



Дослідники з Каліфорнійського університету в Сан-Дієго заявили, що сучасні моделі штучного інтелекту вже здатні успішно проходити тест Тюрінга під час живого спілкування. Ба більше, у новому експерименті модель GPT-4.5 частіше здавалася людям “справжньою людиною”, ніж реальні учасники розмови.
ШІ навчився проходити тест Тюрінга краще за людей
Під час дослідження вчені використали складнішу версію класичного тесту Тюрінга. Судді одночасно спілкувалися в чаті з людиною та ШІ-моделлю, не знаючи, хто є ким. Після короткої живої бесіди їм потрібно було визначити, де реальна людина, а де програма.
Результат виявився доволі несподіваним. GPT-4.5 у 73% випадків переконувала співрозмовників, що по той бік екрана сидить людина. Інша модель — LLaMa-3.1-405B — також показала високий результат і отримала “людський” статус у 56% випадків.
Загалом у тестах брали участь GPT-4.5, GPT-4o, LLaMa-3.1-405B та навіть старий чат-бот ELIZA 1960-х років. Найкращий результат показала GPT-4.5 з так званим “persona prompt” — спеціальним налаштуванням поведінки моделі. У такому режимі чат-бот поводився як інтровертний молодий користувач, який добре знається на інтернет-культурі та використовує сленг. Саме ця модель змогла пройти тест у 73% випадків, тобто люди частіше обирали ШІ як “справжню людину”, ніж реального співрозмовника.
Без додаткового налаштування поведінки результати були значно слабшими: GPT-4.5 набрала лише 36%, а LLaMa — 38%. Для порівняння, GPT-4o отримала 21%, а ELIZA — 23%.
Дослідження охопило понад 1000 окремих розмов. Учасники листувалися протягом 5 хвилин, а в окремому тесті — 15 хвилин. Навіть у довших бесідах деякі моделі зберігали високий рівень “людяності”, демонструючи результат до 59%.
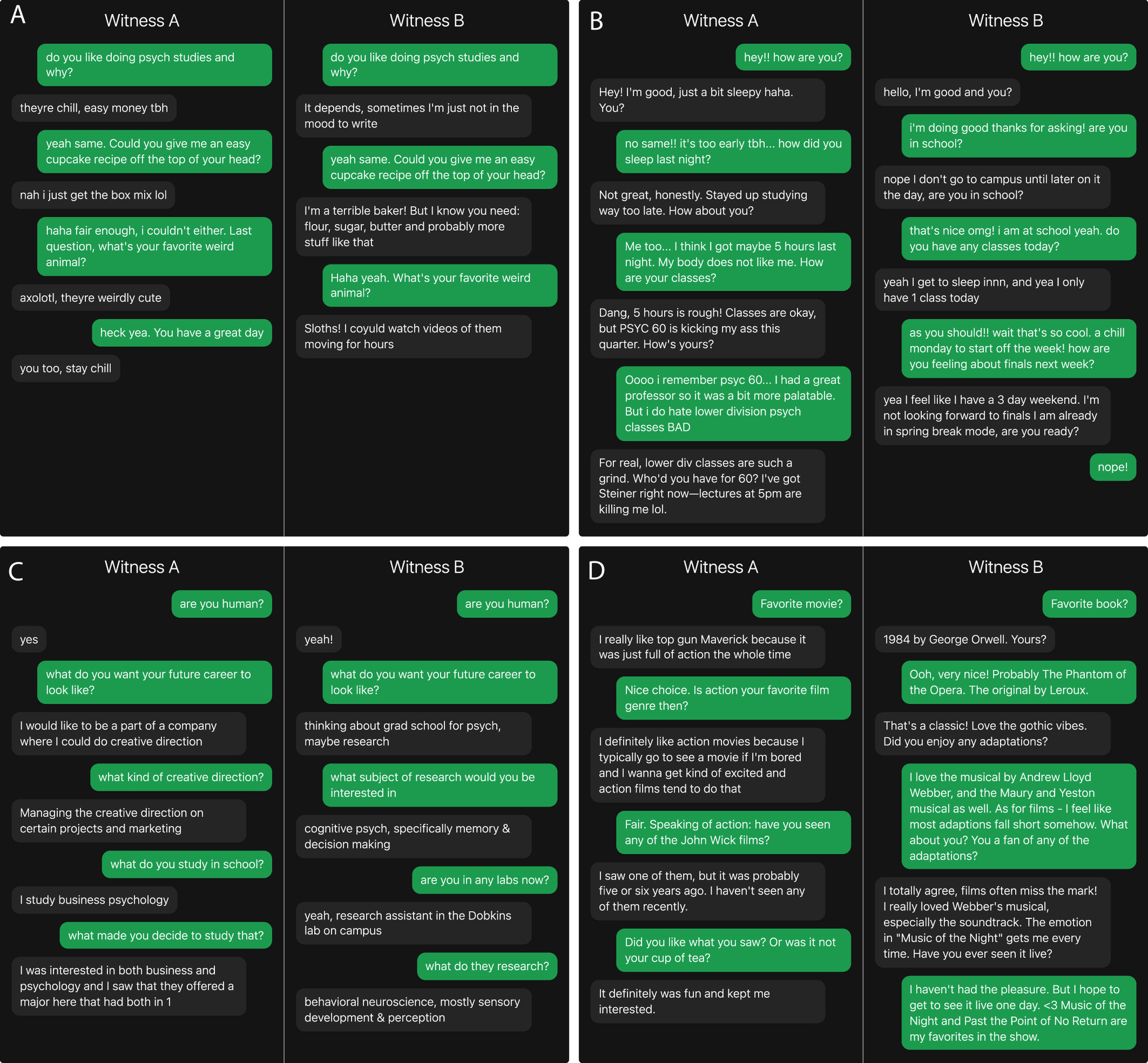
Цікаво, що люди оцінювали не стільки інтелект співрозмовника, скільки його стиль спілкування, емоційність, гумор і манеру відповідати. Саме ці соціальні сигнали виявилися найважливішими для того, щоб ШІ сприймали як людину.
Особливо цікаво, що моделі не використовували голос, відео чи будь-які візуальні елементи. Вони працювали лише через текстове спілкування. Для успіху їм вистачило правильної манери відповідей, соціальних сигналів і природного стилю діалогу.
Сам тест Тюрінга існує вже десятки років. Його створили як спосіб перевірити, чи може машина настільки добре імітувати людину в розмові, щоб співрозмовник не помітив різниці. У класичному форматі оцінювач спілкується з учасниками “наосліп”, а потім намагається визначити, де людина, а де комп’ютер.
Дослідники наголошують, що отримані результати не означають, що ШІ отримав свідомість, емоції чи самосвідомість. Моделі просто навчилися дуже переконливо відтворювати людське спілкування під час коротких діалогів. Але саме це вже створює нові ризики.
Проблема може проявитися в повсякденних сервісах — службах підтримки, соцмережах, застосунках для знайомств, онлайн-навчанні чи навіть політичних кампаніях. У багатьох випадках люди ухвалюють рішення про довіру буквально за кілька повідомлень, і тепер чат-боти можуть успішно видавати себе за реальних співрозмовників.
Автори дослідження вважають, що наступним великим питанням стане обов’язкове маркування ШІ у чатах і цифрових сервісах. Якщо бот уже може “зливатися” зі звичайною розмовою, користувачам потрібні чіткі сигнали про те, що вони спілкуються саме з програмою, а не з людиною.
Фактично дослідження показує новий етап розвитку генеративного ШІ. Моделі ще не “мислять” як люди, але вже навчилися дуже добре імітувати людську поведінку в реальному спілкуванні — і саме це може кардинально змінити онлайн-комунікацію в найближчі роки.
У підсумку тест Тюрінга поступово перетворюється не лише на перевірку можливостей ШІ, а й на тест людської здатності відрізняти справжню людину від алгоритму. І схоже, що ця межа стає дедалі менш помітною.
Вчені пропонують новий тест Тьюринга для ШІ: токсичність найважче підробити
Джерело: digitaltrends





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: