

Аналіз BBC та інших європейських новинних агентств продемонстрував, що близько 45% відповідей ChatGPT та інших чатботів на основі ШІ на новинні запити містили помилки.
OpenAI, Google, Microsoft та інші техкомпанії активно підштовхують користувачів до взаємодії з ШІ-агентами під час пошуку інформації в інтернеті. Хоча розробники роками намагались мінімізувати ймовірність хибних відповідей від чатботів, результати аналізу вказують, що ШІ ще далекий від надійної стабільної роботи.
У рамках дослідження BBC та ще 22 новинних держагентства з 18 країн та на 14 мовах надали чатботам доступ до свого контенту. Були виявлені помилки майже у половині матеріалів, згенерованих ШІ, які включали спотворені речення та цитати, застарілу інформацію, а також проблеми із пошуковими алгоритмами.
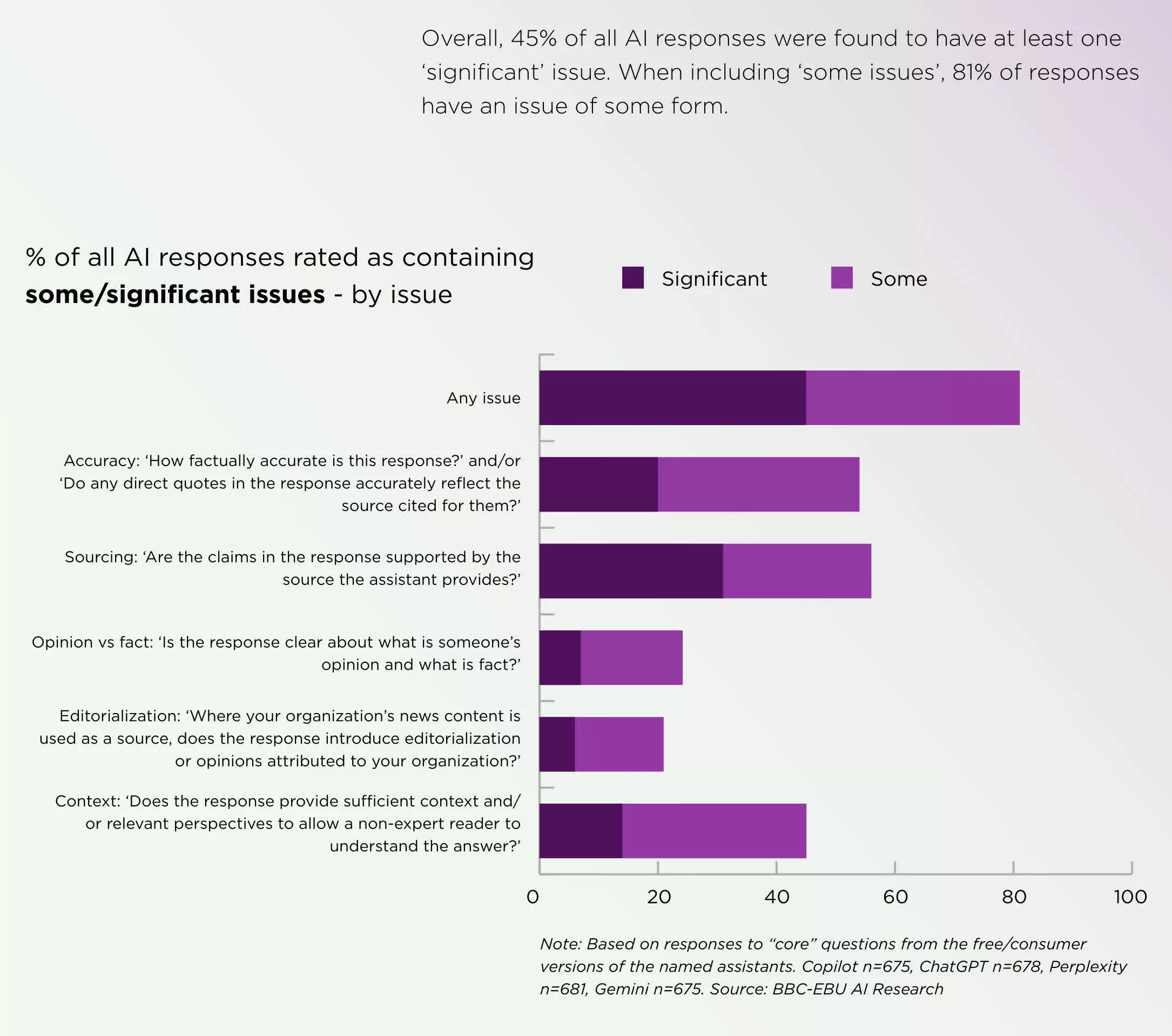
значну проблему. Якщо включити деякі інші проблеми, то 81% відповідей
мають ту чи іншу помилку/BBC
Чатботи нерідко надавали посилання, що не відповідали реальним джерелам, на які вони посилались. Навіть за точного вказування матеріалів ШІ-моделі часто не могли відрізнити думку від факту та сатиру від звичайних новин.
Окрім фактичних помилок або спотворення цитат, чатботи повільно оновлювали інформацію стосовно політики та політичних лідерів. Наприклад, ChatGPT, Copilot та Gemini помилково стверджували, що Папа Франциск є чинним Папою після того, як його змінив Лев XIV. Copilot навіть правильно вказав дату смерті Франциска, продовжуючи називати його чинним Папою. ChatGPT також видавав застарілі відповіді при згадці імен чинного канцлера Німеччини та генсека НАТО.
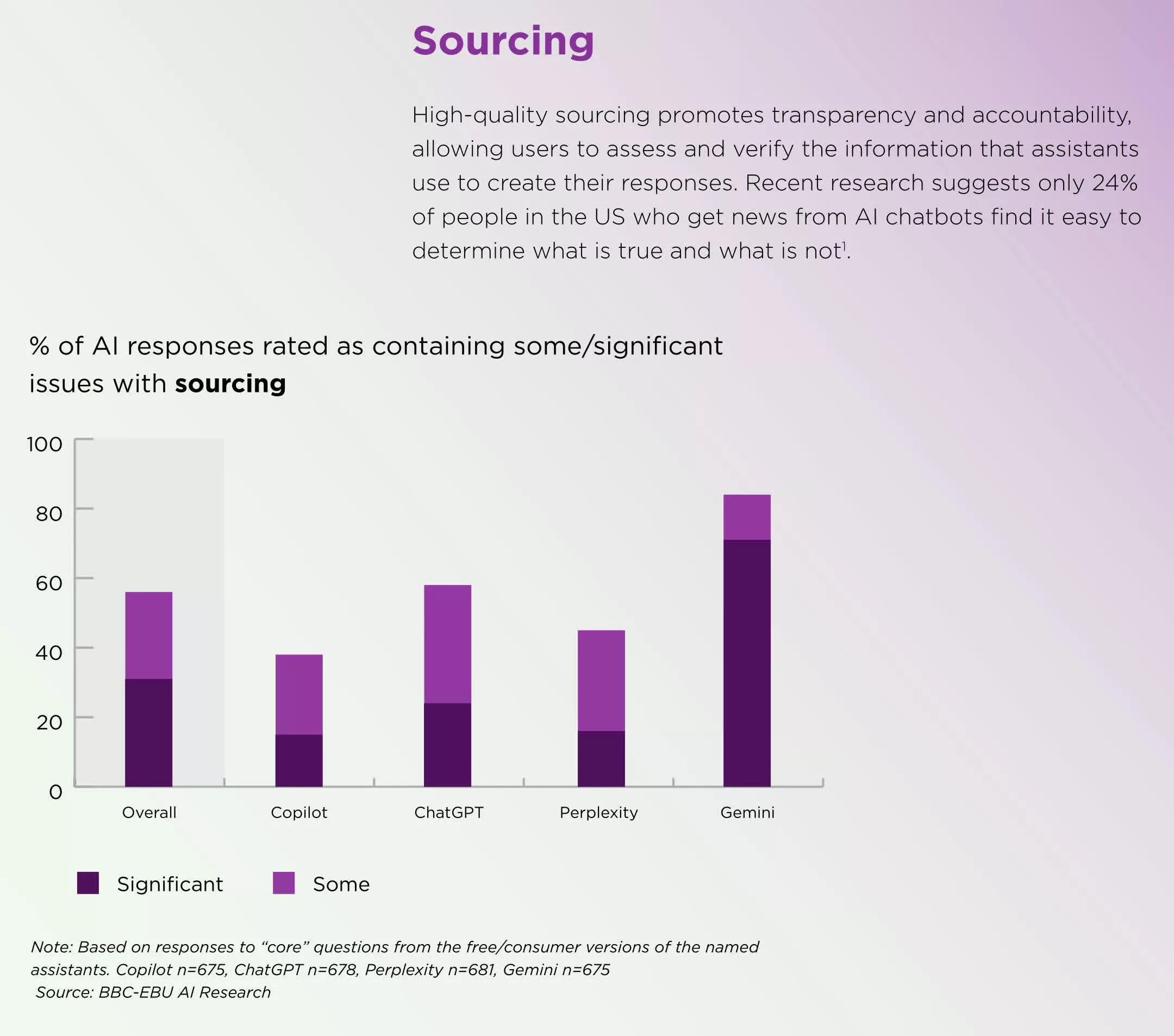
Google Gemini виявився менш точним за ChatGPT, Copilot та Perplexity. У 72% відповідей містились помилки. Колись в OpenAI пояснювали подібні помилки тим, що ранні версії ChatGPT навчалися лише на даних, актуальних до вересня 2021 року, та не мали доступу до живого інтернету. Однак наразі ситуація змінилась і теоретично подібні помилки виникати не повинні. Скоріш за все, проблема криється в алгоритмах і не може бути легко виправлена.
Пізніші результати продемонстрували покращення порівняно з дослідженням, проведеним BBC у лютому. З того часу частка відповідей із серйозними помилками знизилася з 51% до 37%, але Gemini все ще значно відстає.
Окрім цього дослідники виявили, що значна частина користувачів продовжує довіряти відповідям чатботів. Більше ніж третина дорослих британців та майже половина дорослих молодше 35 років довіряють ШІ у точному викладенні новин. Ба більше, якщо ШІ спотворює зміст ресурсу новин, 42% дорослих або покладуть провину як на ШІ, так і на першоджерело, або менше довірятимуть джерелу.





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: