

Chinese artificial intelligence startup MiniMax is known for its realistic generative video model Hailuo. Its LLM for programming MiniMax-M1 is free for commercial use.
The open source MiniMax-M1 is distributed under the Apache 2.0 license. This means that companies can use it for commercial applications and modify it to their liking without restrictions or fees. The open-source model is available on Hugging Face and on Microsoft GitHub.
The MiniMax-M1 features a context window of 1 million input tokens and up to 80 thousand output tokens, making it one of the widest models for contextual reasoning tasks. For comparison, GPT-4o by OpenAI has a context window of only 128,000 tokens. This is enough to exchange information about the size of a literary novel in one interaction. With 1 million tokens, the MiniMax-M1 can exchange the information of a small book collection. Google Gemini 2.5 Pro also offers an upper limit of 1 million tokens, with a 2 million window in development.
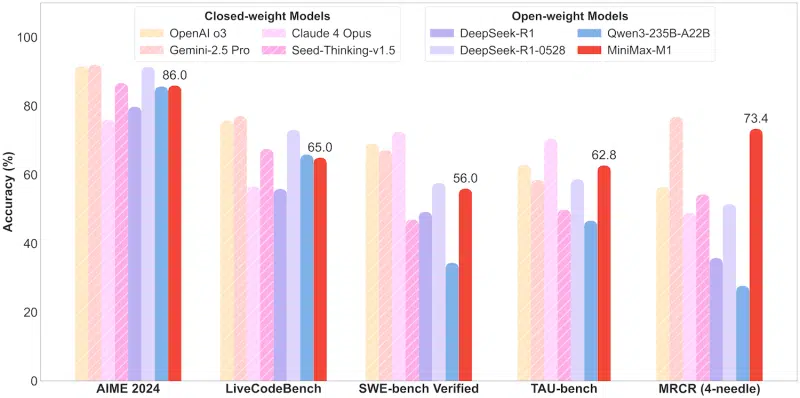
According to the technical report, the MiniMax-M1 requires only 25% of the FLOPs required by DeepSeek R1 when generating 100,000 tokens. The model is available in MiniMax-M1-40k and MiniMax-M1-80k variants, with different output sizes. The architecture is based on the previous platform, MiniMax-Text-01, and includes 456 billion parameters, of which 45.9 billion are active for a single token.
The M1 model was trained using an innovative and highly efficient methodology. It is a hybrid mixture of experts (MoE) with a lightning-fast attention mechanism designed to reduce inference costs. The training cost was only $534,700. This efficiency is attributed to CISPO’s specialized algorithm that prunes importance sampling weights rather than token updates, as well as the hybrid attention design that helps optimize scaling. For comparison, DeepSeek R1 training cost $5.6 million (although There are doubts about this), while the cost of GPT-4 training from OpenAI is estimated to exceed $100 million.
Day 1/5 of #MiniMaxWeek: We’re open-sourcing MiniMax-M1, our latest LLM — setting new standards in long-context reasoning.
– World’s longest context window: 1M-token input, 80k-token output
– State-of-the-art agentic use among open-source models
– RL at unmatched efficiency:… pic.twitter.com/bGfDlZA54n— MiniMax (official) (@MiniMax__AI) June 16, 2025
This is the first release in the MiniMaxWeek series that the company announced at X. Apparently, users are in for five days of exciting announcements.
Source: VentureBeat
Spelling error report
The following text will be sent to our editors: