

In February, the Ministry of Digital Transformation of Ukraine announced launch of the WINWIN AI Center of Excellence — a unit that will integrate AI solutions at the state level and, in the future, help create competitors to large language models (LLMs) similar to OpenAI, Anthropic, Google Gemini, or DeepSeek. This initiative is aimed at developing and implementing the latest technologies in the field of artificial intelligence (AI), including generative models like ChatGPT. Ukraine has talented engineers and scientists working for the world’s leading companies. But is this enough to develop and implement a national LLM, and why is it needed? We discussed this issue with the Ministry of Digital Transformation and Andriy Nikonenko — Manager, Machine Learning & Data Science at Turnitin.
Can Ukraine afford own LLM? We will see at the end of the year
The field of large-scale language models (LLMs) is growing extremely fast, with several key players playing leading roles. Currently, the market is divided between several giants, with the top four being American companies:
- OpenAI (GPT-4o)
- Anthropic (Claude 3.6)
- Google DeepMind (Gemini 2.5)
-
Meta (Llama 4)
- DeepSeek (DeepSeek-R1) from China and Mistral AI (Le Chat) from France.
What is a large language model (LLM) and how does it work?
Large Language Model (LLM) — a neural network trained on huge amounts of text data to understand, process, and generate natural language. The neural network can predict the next word in a sentence, answer questions, translate and create coherent texts on any topic, and at the same time imitate the style and logic of live human speech. LLMs are used in chatbots, search engines, automated translation, and other areas.
The development of large language models (LLMs) is closely related to the way human language processing and machine learning have evolved. Initially, the models were based on recurrent neural networks (RNNs) and LSTMs — technologies that helped «memorize» previous words. The real breakthrough came in 2017, when Google introduced Transformers — a new architecture that allowed for better work with text. At the heart of Transformers is the self-attention mechanism: the «model parses» different words in a sentence to better understand their meaning in the overall context. This helps to process long texts efficiently and consider the relationships between words, even if they are far apart. Thanks to this, the model can understand the context of the entire text and provide a meaningful and logical answer.
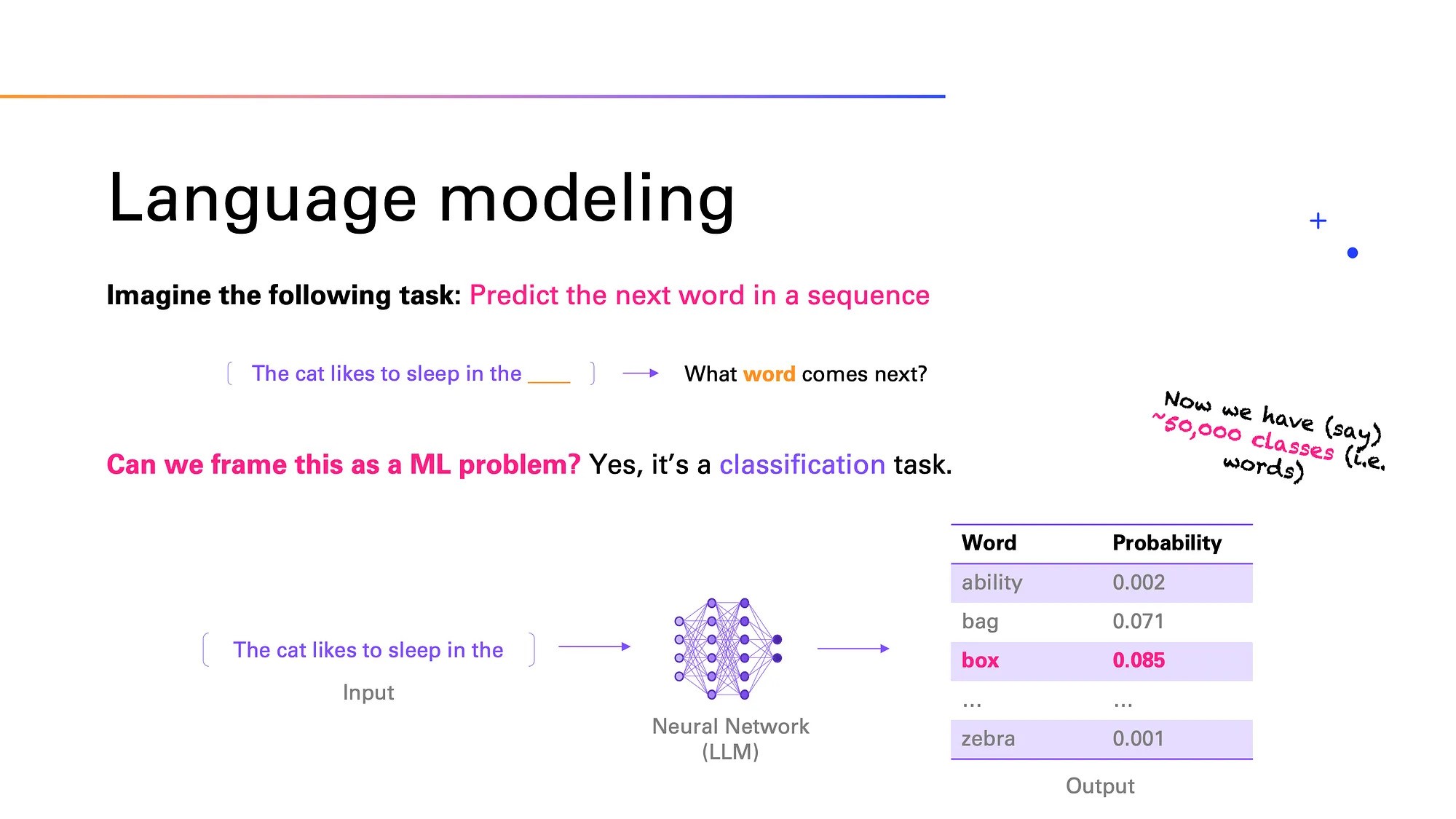
For example, ChatGPT by OpenAI is capable of producing text that is hard to distinguish from human speech. This model is popular in various applications: from chatbots to automated article writing. And Google Gemini is focused on deep contextual understanding, which is critical for improving the relevance (matching the result to the desired one) of search engine results.
Deep learning powers large language models. This process works as follows:
- Search and prepare data
To train a model, you need a lot of texts. It is «trained» on huge amounts of textual information — from books, forums, articles, website logs, etc. It is important that this data is unlabeled, i.e., it has no special labels that would explain what each fragment means. This makes such data cheaper and easier to collect. Before the texts are transferred to the model, they are cleaned: personal information, inappropriate or unnecessary content is removed
- Tokenization
Machines do not perceive text the way humans do. Therefore, before processing, the text is divided into small parts — tokens. These can be single words, parts of words, or even symbols. Then these tokens are converted into numbers, which the neural network starts working with. This is necessary for the model to better understand the context. For example, if you use only words, you need to store all possible forms of the word (“works”, “worked”, “will work”). And if you work with parts of words, you can «compose» any word from smaller parts. This saves memory, speeds up work, and reduces computing costs
- Transformer architecture
The name ChatGPT contains the abbreviation GPT — Generative Pre-trained Transformer. Generative — because the model can create (generate) new text. Pre-trained — because it was first trained on a large amount of text and then further adapted. Transformer — is a type of neural network that uses the mechanism of self-attention
- Preliminary training
At this stage, the model learns to recognize patterns, learns to predict the next word in a sentence or guess the missing word. This is called causal language modeling and masked language modeling
- Fine-tuning (fine-tuning)
After the model already knows a lot about a particular language, it is «retrained» for specific tasks — for example, to improve it at writing medical articles or helping with Python programming. Also, learning from examples with human feedback is added (RLHF — reinforcement learning based on human feedback). That is, experts evaluate the quality of the machine’s response.
- Text generation (inference)
After the user enters a query (promt), the model starts creating a response (one token at a time). It tries to continue the text so that it sounds logical and natural.

LLM is a powerful tool for text generation, translation, analysis, etc. However, its creation requires enormous resources, and its use requires care. The process of training a large language model requires a huge amount of data to be used in the training set. The processing will take months or even years, requiring incredible computing resources and electricity. It also requires solving the problems of parallelism (when calculations are performed simultaneously on multiple processor cores or GPUs. Therefore, there may be difficulties with distribution, synchronization, etc.).
Large language models have other drawbacks as well. The main one is hallucinations. That is, errors often occur in their answers (the model can invent an event or a person). In addition, large language models require a huge amount of computing resources and electricity.
The more data you use for training, the higher the potential quality of the model. However, this also means longer and more expensive training. Inference (i.e., answer generation) will be cheaper if the model itself is smaller, as it requires fewer resources to run. But usually, large amounts of data are used to create larger models, which means that inference of such models requires more resources. A balance has to be struck between the size of the model, the quality of the answer, and the cost of using it.
So why do we need a national Ukrainian LLM if it is so expensive, and most international projects use existing models from market leaders? This is what the Ministry of Digital Transformation answered.
English-language models, which are the basis of the most popular chatbots ChatGPT, Gemini, and others, show worse results with non-English content than local models trained in national languages.A Ukrainian LLM will produce better answers than global English-language models because it will be trained on Ukrainian data. A national LLM can better understand the dialects, terminology, and context in the country, giving better answers both linguistically and in terms of facts and ideological questions about Ukraine’s history, political situation, and war.Moreover, the national LLM allows storing and processing data within the country, which is strategically important for the use of AI in defense, government organizations, medicine, and the financial sector.
When foreign models are used, data, including confidential data, go abroad. As a country, we cannot control how companies store and process it. The national LLM will solve this issue because the data of Ukrainians and the state will be stored domestically.The national and ideological aspect is also important. Foreign models are trained on large data sets with different narratives, including those hostile to Ukraine. A national LLM will have a pro-Ukrainian view of the world and will correctly answer sensitive questions related to war, history, etc.The development of the Ukrainian LLM involves 6 stages.
First of all, it is organizational preparation: recruitment of experts to the technical and ethics boards, search for partners. At the same stage, we collect data. The second and third stages involve the launch of a pilot model for 1-3 billion tokens and a medium-scale model for 11 billion. Next, we are going to align and fine-tune. After that, we plan to launch a flagship model and evaluate and deploy a full-fledged model.We plan to launch the model in November-December 2025. In total, this is 9 months of work — from organizational work and data collection for LLM training to the launch of a full-fledged model.
What do we need to create a competitive LLM?
The key goal of the Ukrainian LLM is to meet the internal needs of the state and business, not to compete with commercial models in the global market. The greatest value of a national LLM is in its localization and adaptation to the national context.At the same time, a national LLM will create competition between businesses within the country. The model will force companies to compete on a new level — in particular, to compete whose AI service is more user-friendly. Thus, it will affect the overall standard of living of Ukrainians, the economy, and the business sector.We don’t have the time and resources to create a model from scratch because we need to launch AI products that will change public services and business.
That is why we are going through the process of pre-training and fine-tuning an existing open-source solution.First of all, we need high-quality data, including cleaned and structured corpora of texts divided into tokens. Second, we need a technical infrastructure for training the model. And, of course, funding. The experience of other countries shows that it takes from $1.5 million to $8 million to create an LLM.
No public funds will be used to develop the LLM, so we are looking for investors among businesses. We are also considering cooperation with Big Tech and are negotiating with several international companies. As for the pre-train model, there are not enough computing resources in Ukraine. The situation with the inference is better: the WINWIN AI Center of Excellence team is currently testing models on H100 and less powerful GPUs, analyzing architectural challenges and scaling options.
Nevertheless, Ukrainian data centers are preparing their capacities for future loads related to the development of AI products.In addition, national infrastructure providers have facilities that can be used for LLM training.The development of the LLM is a joint project of the state, business, and the AI community, including researchers, scientists, specialized communities, etc. Business will become a key infrastructure provider for training the model. Specialized communities, universities, and research institutions will help with data collection. The role of the Ministry of Digital Transformation and the WINWIN AI Center of Excellence is to coordinate the entire process.
How does the Ministry of Digital Transformation assess the availability of high-quality Ukrainian text data? Are there any initiatives to create a national text corpus for AI?
Specialized communities and universities have compiled a database of Ukrainian-language data from open sources: news, data from Wikipedia, etc. Dataset «Kid» is the largest, with 113 gigabytes of scrubbed text. There are also NER-UK, UA-GEC, BrUK and others. They are enough to train small models, but larger models need more data. We are now talking to universities and research institutions about expanding this data.
In your opinion, how many AI and Data Science specialists do you think such a project requires? Are there enough of them in Ukraine now? How does the war affect the ability to attract resources?
Yes, there are enough such specialists. We already have a potential team and stakeholders to develop the model. The organizational structure of the LLM involves the creation of a single team with several divisions. First of all, it is a technical board and a development team responsible for the technical side of the model and its training.It is important that the model works ethically, for example, giving correct answers to national and historical questions.
Therefore, an ethics board will be formed, which will include copyright and ethics lawyers, cultural and historical experts, and other specialists who will monitor the quality of the data. We will engage universities and Ukrainian businesses to work with the data. The impact of the war on the IT staffing market is tangible, but when we talk about LLM, the specialized community is motivated to work on this project because it is a strategic initiative. Interestingly, Ukrainians from abroad also want to join the LLM development.
Therefore, we see the maximum participation of the Ukrainian professional community.As for the infrastructure, even before the full-scale war, we did not have the computing power necessary for LLM pre-training. It is very unlikely that they will appear now, because it requires large investments. Although Ukrainian providers have the necessary computing power to run this model, but not for pre-train.
What are the economic benefits of creating your own LLM?
The model is being developed as an open-source solution for the non-profit sector. Companies and developers will be able to download it and create chatbots, AI assistants, and other solutions, thus increasing their own efficiency and competitiveness. Secondly, the LLM will give a pulse to the emergence of new AI startup solutions that will attract investment in Ukraine.The launch of the Ukrainian LLM will also give impetus to the emergence of several AI solutions for the public sector.
The WINWIN AI Center of Excellence at the Ministry of Digital Transformation has already started working on its first products: an AI assistant for Diia, an AI tool for analyzing regulations, an AI tool for translating and analyzing European legislation, and internal HR and OKR assistants for the ministry’s team. With the advent of the LLM, there will be more AI solutions not only in the Ministry of Digital Transformation, but also in other government agencies.The Ministry of Digital Transformation is also integrating artificial intelligence into Mriya.
AI will create individualized educational trajectories for children based on their interests, needs, and motivation. This will work on the basis of an AI model that will help analyze the connections between topics, identify knowledge gaps, and build a personalized learning path.Thanks to the Ukrainian LLM, we will be able to actively integrate AI into the systems of the Security and Defense Forces and thus increase the effectiveness of battlefield strikes and defense data analysis.
Currently, the key blocker to integrating AI into defense systems is security, as data is transferred abroad when using foreign models. With the Ukrainian LLM, the data will remain in Ukraine.Scientific and educational institutions will be able to download it and deploy their own solutions based on it — chatbots, AI assistants, etc. As a result, AI will become a part of Ukrainian education and science and turn into an accessible tool in education and research. The result will be individualized learning and new scientific breakthroughs.
How real is the Ukrainian ChatGPT?
Even the European Union does not currently have models that can compete with market leaders. Investments are directed only at certain aspects, not at full-scale research. No significant breakthrough has been achieved yet. For example, let’s recall an AI chatbot called Lucie, which received support from the French government, but was closed due to significant shortcomings.
As mentioned above, most language models, including Meta’s Llama, are trained primarily on English-language data, which affects the quality of answers in other languages. In order to develop a Ukrainian language model, it will be necessary to solve the issue of collecting high-quality Ukrainian language data. The best language models are trained on huge amounts of text data.
To create a high-quality Ukrainian LLM, you need a corpus (In linguistics, a set of texts selected and processed according to certain rules and used as a basis for language research.) of texts of hundreds of billions of words. It is also important to ensure the high quality of the data, which will include modern literary, scientific, technical, and spoken Ukrainian. Will the data announced by the Ministry of Digital Transformation be enough? We will see at the end of 2025.
Expert opinion from Andriy Nikonenko — Manager, Machine Learning & Data Science at Turnitin
«There is objectively not enough Ukrainian text data to fully train a large language model. Even Meta’s Llama-2 was trained mainly on English-language corpora, where the share of Ukrainian was negligible».

Creating a full-fledged ChatGPT-level Ukrainian language model is a complex task that requires significant resources in several key areas. Training a large language model (LLM) requires thousands of high-performance GPUs or TPUs optimized for AI computing. Large US companies like OpenAI or Google use more than 25,000 Nvidia GPUs to train their models. For this reason, it is worth considering the possibility of using ready-made models with further adaptation to Ukrainian needs.
«Large language models are not just algorithms, but large-scale projects that require the integration of a large number of resources. That’s why even large countries like Germany or France are in no hurry to create their own LLMs, but rather integrate into global initiatives».
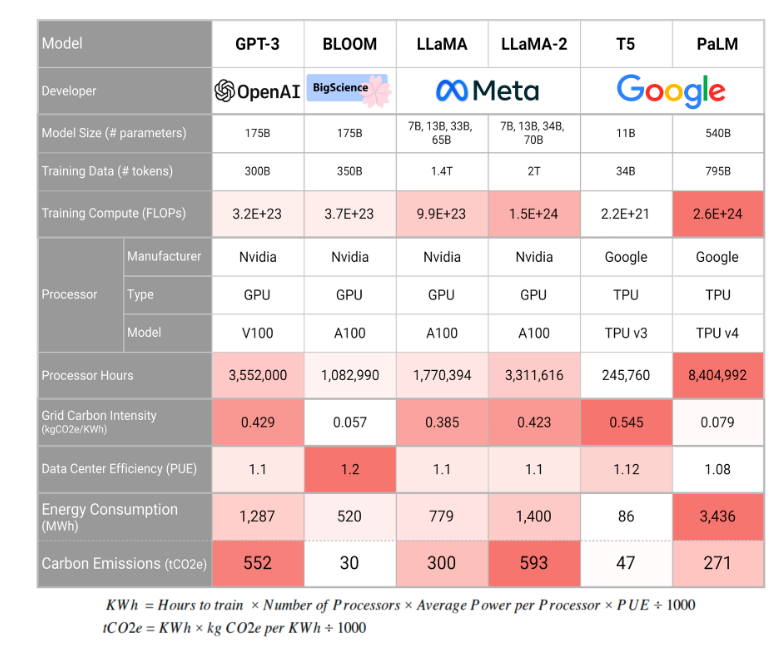
It is also important to get access to multilingual datasets if you need the model to interact with other languages.
Therefore, the development of a language model of this level will require a comprehensive approach and a professional team, which should include:
- Computational linguists — specialists who understand the structure of the Ukrainian language and can adjust the language model.
- Data scientists and engineers — specialists engaged in model training, computing process optimization, and AI architecture development.
- Ethics experts because it is important that the language model is not biased or incorrect.
Fortunately, there are many specialists and companies in Ukraine that deal with artificial intelligence (AI), machine learning (ML), and natural language processing, for example: SoftServe, ELEKS, Neurons Lab, Reface AI, and others.
«Preparing your own data center for LLM — an investment of hundreds of millions of dollars. The main motive for creating a Ukrainian LLM may be security. However, it should be understood that it is not only about training the model, but also about its further support, updating, and adaptation. Creating your own data center will cost hundreds of millions of dollars, while cooperation with international platforms can reduce costs. Security and privacy issues are critical: the state model must be protected from attacks and unauthorized access».
The Ukrainian LLM will guarantee national cybersecurity and drive innovations in the field of AI. Its own model would help to use it in public services and the military, and stimulate the development of businesses based on it.
For example, research 2023 has shown that the introduction of artificial intelligence (AI) in the financial sector of Ukraine can significantly improve the accuracy of reporting and help overcome crisis situations. AI can improve the quality of financial data and automate routine tasks, allowing professionals to focus on strategic planning. In another study from the same year, researchers supported idea of introducing AI, as they believe that there are many problems in public finance that cannot be solved by traditional methods.
This is an ambitious but achievable goal that could become a strategic breakthrough for the country in the field of artificial intelligence. Implementation requires a comprehensive approach, huge investments, and international cooperation. Not to mention the issues of physical security and stable energy supply. However, the first and most difficult step has already been taken. We will see the results by the end of 2025.
Spelling error report
The following text will be sent to our editors: