



Щойно на конференції Google Cloud Next ’26 у Лас-Вегасі Google представила восьме покоління власних процесорів — Tensor Processing Units. Обидва чіпи розроблені у партнерстві з Google DeepMind і будуть загальнодоступні пізніше цього року як частина платформи AI Hypercomputer.
На відміну від попередніх поколінь, TPU 8 уперше розділений на два спеціалізовані чіпи з принципово різними архітектурами: TPU 8t для тренування моделей і TPU 8i для інференсу. TPU 8t (кодова назва Sunfish, розроблений разом із Broadcom) орієнтований на тренування великих моделей. Він масштабується до 9 600 чіпів у єдиному суперподі з 2 петабайтами спільної високопропускної пам’яті та досягає 121 ексафлопа продуктивності у форматі FP4.
Нова архітектура міжчіпових з’єднань дозволяє Google за допомогою фреймворків JAX і Pathways масштабуватись до понад мільйона TPU в одному тренувальному кластері. Показник продуктивності на ват зріс удвічі порівняно з попереднім поколінням Ironwood. Окрема інновація — TPUDirect RDMA, що забезпечує пряму передачу даних між пам’яттю та мережевими картами в обхід CPU, суттєво знижуючи затримки.
TPU 8i (кодова назва Zebrafish, розроблений разом із MediaTek) оптимізований для інференсу та агентних навантажень. Він масштабується до 1 152 чіпів у єдиному поді, досягає 11,6 ексафлопа продуктивності FP8 і містить утричі більше вбудованої пам’яті SRAM порівняно з попередньою версією — для зберігання великих KV-кешів безпосередньо на кристалі.
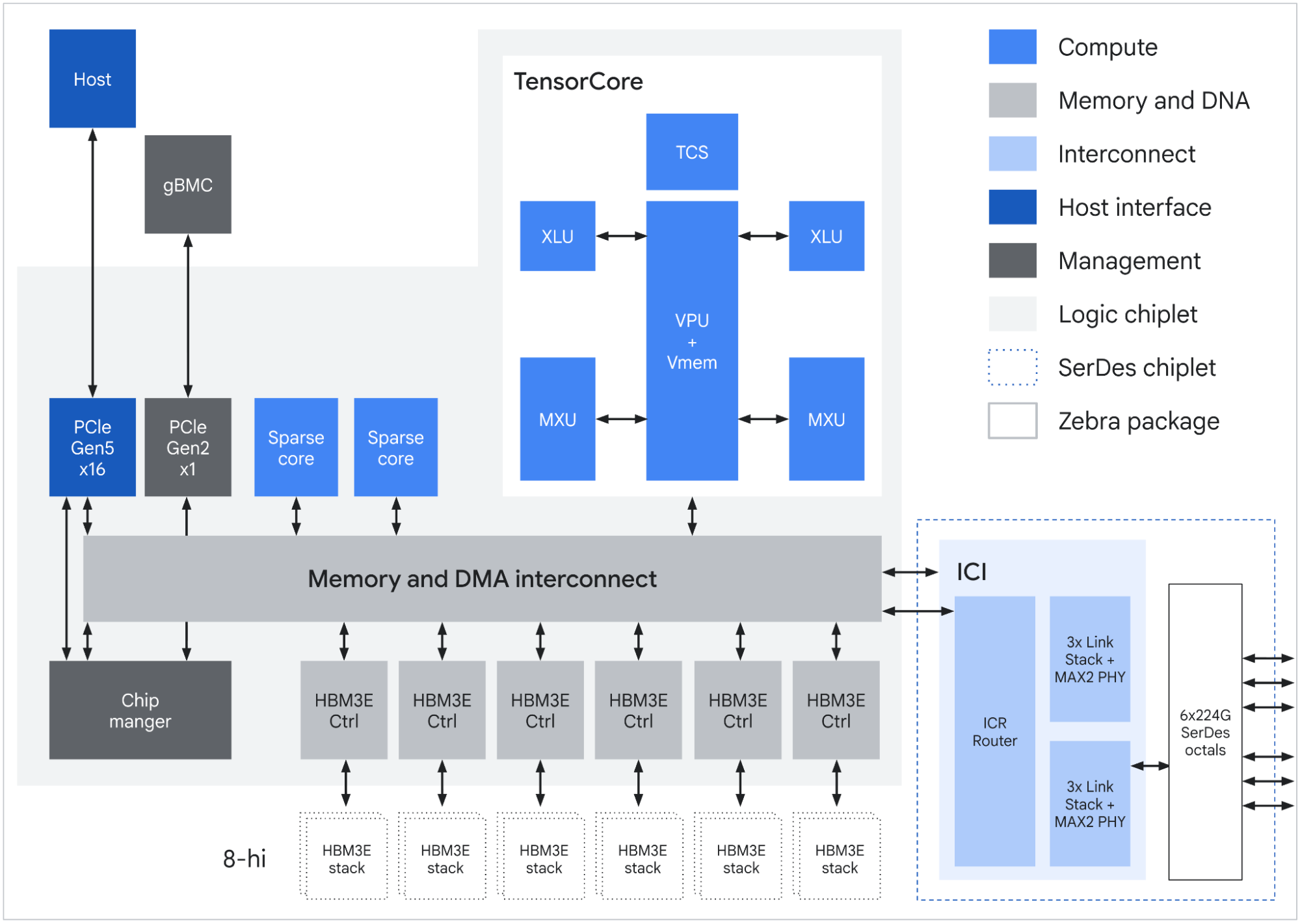
За даними Google, TPU 8i забезпечує на 80% кращу продуктивність на долар порівняно з Ironwood, що робить його придатним для одночасного запуску мільйонів агентів у промисловому масштабі. Обидва чіпи використовують Axion ARM-процесор як хост і підтримують рідинне охолодження.
Паралельно Google анонсувала мережеву інновацію Virgo Network — нову архітектуру для дата-центрів, що забезпечує до 47 петабіт за секунду пропускної здатності та здатна об’єднувати понад 134 000 чіпів TPU 8t в єдину тренувальну інфраструктуру. Нова система зберігання Managed Lustre тепер забезпечує 10 ТБ/с пропускної здатності для TPU 8t через RDMA.
Варто зазначити, що Google веде активну боротьбу за ринок ШІ-прискорювачів із NVIDIA. За даними аналітиків, Anthropic вже підписала угоду на використання до мільйона TPU від Google, а Meta уклала багаторічний багатомільярдний контракт на доступ до хмарної TPU-інфраструктури Google Cloud. Як ми писали раніше, саме на TPU навчається Gemini 3.1 Pro — модель, яка у лютому 2026 року посіла перше місце у 12 бенчмарках серед конкурентів.
Коментар експерта Cloudfresh, учасника Google Cloud Next 2026:
Google фактично підлаштовує інфраструктуру під реальні сценарії використання AI, а не навпаки. Актуальне питання на сьогодні — не як навчити модель, а як зробити її роботу стабільною, швидкою і економічно виправданою в продакшені.
І саме тому інфраструктура є ключовим фактором: вона визначає, чи залишиться AI експериментом, чи стане частиною операційної моделі бізнесу.
Дмитро Іржицький
COO & CTO в Cloudfresh 🌥️
Google роздає 20 000 безплатних курсів з ШІ на Coursera для українців: як подати заявку
Джерело: Google
Разом із Google Cloud Next 2026 відкриваються нові можливості — разом із Cloudfresh вони починають працювати на вас.
Cloudfresh 🌥️ — глобальний Google Cloud Premier Partner. Понад 2 500 клієнтів. Більше 70 країн.
Next задає новий вектор: автономні агенти, ШІ та хмарні інструменти, що вже сьогодні можуть працювати у вашому бізнесі.
Від ШІ й безпеки до інфраструктури й роботи з даними — Cloudfresh 🌥️ перетворюють нові можливості Google Cloud у конкретні рішення.
Обговорімо ваші плани →
#GenerateTheReal✨





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: