

Как и зачем Google создаёт искусственный интеллект

Компания Google открыла в Цюрихе новый исследовательский центр Google Research, который будет заниматься машинным интеллектом. Теперь это один из крупнейших центров исследований, связанный с разработкой искусственного интеллекта за пределами США. Его открытие связано с новой стратегией Google, которая предполагает активное внедрение машинного интеллекта в сервисы и приложения. Уже сегодня компания использует наработки в этой области в таких продуктах, как Translate и Photos. А на конференции Google I/O 2016 были представлены мессенджер Allo и устройство умного дома Google Home, в которых также используется машинный интеллект. С открытием нового исследовательского центра в Цюрихе, Google планирует совершить значительный прорыв в этой области. Нам удалось побывать на открытии этого центра и узнать о том, как и для чего компания разрабатывает искусственный интеллект.
Как Google создаёт искусственный интеллект?
Открывшийся в Цюрихе исследовательский центр будет заниматься разработкой в трёх ключевых для искусственного интеллекта областях: машинное обучение, машинное восприятие, а также обработка и понимание естественной речи. Все они необходимы для того, чтобы создать компьютеры следующего поколения, которые смогут учиться от людей и окружающего их мира.
Машинное обучение
Машинный или искусственный интеллект часто путают с машинным обучением, и хотя без второго не может быть первого, они основаны немного на разных принципах. Само по себе понятие «искусственный интеллект» предполагает создание компьютера, который думает, в то время как «машинное обучение» — это разработка компьютеров, которые могут учиться. «Запрограммировать компьютер, чтобы он был умным, может быть сложнее, чем запрограммировать компьютер, который учится, чтобы быть умным» — объясняет разницу Грег Коррадо (Greg Corrado), старший научный исследователь Google по машинному обучению.
Работу машинного обучения сегодня может ощутить на себе каждый пользователь электронной почты Gmail. Если раньше спам-фильтр сервиса следовал строгим правилам с ключевыми словами, то сегодня он учится на основе примеров. Отфильтровывая почту, он становится всё лучше и лучше. Это один из самых простых примеров использования машинного обучения, но сегодня Google уже создаёт более сложные самообучающиеся системы.
Для этого компания применяет три способа машинного обучения:
1. Обучение с учителем — это обучение на примерах, на манер того, как спам-фильтр Gmail фильтрует почту, получая всё новые и новые примеры спам-рассылок. Единственная проблема с этим способом: для того, чтобы он был эффективным, нужно иметь большое количество готовых примеров.
2. Обучение без учителя — это кластеризация данных, компьютеру предоставляются объекты без описания и он пытается найти между ними внутренние закономерности, зависимости и взаимосвязи. Так как данные изначально не имеют обозначений, то для системы нет сигнала ошибки или награды, и она не знает правильного решения.
3. Обучение с подкреплением — этот метод связан с «обучением с учителем», но здесь данные не просто вводятся в компьютер, а используются для решения задач. Если решение правильное, то система получает позитивный отклик, который запоминает, подкрепляя тем самым свои знания. Если же решение неверное, то компьютер получает негативный отклик, и должен найти другой способ решения задачи.
Сегодня Google в основном использует для своих сервисом метод «обучение с учителем», тем не менее, в компании отмечают, что «обучение с подкреплением» может иметь ещё больший потенциал. Именно комбинация этих двух методов была использована для создания искусственного интеллекта AlphaGo, который смог победить профессиональных игроков в игру го. Сначала компьютер со счётом 5-0 обыграл чемпиона Европы по го Фань Хуэя (2-ой дан), а потом сыграл с Ли Седолем, игроком 9 дана (самый высокий ранг в го), и опять финальный счёт оказался 4-1 не в пользу человека.
Почему победа искусственного интеллекта в игре го так важна для развития машинного обучения? Дело в том, что сама по себе игра очень сложная для компьютера. В го используется доска гобан 19х19 линий, на которую один игрок кладёт чёрные, а другой — белые камни, в попытке захватить как можно большую площадь доски. В отличие от шахмат, где каждая фигура имеет чётко заданную позицию и ходы, в го игроки ограничены только доской. Поэтому во время игры они используют не только знания, но также интуицию. Для компьютера дополнительной сложностью является огромное количество возможных позиций (10^170), а также ему тяжело оценить, кто выигрывает игру.
Поэтому для AlphaGo были разработаны две нейросети. Первую назвали «сетью значения», она оценивает позицию камней на поле числами от -1 до 1, чтобы определить, какие камни лидируют: белые (-1) или чёрные(1). Если позиция сбалансирована, и каждый игрок может победить, то значение будет близко к 0. Нейросеть сканирует доску и оценивает позицию камней, после чего начинает понимать насколько выгодно расположены белые и чёрные камни. Вторую нейросеть назвали «сетью политик». На основе экспертных данных о ходах в го она составляет карту, определяя какие именно ходы в этой позиции будут наиболее удачными.
Таким образом, «сеть значения» позволяет AlphaGo понимать позицию камней на доске и определять, кто выигрывает, а «сеть политик» упрощает алгоритму поиска подбор возможных вариантов хода, так как ограничивает его в зависимости от позиции камней.
Перед тем как продолжить, важно разобрать, что же такое «нейросеть»? К сожалению, сегодня не существует единого формального определения «искусственной нейронной сети». Если попробовать изложить его простыми словами, то нейросеть — это ряд математических моделей, которые созданы по принципу работы биологических нейронных сетей. Искусственные нейроны (простые процессоры) соединяются между собой, получают сигнал, обрабатывают его и отправляют дальше, следующему нейрону. Каждый нейрон — это простая математическая функция, но работая вместе, они позволяют решать сложные задачи.

Как тренировались нейросети для AlphaGo?
«Мы начали с данных профессиональных игроков в го. Так как игры в основном записывают, то у нас было очень много пар: позиция плюс ход, которым она была достигнута. Одна игра даёт нам где-то 300 таких пар. Каждый ход в такой игре профессиональный, так как сделан экспертом. Мы использовали «обучение с учителем», чтобы научить нейросеть предугадывать, какой бы ход сделал профессиональный игрок в этой позиции. Так была создана «сеть политик». Дальше мы позволили нейросети играть против себя, причём как с позиции чёрных, так и белых камней. Результат этих игр мы загружали обратно в нейросеть. Это уже «обучение с подкреплением», оно пока не так хорошо исследовано, но мы считаем, что это будущее машинного обучения. Дальше, благодаря игре нейросети против себя самой, мы получили большой объём данных о позиции камней на доске, а также исходе игр. На их основе мы тренировали «сеть значения», которая научилась понимать, при каких позициях выигрывают чёрные камни, а при каких белые. Оценка — это очень важный параметр для создания игровой программы и машинного обучения в целом, ведь вам нужен способ определить прогресс в игре» — рассказывает Тор Грэпель (Thore Graepel), учёный-исследователь в проекте Google DeepMind, который разработал AlphaGo.
Несмотря на то, что AlphaGo обыграл профессиональных игроков в го и легко обыгрывает другие искусственные интеллекты, разработанные для этой игры, не только это стало выдающимся достижением данной системы. Во второй игре с Ли Седолем AlphaGo сделал очень необычный 37 ход на 5 линии, который изначально не казался удачным, но потом позволил компьютеру захватить эту часть доски. Дело в том, что в экспертной информации, которую загружали в AlphaGo, не было подобных ходов, и можно считать, что это было одно из первых проявлений креативности в исполнении компьютера.
Сегодня для машинного обучения Google использует библиотеку открытого программного обеспечения TensorFlow. Это API второго поколения, который работает для исследований, а также для коммерческих продуктов Google, в которых используется машинное обучение, среди них поиск, распознавание речи, Gmail и Photos.

Машинное восприятие
Ещё одним важным направлением для развития искусственного интеллекта является машинное восприятие. Несмотря на то, что за последнее десятилетие компьютеры сильно продвинулись в распознавании звуков, музыки и рукописного текста, им всё ещё тяжело даётся распознавание изображений и видео. Зрительная система человека без проблем распознаёт изображения, в каждом большом полушарии нашего мозга есть первичная зрительная кора (зрительная зона V1), которая содержит 140 млн нейронов с десятками миллиардов соединений между ними. И, тем не менее, мозг человека дополнительно использует экстрастриарную зрительную кору (зоны V2, V3, V4 и V5) для распознавания изображений. Поэтому для нас не составляет большой проблемы увидеть серого кота, который лежит на сером ковре. Но для компьютера это очень сложная задача.
Раньше Google осуществлял каталогизацию фотографий по описаниям, пользователю нужно было добавлять метки к снимкам, чтобы потом их можно было сгруппировать или найти. Сегодня в сервисе Google Photos работает более продвинутое распознавание изображений на основе «свёрточной нейронной сети». Эта архитектура, разработанная учёным Яном Лекуном, обладает одним из лучших алгоритмов по распознаванию изображений. Если не углубляться в детали, то она представляет собой многослойную структуру искусственных нейронов, каждый слой которой принимает на вход только небольшой участок введённого изображения. С помощью проекта Deep Dream сегодня любой желающий может оценить, как именно свёрточная нейронная сеть видит изображения.
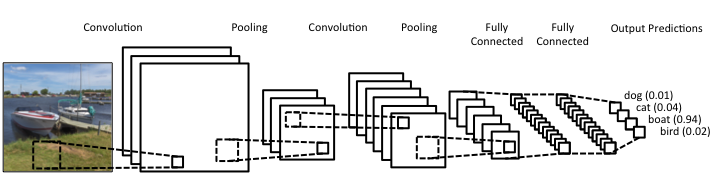
Для обучения своей нейронной сети Google использует открытые базы данных с изображениями. Например, в 2012 году в Google научили нейросеть распознавать изображения котов, используя 10 млн кадров с котами из видео на YouTube.
Обработка и понимание естественной речи
Для того чтобы компьютер понимал не просто голосовые команды, но и естественную речь, в Google используют рекуррентные нейронные сети.
Традиционное распознавание речи разбивает звуки на небольшие фрагменты по 10 миллисекунд аудио. Каждый такой фрагмент анализируется на содержание частот, при этом полученный вектор характеристик проходит через акустическую модель, которая выводит распределение вероятностей по всем звукам. Дальше в сочетании с другими характеристиками речи, через модель произношения, система связывает последовательность звуков правильных слов в языке и в модели, определяя, насколько вероятно данное слово в языке, который используется. В конце языковая модель анализирует полученные слова и фразу целиком, пробуя оценить, возможна ли такая последовательность слов в этом языке. Но по некоторым словам в фонетической записи сложно определить, где заканчивается одна буква и начинается другая, а это очень важно для правильного распознавания.
Теперь в Google используют акустическую модель на основе рекуррентной нейронной сети с архитектурой «долгой кратковременной памяти». Простыми словами, эта нейросеть лучше других умеет запоминать информацию, что позволило обучить её распознаванию фонем во фразе, а это значительно улучшило качество системы распознавания. Поэтому сегодня распознавание голоса на Android работает практически в режиме реального времени.

Искусственный интеллект: помощник или угроза?
Этическая сторона использования искусственного интеллекта всегда находится на повестке дня, признают в Google. Тем не менее, в компании пока не считают, что мы достаточно близки к созданию компьютеров, у которых есть самосознание, чтобы предметно обсуждать этот вопрос. «Компьютеры учатся медленно» — утверждает Грег Коррадо. Пока Google может построить искусственный интеллект, который хорошо справляется с одной задачей, например с игрой го, как AlphaGo. Но для полноценного искусственного интеллекта понадобятся многократно большие вычислительные мощности. Сегодня же мы видим, что производительность процессоров замедляется, мы практически подошли к пределу «Закона Мура», и хотя это отчасти компенсируется повышением производительности видеокарт и появлению специализированных процессоров, пока этого всё равно недостаточно. Кроме этого, ещё одной преградой является отсутствие достаточного количества экспертной информации, которую можно было бы использовать для машинного обучения. Все эти, и не только, проблемы человечество может решить в течение 20, 50 или 100 лет, а может не решить никогда, никто не может дать точный прогноз. Соответственно, искусственный интеллект, который мы видим в фильмах, возможно, будет сильно отличаться от того, что мы в итоге получим.
Помощник на все руки и будущее поиска Google
Google пока ставит перед собой более реалистичную цель — создать виртуальных ассистентов на основе искусственного интеллекта. Сегодня уже существуют такие виртуальные помощники как Siri или Google Now, но они очень ограничены и оторваны от реальности, в которой находится пользователь. Что же хочет сделать Google? В компании считают, что виртуальный ассистент должен понимать окружающий мир, положение пользователя в этом мире, а также опираться на актуальный контекст в общении.
«Представьте, что у вас есть невероятно умный ассистент, и вы говорите ему: изучи эту область и расскажи мне, что ты думаешь. Вот, что мы пытаемся создать. В моём случае я бы хотел сказать ассистенту: покажи мне самые интересные и релевантные вещи, которых я ещё не знаю» — рассказывает Эрик Шмидт (Eric Schmidt), глава совета директоров компании Alphabet, которой принадлежит Google.
Таким образом, в Google видят искусственный интеллект в качестве нового инструмента, который сможет расширить возможности человека, путём предоставления ему новых знаний. Хорошим примером тут может послужить AlphaGo, который игроки в го воспринимают в качестве возможности повысить свой уровень. Ведь если тренироваться против искусственного интеллекта, который уже превышает максимальный ранг в игре, то это может вывести её на новый уровень.





Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: