21 | 39 | + 85,7% |
Як можете побачити за результатами трьох ігор RTX 4090 очікувано виграла. Однак видно, що відрив між відеокартами збільшується зі збільшенням роздільної здатності. RTX 4090 зовсім трошки не вистачає для досягнення 60 FPS для «рідного» 4К.
Black Myth: Wukong. Графіка: Cinematic, Upscaling 75%, Ray Tracing: Very High.
| RTX 3090 | RTX 4090 | Різниця продуктивності | |
| FullHD, середній FPS | 65 | 161 | + 70% |
| FullHD, 0,1% | 56 | 116 | + 43% |
| 2K, середній FPS | 44 | 114 | + 70% |
| 2K, 0,1% | 38 | 96 | + 59% |
| 4K, середній FPS | 23 | 71 | + 77,7% |
| 4K, 0,1% | 20 | 61 | + 85,7% |
А ось видно роботу DLSS 3. Black Myth: Wukong – це не просто красива гра, а ще й динамічна. Вона все ж таки slasher/січа/souls-like. Тому потрібно вивчати боса, запамʼятовувати його та намагатися вчасно втекти від різних видів атак. Тому чим більший фпс, тим краще гравець бачить зображення і, головне, вчасно натискає клавіші. Як можете порівняти 2 таблиці, RTX 4090 з «рідних» 4K 48 фпс генерує ще 23 фпс, що в сумі дає 71 фпс і цього начебто повинно бути достатньо. Проте краще таки знизити деякі налаштування графіки – під час бою вам не потрібна високодеталізована трава чи відблиски на воді, а треба чітко та вчасно натискати клавіші клавіатури/геймпаду і гра повинна адекватно на них реагувати.
Висновок
Обидва покоління відеокарт хоча і виглядають схоже в архітектурному плані, проте RTX 4000 застосовує вагомі переваги над RTX 3000: новий техпроцес TSMC 4N дозволив не тільки підняти тактові частоти, а ще й розмістити ще більше апаратних блоків всередині GPU; нові технології дозволяють краще оптимізувати роботу з мешами, Ray Tracing та можуть покращити ігровий досвід (збільшення FPS) за допомогою DLSS 3.
Єдиною проблемою таких рішень залишається Ціна. Це були найкращі рішення для користувацького сегмента ринку, і тому доводилося за це платити величезні кошти. Проте час йде, і на горизонті вже видніється RTX 5000 покоління Blackwell. А судячи із зображень плат відеокарт та розмірів чіпа GB102, нас чекає дещо цікавеньке. Можливо навіть і новий PCIe Gen6. Теоретичний та, сподіваюсь, практичний огляд нового покоління чекайте на ITC.UA 😉
Джерела: Nvidia Ampere, Nvidia Ada, Ray Tracing.





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: