

Дослідники компанії DeepSeek представили нову експериментальну модель V3.2-exp, створену для суттєвого зниження витрат на висновок під час роботи з великими обсягами контексту. Анонс з’явився на платформі Hugging Face, а також виклали пов’язану наукову статтю з описом системи на GitHub.
Ключовою особливістю нової моделі є система DeepSeek Sparse Attention, складний механізм, детально показаний у схемі нижче. Суть у тому, що використовується модуль під назвою “швидкісний індексатор”, який пріоритезує окремі фрагменти вікна контексту. Після цього інша підсистема — “система точного відбору токенів” — відбирає конкретні токени з цих фрагментів для завантаження у обмежене вікно уваги модуля. У поєднанні ці механізми дозволяють моделям Sparse Attention ефективно працювати з великими фрагментами контексту при відносно невеликому навантаженні на сервери.
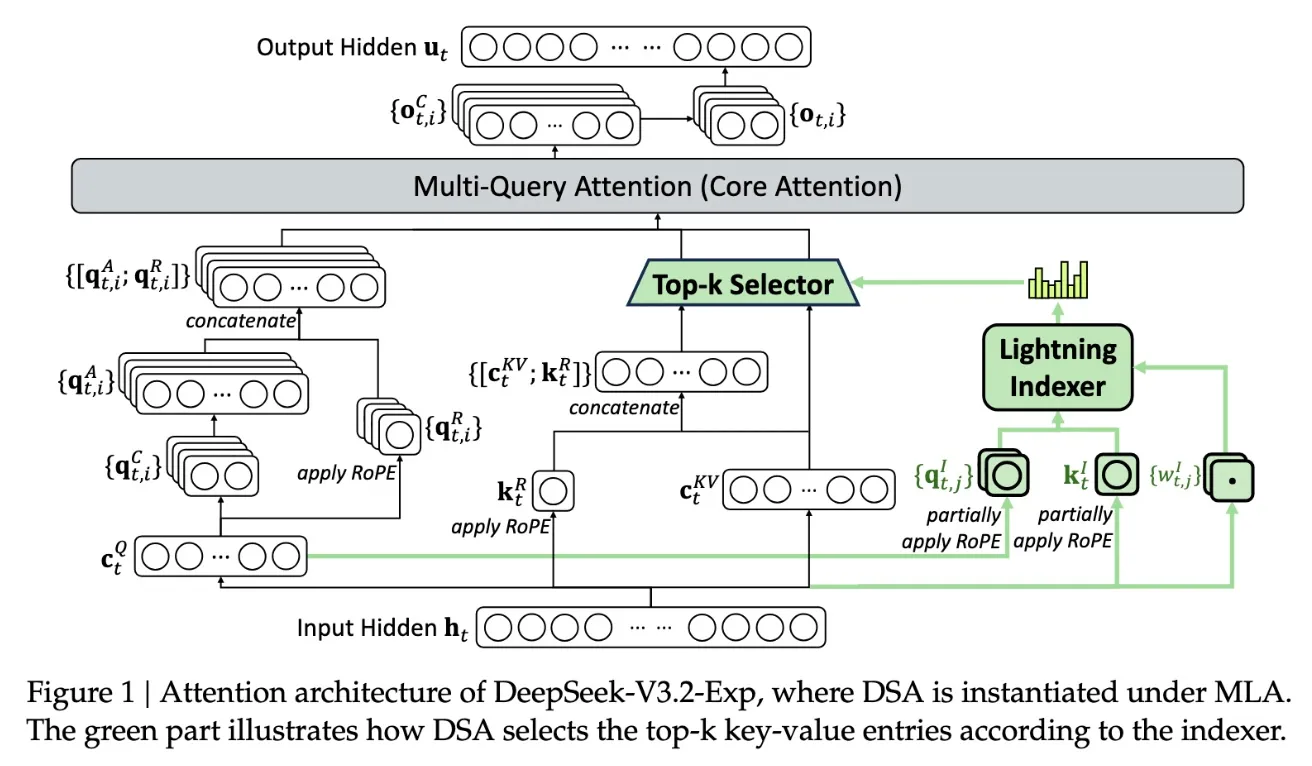
У довгоконтекстних завданнях переваги такого підходу особливо помітні. Попереднє тестування DeepSeek показало, що ціна звичайного API-запиту може скорочуватися майже удвічі, коли йдеться про роботу з великим контекстом. Хоча для отримання остаточних висновків потрібні подальші дослідження, відкритість ваг моделі та її доступність на Hugging Face дозволять стороннім експертам швидко перевірити заявлені результати.
Нова модель DeepSeek є частиною низки проривів у сфері оптимізації вартості висновку — тобто витрат на роботу вже натренованої ШІ-моделі, що відрізняється від високих витрат на етапі її навчання. У цьому випадку дослідники прагнули змусити базову трансформерну архітектуру працювати ефективніше, і, за їхніми словами, потенціал для покращення тут дійсно значний.
Компанія DeepSeek, що базується у Китаї, має особливе становище на ринку ШІ, особливо на тлі сприйняття цієї галузі як конкурентної боротьби між США та Китаєм. На початку року компанія привернула увагу до себе моделлю R1 (яка збирає безліч даних користувача та викривляє інформацію про Китай), навченою переважно за допомогою методів навчання з підкріпленням та при цьому з набагато меншими витратами, ніж у американських конкурентів. Втім, очікуваного прориву в методах навчання R1 не спричинила, і за останні місяці DeepSeek відійшла від загальної уваги.
Новий підхід Sparse Attention, швидше за все, не викличе такого ж ажіотажу, як R1. Але він може стати важливим уроком для американських компаній, які намагаються знизити витрати на висновок і зробити роботу своїх моделей більш економною.
Джерело: techcrunch





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: