



На мероприятии GTC March 2024 Keynote NVIDIA представила архитектуру чипов Blackwell и графические процессоры B200 на ее основе. Новые GPU с возможностями искусственного интеллекта заменят заменившие H100 и H200 в центрах обработки данных. Чипы Grace Blackwell GB200 объединят архитектуру Grace с Blackwell.
Графический процессор B200 содержит 208 миллиардов транзисторов (против 80 миллиардов на H100/H200). Он обеспечивает 20 петафлопс производительности ИИ от одного GPU — один H100 имел максимум 4 петафлопса в вычислениях ИИ. Чипы получат 192 ГБ памяти HBM3e, которая обеспечивает пропускную способность до 8 ТБ/с.
Blackwell B200 не является единственным GPU в традиционном понимании. Он состоит из двух плотно соединенных кристаллов, которые функционируют как один унифицированный графический процессор CUDA. Два чипа соединены интерфейсом NV-HBI (NVIDIA High Bandwidth Interface) со скоростью 10 ТБ/с.
Blackwell B200 выполнен по техпроцессу TSMC 4NP, усовершенствованному 4N, который использовался в Hopper H100 и Ada Lovelace. Техпроцесс не предлагает значительного улучшения плотности, поэтому для прироста вычислительной мощности понадобился способ сделать чип больше, что может объяснить сочетание.





Каждый кристалл имеет четыре стека HMB3e по 24 ГБ каждый с пропускной способностью по 1 ТБ/с на 1024-битном интерфейсе. Для сравнения, H100 имел шесть стеков HBM3 по 16 ГБ. Показателя 20 петафлопс Blackwell B200 достигает с помощью нового формата чисел FP4 с двойной пропускной способностью, чем в формате FP8 Hopper H100.
Варианты чипов NVIDIA Blackwel
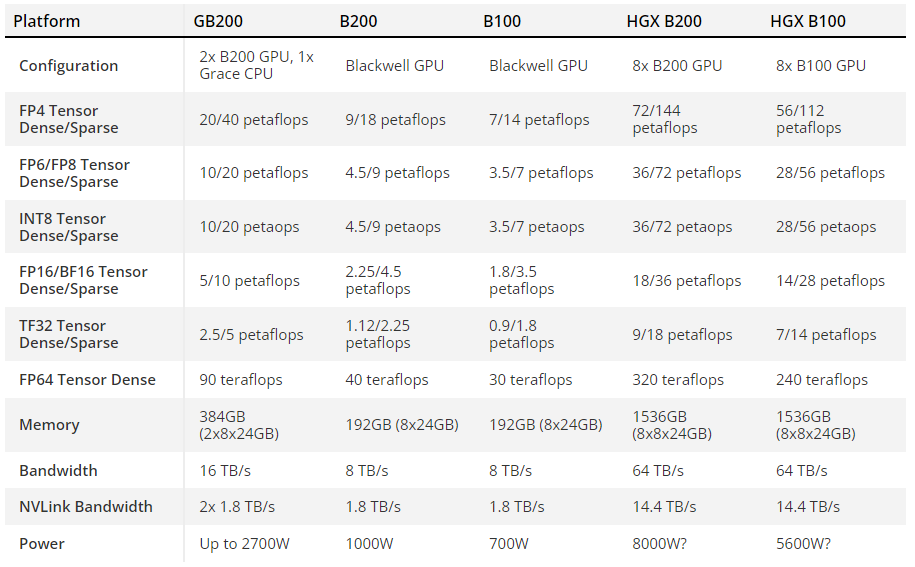
Самым большим и быстрым решением будет суперчип GB200, который состоит из двух GPU B200. Этот «монстр» имеет настраиваемый TDP до 2700 Вт — для двух чипов (объединенных четырех GPU) плюс один процессор Grace. Значения до 20 петафлопс FP4 для одного B200 — взяты для половинки суперчипа GB200. не указано, каков TDP для одного графического процессора B200.




Еще одним вариантом Blackwell является HGX B200, который базируется на использовании восьми графических процессоров B200 с процессором x86 в одном серверном узле. Они настроены на 1000 Вт на один B200, а графические процессоры обеспечивают до 18 петафлопс пропускной способности FP4 — на 10% медленнее, чем у GB200.
Еще будет чип HGX B100. та же основная конструкция, что и у HGX B200, с процессором x86 и восемью графическими процессорами B100, но он разработан для совместимости с существующей инфраструктурой HGX H100 и обеспечивает самое быстрое развертывание. TDP на графический процессор ограничен 700 Вт, как и в H100, а пропускная способность падает до 14 петафлопс FP4 на GPU. На всех трех этих конфигурациях HBM3e имеет одинаковую пропускную способность 8 ТБ/с на GPU.
NVIDIA NVLINK 7.2T
Для связи между многими узлами NVIDIA представляет пятое поколение чипов NVLink и NVLink Switch 7.2T. Новый чип NVSwitch имеет двунаправленную полосу пропускания 1,8 ТБ/с. Это чип с 50 млрд транзисторов, тоже изготовленный на техпроцессе TSMC 4NP.





Соединительный процессор почти достигает размера Hopper H100, что демонстрирует, насколько важным стало соединение после прироста вычислительной мощности и скорости данных. Предыдущее поколение поддерживало только до 100 ГБ/с пропускной способности. Новый NVSwitch обеспечивает 18-кратное ускорение по сравнению с многоузловым соединением H100.
Каждый графический процессор Blackwell оснащен 18 соединениями NVLink пятого поколения. Это в восемнадцать раз больше, чем было доступно для H100. Каждое соединение предлагает 50 ГБ/с двунаправленной полосы пропускания, или 100 ГБ/с на соединение. С такой скоростью можно говорить, что это позволяет большим группам узлов GPU функционировать так, будто они являются лишь одним массивным GPU.
NVIDIA B200 NVL72
Новые чипы с новым интерфейсом объединяются в серверы NVIDIA B200 NVL72. По сути, это полноценное стоечное решение с 18 серверами 1U, каждый из которых имеет два суперчипа GB200. Два GPU B200 идут в паре с одним CPU Grace, тогда как технология GH100 использовала меньшее решение — один CPU Grace рядом с одним GPU H100.



Каждый вычислительный узел в GB200 NVL72 имеет два суперчипа GB200, поэтому один лоток содержит два процессора Grace и четыре графических процессора B200 с производительностью 80 петафлопс FP4 AI и 40 петафлопс FP8 AI. Это серверы 1U с жидкостным охлаждением, которые занимают значительную часть стандартных 42 единиц пространства в стойке.
Кроме вычислительных панелей суперчипов GB200, GB200 NVL72 также будет иметь панели коммутаторов NVLink. Это также лотки 1U с жидкостным охлаждением, с двумя переключателями NVLink на лоток и девятью такими лотками на стойку. Каждый лоток обеспечивает 14,4 ТБ/с общей пропускной способности.
В целом GB200 NVL72 имеет 36 процессоров Grace и 72 графических процессора Blackwell с 720 петафлопсами FP8 и 1440 петафлопсами FP4. С имеющимися 130 ТБ/с многоузловой пропускной способности NVL72 может обрабатывать до 27 триллионов параметров речевых моделей ИИ. Остальные стойки предназначены для сетей и других элементов центра обработки данных.

Также представлены суперкомпьютеры SuperPOD, которые объединяют много GB200. Сейчас NVLink поддерживают до 576 доменов GPU, новые DGX SuperPOD масштабируются именно до такого количества графических процессоров GB200 Blackwell. Каждый SuperPOD может вместить до восьми систем GB200 NVL72, что соответствует 288 процессорам Grace и 576 графическим процессорам B200.
Видеокартам NVIDIA GeForce RTX 50 приписывают память GDDR7 со скоростью 28 Гбит/с и 512-битной шиной
Источник: Tom’s Hardware





Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: