
Велика мовна модель (LLM) Claude 3 Opus від Anthropic вперше перевершила GPT-4 від OpenAI на Chatbot Arena.
«Король мертвий», — написав у X (Twitter) розробник ПЗ Нік Добос у дописі, в якому порівнював GPT-4 Turbo та Claude 3 Opus.
The king is dead
RIP GPT-4
Claude opus #1 ELoHaiku beats GPT-4 0613 & Mistral large
That’s insane for how cheap & fast it is https://t.co/XWmvTE6h75 pic.twitter.com/fAwzJScLTH— Nick Dobos (@NickADobos) March 26, 2024
Chatbot Arena – це краудсорсингова відкрита платформа для оцінювання великих мовних моделей. Для складання рейтингу оцінюється велика кількість людських відгуків про роботу моделей за системою рейтингу Ело. Як працює тест — люди вводять запит та обирають кращу відповідь з кількох варіантів від різних моделей. На основі тисяч користувацьких тестів формується і ранжирується топ.
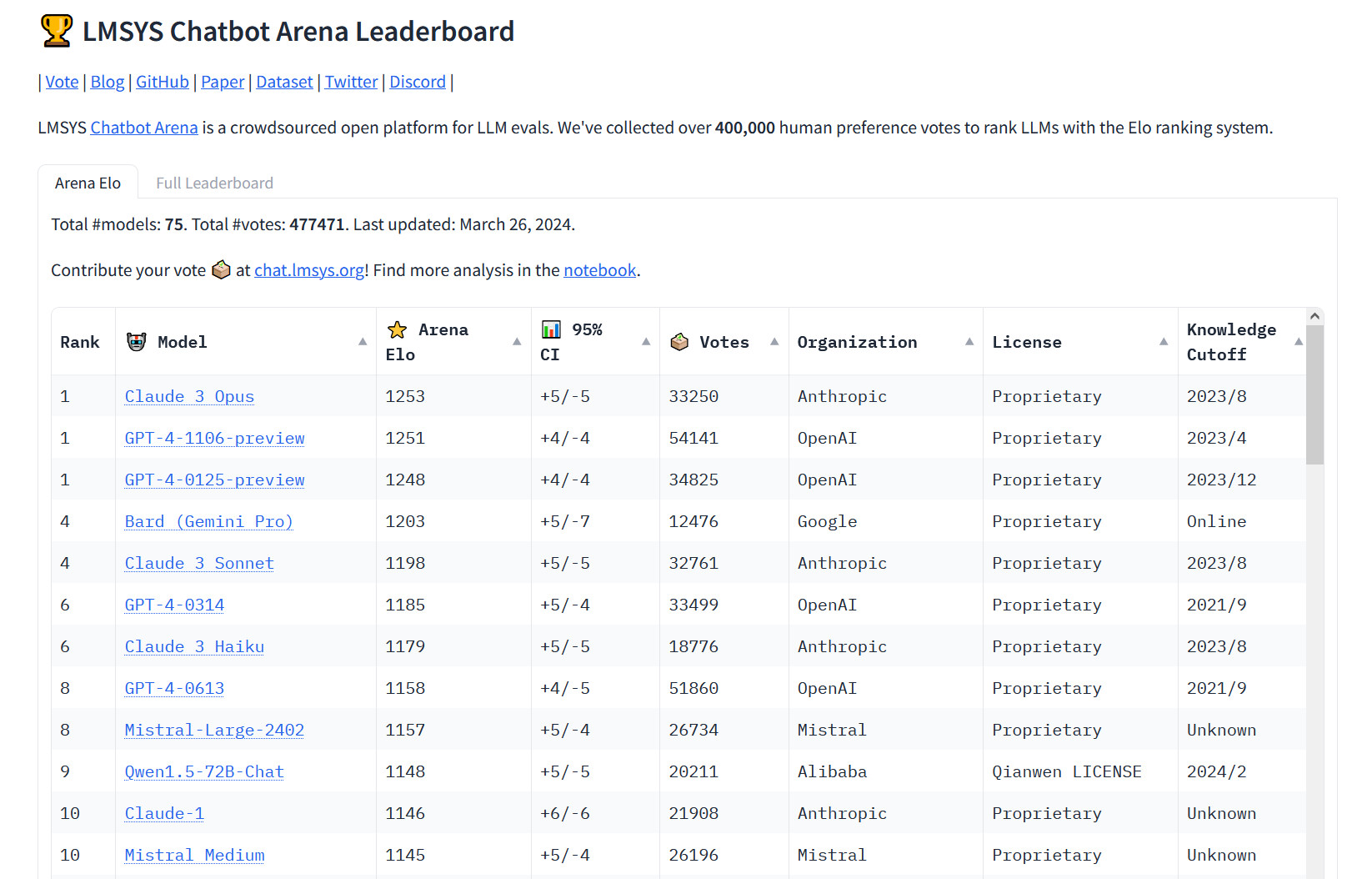
Таблицю лідерів Chatbot Arena було запущено 3 травня 2023 року, а GPT-4 було включено в рейтинг 10 травня. З того часу різні варіації GPT-4 незмінно перебували на вершині рейтингу. Дотепер. Тому поява нового лідера в цій сфері привертає до себе увагу. Ба більше, одна з менших моделей Anthropic, Haiku, також привернула увагу своєю продуктивністю в таблиці лідерів.
«Вперше найкращі доступні моделі — Opus для складних завдань, Haiku для економії та ефективності — доступні від постачальника, який не є OpenAI», — сказав незалежний дослідник ШІ Саймон Віллісон. «Це заспокоює — ми всі отримуємо вигоду від різноманітності провідних постачальників у цій сфері. Але GPT-4 на цей час існує понад рік, і цей рік знадобився, щоб хтось наздогнав її».
Слідом за Claude 3 Opus та двома версіями GPT-4 в рейтингу розмістилася модель Bard (Gemini Pro) від Google. Проте, якщо між першими трьома позиціями різниця в балах Ело незначна (2-3 бали), то Bard відстає від третього місця вже на 45 балів. Всі інші конкуренти набрали менш ніж 1200 балів.
Джерело: arstechnica





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: