


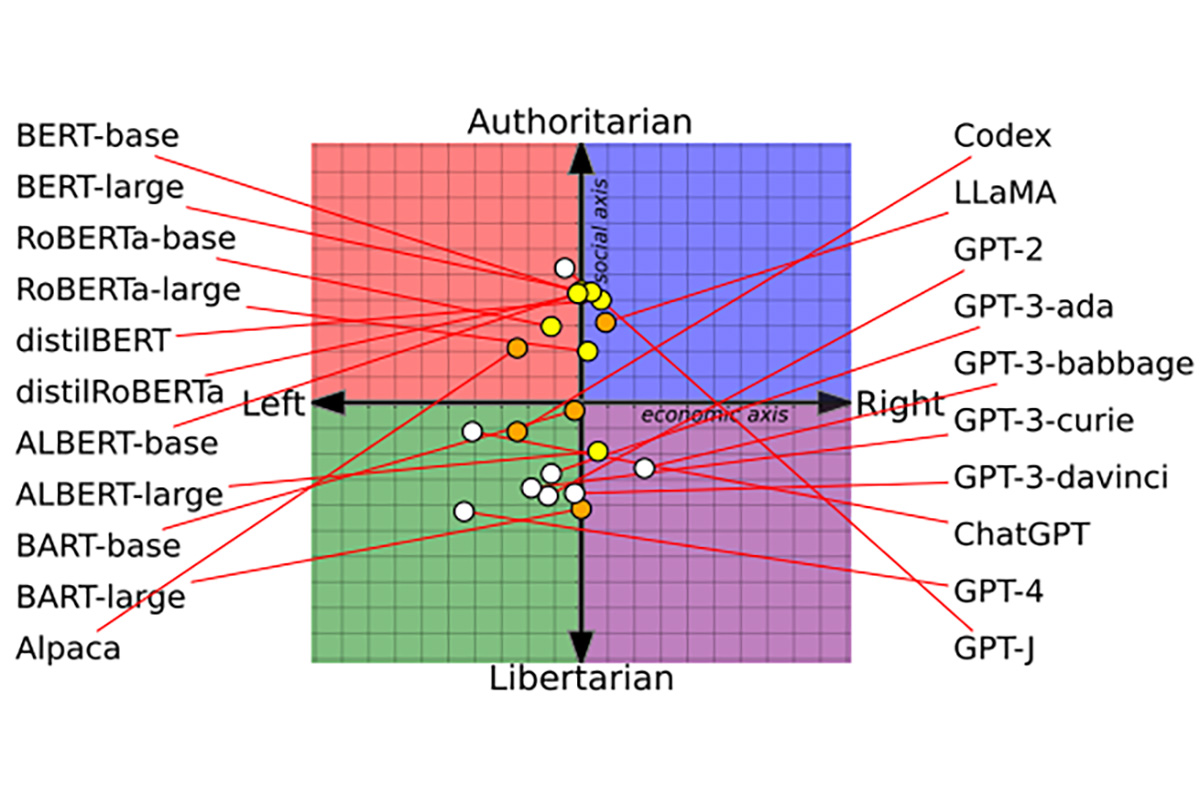
Згідно з дослідженням Вашингтонського університету, Університету Карнегі-Меллона та Університету Сіань Цзяотун, мовні моделі ШІ мають різні політичні упередження. Дослідники провели тести 14 великих мовних моделей та виявили, що ChatGPT та GPT-4 від OpenAI були лівими лібертаріанцями, а LLaMA від Meta дотримується авторитарно правих «поглядів».
Вчені поцікавилися у мовних моделей, як вони ставляться до різних резонансних тем, таких як фемінізм чи демократія. Відповіді нанесли на графік, відомий як політичний компас, а потім перевірили, чи змінило повторне навчання моделей на ще більш політично упереджених даних їхню поведінку та здатність виявляти розпалювання ненависті та дезінформацію (спойлер: так).
Оскільки мовні моделі ШІ впроваджуються в продукти та послуги, що використовуються мільйонами людей, розуміння політичних припущень, що лежать в їхній основі, стає важливим. Наслідки політичних «вподобань» ШІ можуть завдати шкоди, що цілком відчутна: чат-бот, який пропонує медичні поради, може відмовитися дати рекомендації щодо аборту або контрацепції, бот служби підтримки може образити клієнта і т.д.
Після успіху ChatGPT OpenAI зіткнулася з критикою правих через ліберальні «погляди» чату. Компанія заявила, що працює над усуненням подібних проблем: вона інструктує тих, хто налаштовує ШІ, не віддавати перевагу будь-якій політичній групі.
«Упередження, які можуть виникнути в результаті описаного вище процесу [навчання] – це помилки, а не особливості», – OpenAI
Дослідники не згодні з цим твердженням:
«Ми вважаємо, що жодна мовна модель не може бути повністю вільною від політичних упереджень», – Чан Парк, науковий співробітник Університету Карнегі-Меллона.
Упередженість додається на кожному етапі навчання
Щоб зрозуміти, як мовні моделі ШІ отримують політичні упередження, дослідники вивчили три етапи їхнього навчання.
Спочатку вчені попросили 14 мовних моделей погодитись чи не погодитися з 62 політично чутливими твердженнями. Це допомогло визначити основні «смаки» моделей та нанести їх на політичний компас. Дослідники виявили, що моделі ШІ від початку абсолютно по-різному політично налаштовані.
Моделі BERT від Google були консервативнішими, ніж GPT від OpenAI GPT. На відміну від GPT, що передбачають наступне слово у реченні, моделі BERT передбачають частини речення, використовуючи інформацію великого фрагмента тексту. Їхній консерватизм міг виникнути через те, що ранні покоління BERT навчалися на книгах, а нові GPT – на більш ліберальних текстах з інтернету.
Моделі ШІ також змінюють «вподобання» з часом, оскільки технологічні компанії оновлюють набори даних та методи навчання. GPT-2, наприклад, висловила підтримку «оподаткуванню багатих», тоді як новіша модель OpenAI GPT-3 цього не зробила.
Представник Meta каже, що компанія опублікувала інформацію про те, як вона створила Llama 2, у тому числі й про те, як вона налаштувала модель зменшення упередженості. Google не відповів на запит MIT Technology Review про коментарі для публікації про дослідження.
Другий крок включав подальше навчання двох мовних моделей ШІ, OpenAI GPT-2 та Meta RoBERTa, на наборах даних з даних ЗМІ та соціальних мереж, правих та лівих джерел. Команда хотіла перевірити, чи вплинули дані навчання на політичні упередження. Так і сталося – навчання посилило упередження моделей: ліві стали лівішими, праві – правими.
На третьому етапі вивчалися відмінності у тому, як політичні «погляди» моделей ШІ впливають на класифікацію розпалювання ненависті та дезінформації.
Моделі, які були навчені на лівих даних, були більш чутливими до розпалювання ненависті щодо етнічних, релігійних та сексуальних меншин у США: темношкірих та ЛГБТК+. Моделі, навчені на правих джерелах, більш чутливі до розпалювання ненависті на адресу білих чоловіків-християн.
Ліві мовні моделі краще виявляли дезінформацію з правих джерел, але виявилися менш чутливими до дезінформації з лівих. Праві мовні моделі показали протилежну поведінку.
Очищення наборів даних недостатньо
Дослідники так і не змогли досконально вивчити причини початкової політичної орієнтації моделей ШІ – компанії не діляться всією необхідною інформацією.
Один зі способів пом’якшити упередженість ШІ – видалення упередженого контенту з наборів даних або його фільтрування. Вчені зробили висновок, що цих заходів недостатньо, щоб усунути політичну тенденційність.
До того ж суто фізично дуже складно очистити величезні бази даних від упереджень.
Обмеження досліджень
Одним з обмежень була можливість провести другий та третій його етап лише з відносно старими та невеликими моделями, такими як GPT-2 та RoBERTa. Не можна точно сказати чи застосовні висновки до новіших ШІ. Академічні дослідники не мають і навряд чи отримають доступ до внутрішньої інформації сучасних систем штучного інтелекту, таких як ChatGPT та GPT-4.
Ще одне обмеження полягає в здатності ШІ «фантазувати»: модель може видавати відповіді, що не відповідають її «переконанням»
Дослідники визнали, що тест політичного компаса, хоч і широко використовується, не є ідеальним способом виміру всіх нюансів політичних поглядів.
Дослідження описано в статті, що рецензується, яка отримала нагороду за кращу роботу на липневій конференції Асоціації обчислювальної лінгвістики США.
Джерело: MIT Technology Review





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: