

At the GTC March 2024 Keynote event, NVIDIA introduced the Blackwell chip architecture and B200 GPUs based on it. The new GPUs with AI capabilities will replace the retiring H100 and H200 in data centers. Grace Blackwell GB200 chips will combine the Grace architecture with Blackwell.
The B200 GPU contains 208 billion transistors (compared to 80 billion on the H100/H200). It delivers 20 petaflops of AI performance from a single GPU — a single H100 had a maximum of 4 petaflops of AI computing. The chips will have 192 GB of HBM3e memory, which provides up to 8 TB/s of bandwidth.
Blackwell B200 is not a single GPU in the traditional sense. It consists of two tightly connected chips that function as one unified CUDA GPU. The two chips are connected by an NV-HBI (NVIDIA High Bandwidth Interface) interface with a speed of 10 TB/s.
The Blackwell B200 is based on TSMC’s 4NP process, an improvement on the 4N process used in the Hopper H100 and Ada Lovelace. The process doesn’t offer much in the way of density improvements, so a way to make the chip bigger was needed to gain processing power, which may explain the combination.





Each chip has four HMB3e stacks of 24GB each with 1TB/s of bandwidth on a 1024-bit interface. For comparison, the H100 had six 16GB HBM3 stacks. The Blackwell B200 achieves 20 petaflops using the new FP4 number format with double the bandwidth of the Hopper H100’s FP8 format.
NVIDIA Blackwel chip variants
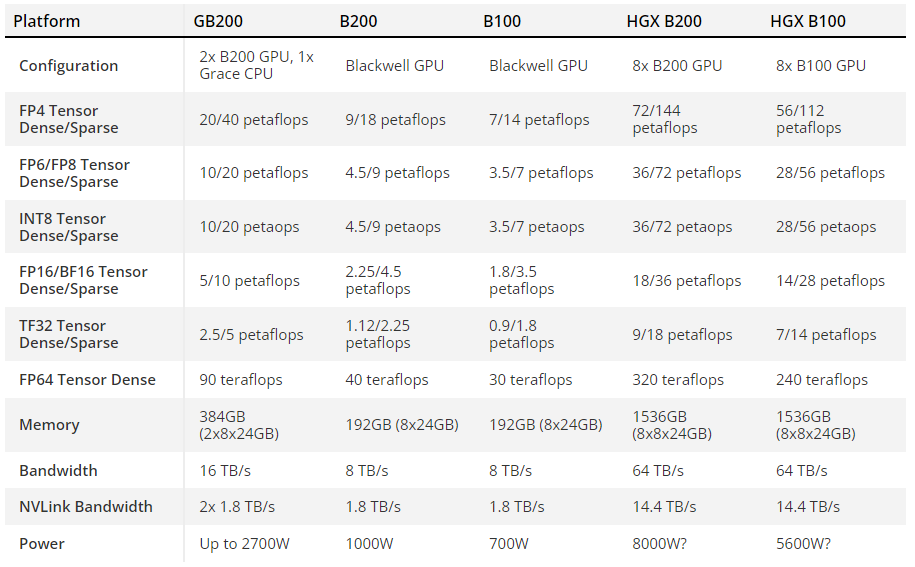
The largest and fastest solution is the GB200 superchip, which consists of two B200 GPUs. This «monster» has a customizable TDP of up to 2700 W — for two chips (four GPUs combined) plus one Grace processor. The values of up to 20 petaflops FP4 for a single B200 — are taken for half of the GB200 superchip. it is not specified what the TDP is for a single B200 GPU.




Another Blackwell option is the HGX B200, which is based on using eight x86 GPUs in a single server node. They are configured with 1000 watts per B200 and the GPUs provide up to 18 petaflops of FP4 throughput — 10% slower than GB200.
There will also be an HGX B100 chip. Same basic design as the HGX B200 with an x86 processor and eight B100 GPUs, but it is designed to be compatible with existing HGX H100 infrastructure and provide the fastest deployment. TDP per GPU is capped at 700 watts, the same as the H100, and throughput drops to 14 petaflops FP4 per GPU. Across all three of these configurations, the HBM3e has the same 8TB/s of throughput per GPU.
NVIDIA NVLINK 7.2T
For multi-node connectivity, NVIDIA is introducing the fifth generation of NVLink chips and the NVLink Switch 7.2T. The new NVSwitch chip has a bi-directional bandwidth of 1.8 TB/s. This is a 50 billion transistor chip, also manufactured on the TSMC 4NP process.








Each compute node in the GB200 NVL72 has two GB200 superchips, so one tray contains two Grace CPUs and four B200 GPUs with 80 petaflops of FP4 AI and 40 petaflops of FP8 AI performance. These are liquid-cooled 1U servers that take up a significant portion of the standard 42 rack units.
In addition to the GB200 superchip compute panels, the GB200 NVL72 will also have NVLink switch panels. These are also 1U liquid-cooled trays, with two NVLink switches per tray and nine such trays per rack. Each tray provides 14.4 TB/s of total bandwidth.
In total, the GB200 NVL72 has 36 Grace processors and 72 Blackwell GPUs with 720 FP8 petaflops and 1440 FP4 petaflops. With 130 TB/s of multi-node bandwidth available, the NVL72 can process up to 27 trillion AI language model parameters. The remaining racks are dedicated to networking and other data center elements.

Also introduced are SuperPODs that combine multiple GB200s. NVLink now supports up to 576 GPU domains, the new DGX SuperPODs scale to exactly that number of GB200 Blackwell GPUs. Each SuperPOD can accommodate up to eight GB200 NVL72 systems, which corresponds to 288 Grace processors and 576 B200 GPUs.
Source: Tom’s Hardware
Spelling error report
The following text will be sent to our editors: