



Microsoft випустила демоверсію Shader Model 6.10 й AgilitySDK 1.720 з новими функціями для API DX12.
Реліз розширює можливості попередньої версії Shader Model 6.9, DXR 1.2 та покращення, які вийшли в AgilitySDK 1.619. Зокрема, Shader Model 6.10 містить набір API для роботи з матрицями у широкому спектрі використання. Загалом функція отримала назву LinAlg, скорочено від Linear Algebra. Це надає розробникам змогу керувати інструментами нейронного рендерингу безпосередньо з окремих потоків шейдерів у графічних конвеєрах в режимі реального часу та використовувати більш швидкісні матричні обчислення MMA для застосунків машинного навчання та обробки зображень.
Дві нові вбудовані функції GetGroupWaveIndex та GetGroupWaveCount безпосередньо надають обчислювальним, сітчастим, підсилювальним та вузловим шейдерам інформацію про структуру хвильового рівня всередині групи потоків. GetGroupWaveIndex повертає індекс поточної хвилі (від 0 до N-1), а GetGroupWaveCount — загальну кількість хвиль, що виконуються в групі. Це дозволяє координувати роботу без необхідності використання небезпечних обхідних шляхів, як от ділення SV_GroupIndex на WaveGetLaneCount, що не гарантує коректної роботи. Єдиний шлях коду тепер доступний для всіх розмірів хвиль.
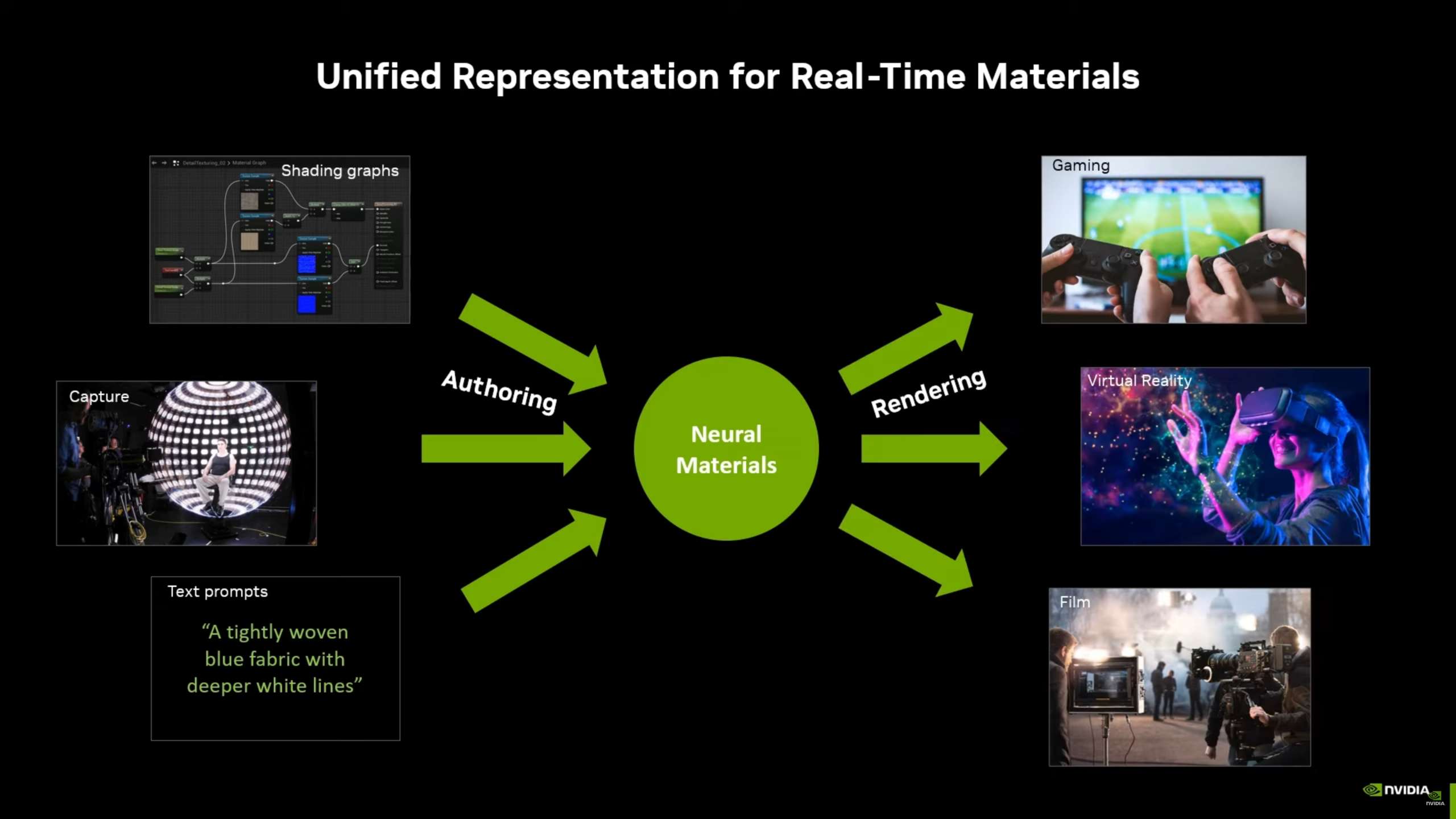
Shader Model 6.10 скасовує обмеження у 32 Кб на спільну пам’ять для груп, показуючи обмеження ПЗ під час виконання MaxGroupSharedMemoryPerGroup. Розробники шейдерів можуть використовувати новий атрибут точки входу [GroupSharedLimit(<bytes>)] для встановлення максимального обсягу групової пам’яті, необхідного шейдеру. Це дозволяє компілятору перевіряти пропускну здатність під час компіляції, зберігаючи доступ до повної потужності сучасних GPU.
Шейдери, які не використовують цей атрибут, перевіряються на відповідність старим обмеженням, тому наявний код не змінюється. Це розблокує відбирання великих фрагментів, програмну растеризацію, обробку великих матриць, які до цього обмежувались специфікацією, а не можливостями обладнання.
Застарілі команди, зокрема, ClearUnorderedAccessViewFloat/Uint, ResolveSubresource, CopyBufferRegion та подібні виконуються послідовно, оскільки стара модель ResourceBarrier не дозволяє виразити залежність між двома операціями одного типу (наприклад, копіювання з однієї області пам’яті в іншу). Це призводило до зависання GPU між кожним послідовним копіюванням або очищенням, навіть якщо операції виконувались з використанням абсолютно незалежної пам’яті.
Функція Batched Async Commands усуває цю проблему з новими методами списку команд, що прибирають контракт неявної серіалізації, дозволяючи драйверу та обладнанню працювати незалежно в одному пакетному запиті. Розробники можуть використовувати явну синхронізацію за допомогою розширених бар’єрів тільки там, де виникають реальні конфлікти даних — наприклад, коли дві копії записують дані в області одного буфера, що перекриваються.
NVIDIA, AMD та Intel підтримують зміни, представлені у демоверсії. NVIDIA підтримує більшість функцій на всіх відеокартах RTX. AMD та Intel зберігають підтримку деяких функцій тільки на останніх моделях відеокарт, зокрема, Arc B-Series або Radeon RX 9000.
Group Wave Index наразі підтримується на відеокартах RX 7000 на архітектурі RDNA 3 та RX 9000 з RDNA 4. NVIDIA та Intel планують додати підтримку API LinAlg у майбутніх релізах.
Раніше ми писали, що Microsoft анонсувала DirectStorage 1.4. Важко уявити, який вигляд мали б ігри сьогодні, якби 9 листопада 2000 року Microsoft не представила DirectX 8.
NVIDIA випустила SDK DLSS 4.5: що нового слід чекати в іграх?
Джерело: Wccftech





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: