Скріншот/YouTube
On Tuesday, September 2, Tencent introduced a new AI model HunyuanWorld-Voyager, capable of creating sequential 3D videos from a single image.
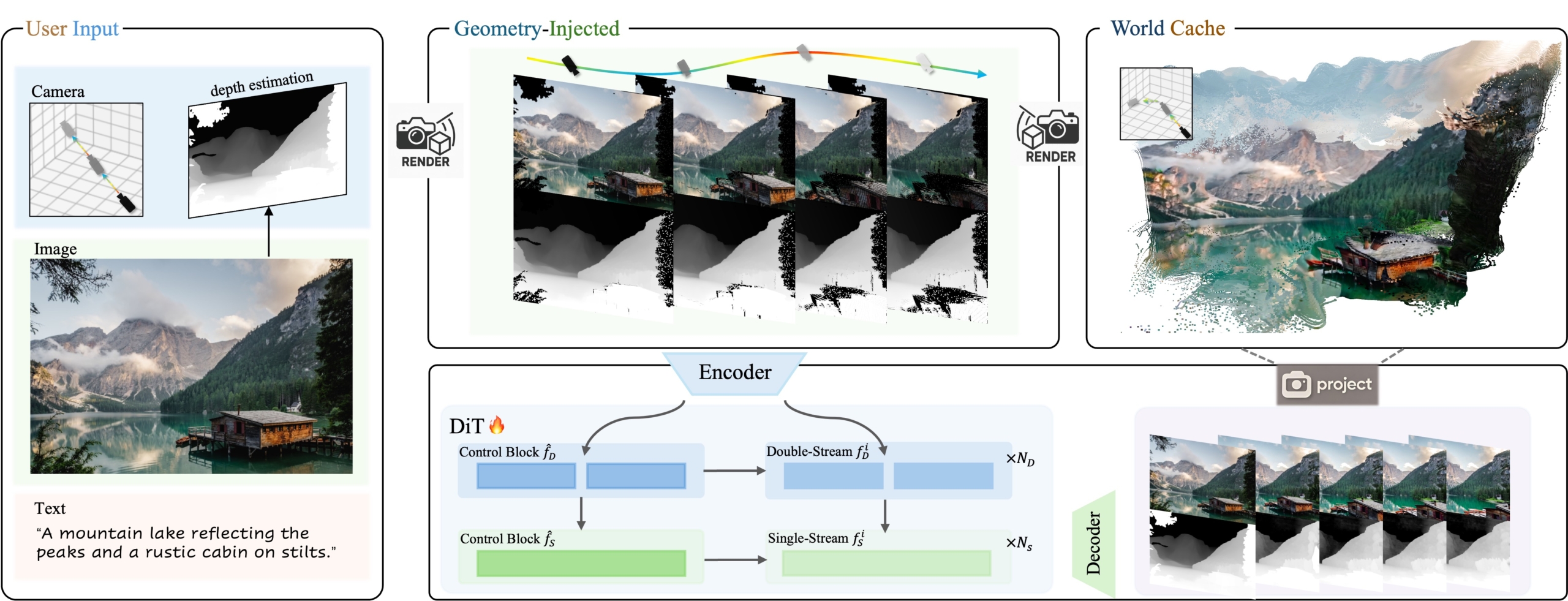
Users can control the camera to explore the generated worlds. The model simultaneously generates RGB video and depth information, allowing users to directly change details without the need to use traditional modeling tools.
However, we shouldn’t expect HunyuanWorld-Voyager to become a full-fledged alternative to traditional video games in the near future. The generated results are not real 3D models, but they achieve a similar effect.
In particular, AI generates 2D video frames, that maintain spatial consistency, as if the camera was actually moving in three dimensions. Each generation creates 49 frames lasting about 2 seconds.
Tencent representatives note, that several videos can be sequentially combined with each other for a total duration of several minutes. Objects remain in the same relative position when the camera moves around them, and the perspective changes correctly, as expected in a real three-dimensional environment.
The end result is a video with depth maps, not true 3D models, but they can be transform them into three-dimensional point clouds for reconstruction. As an input, the system receives a single image and a given camera trajectory from the user.
Users can choose, how the camera moves, back and forth, left and right, or rotation through the interface. HunyuanWorld-Voyager combines the image and depth data with a “global cache” to create sequential videos, that reflect the user’s chosen camera movement.
The key limitation of all AI models on the architecture Transformer is actually an imitation of patterns, identified in the training datasets, which limits their ability to use these patterns in new conditions, that were not present in the training set.
To train HunyuanWorld-Voyager, the developers used more than 100 thousand video clips, including scenes, generated by on the basis of Unreal Engine. In this way, the model was trained to simulate camera movement in a three-dimensional gaming environment.
Most AI-based video generators, such as Sora, sequentially create frames without tracking or maintaining spatial consistency. Meanwhile, HunyuanWorld-Voyager is trained to recognize and reproduce patterns of spatial consistency, but with the addition of geometric feedback.
As each frame is generated, the system converts the original data into three-dimensional points and then projects these points back into two dimensions for use in future frames. This method forces the model to match the learned patterns with geometrically consistent projections of its own previous output. And while this provides significantly better spatial consistency, than traditional video generators, it is still a pattern matching based on geometric constraints, rather than actual modeling in a three-dimensional environment.
This explains why the model is able to maintain consistency for several minutes, but has difficulty when the camera is fully rotated 360°. Frame by frame, small errors accumulate as a result of pattern matching, until geometric constraints no longer maintain spatial consistency.
Tencent’s technical report notes, that the system uses two key parts, that work together. HunyuanWorld-Voyager simultaneously generates color video and depth information. That is, if there is, for example, a tree in the video, the depth data determines exactly, how far away the tree is. Secondly, it uses, what Tencent calls a “global cache” — a growing collection of 3D points created from previously generated frames.
When generating new frames, this point cloud is projected back into 2D from a new camera angle to create partial images that show, what should be visible based on the previous frames. Next HunyuanWorld-Voyager uses these frames to check spatial consistency and ensure, that new frames are consistent with those generated earlier.
HunyuanWorld-Voyager complements the collection of AI-based video generators, which also includes Genie 3, announced by Google in August this year. This model, as noted, generates interactive worlds with 720p resolution and 24 frames per second with the help of text prompts.
At the same time Dynamics Lab’s Mirage 2 offers in-browser world generation, allowing users to upload images and transform them into game environments with real-time text prompts. Meanwhile HunyuanWorld-Voyager is more focused on video production and 3D reconstruction processes with the ability to output RGB depth.
HunyuanWorld-Voyager is an advanced version of the earlier HunyuanWorld 1.0, introduced in July this year. It is also part of Tencent’s broader Hunyuan system, which includes Hunyuan3D-2 for generating 3D models from text, and HunyuanVideo for generating videos.
For training HunyuanWorld-Voyager developers have created software, that automatically analyzes existing videos, processes camera movements, and calculates depth for each frame. The system processed over 100 thousand video clips from real recordings and Unreal Engine renders.
To work with this model you need significant computing power: at least 60 GB of VRAM with 540p resolution. At the same time, Tencent recommends 80 GB of VRAM for optimal results. Tencent published model weights on Hugging Face and included code, that works with both single and multiple graphics cards.
However, this model has significant license restrictions. Together with other models of Hunyuan, World-Voyager is not available for users from the EU, the UK, and South Korea. In addition, commercial use with more than 100 million active users per month requires separate Tencent licensing.
According to the benchmark WorldScore, which was developed by researchers from Stanford, Voyager scored the highest overall score of 77.62, followed by WonderWorld at 72.69 and CogVideoX-I2V at 62.15. The model excelled in object control (66.92), style consistency (84.89), and subjective quality (71.09), although it came in second in camera control (85.95), behind WonderWorld with a score of 92.98.
While these self-reported benchmark results look promising, wider use still faces challenges due to the high computing power. For developers who need faster data processing, the system supports parallel output on multiple GPUs using the xDiT framework.
Source: ArsTechnica
Контент сайту призначений для осіб віком від 21 року. Переглядаючи матеріали, ви підтверджуєте свою відповідність віковим обмеженням.
Cуб'єкт у сфері онлайн-медіа; ідентифікатор медіа - R40-06029.
{kind=link}