

Коли наприкінці минулого року Google випустила Gemini 3 Pro, це стало значним кроком для великих LLM компанії. Тепер компанія переносить частину тих самих технологій, що зробили ці моделі можливими, у відкрите середовище з новим сімейством відкритих моделей — Gemma 4.
Google пропонує чотири різні версії Gemma 4, що відрізняються кількістю параметрів. Для периферійних пристроїв, зокрема смартфонів, компанія підготувала 2-мільярдну та 4-мільярдну “Effective”-моделі. Для потужніших машин — 26-мільярдну систему “Mixture of Experts” та 31-мільярдну “Dense”.
Для тих, хто не знайомий з темою: параметри — це налаштування, які велика мовна модель може змінювати для генерації відповіді. Як правило, моделі з більшою кількістю параметрів дають кращі результати, однак для їх запуску потрібне й більш потужне залізо.
“Із Gemma 4 нам вдалося розробити системи з безпрецедентним рівнем інтелекту на параметр”, — стверджує Google.
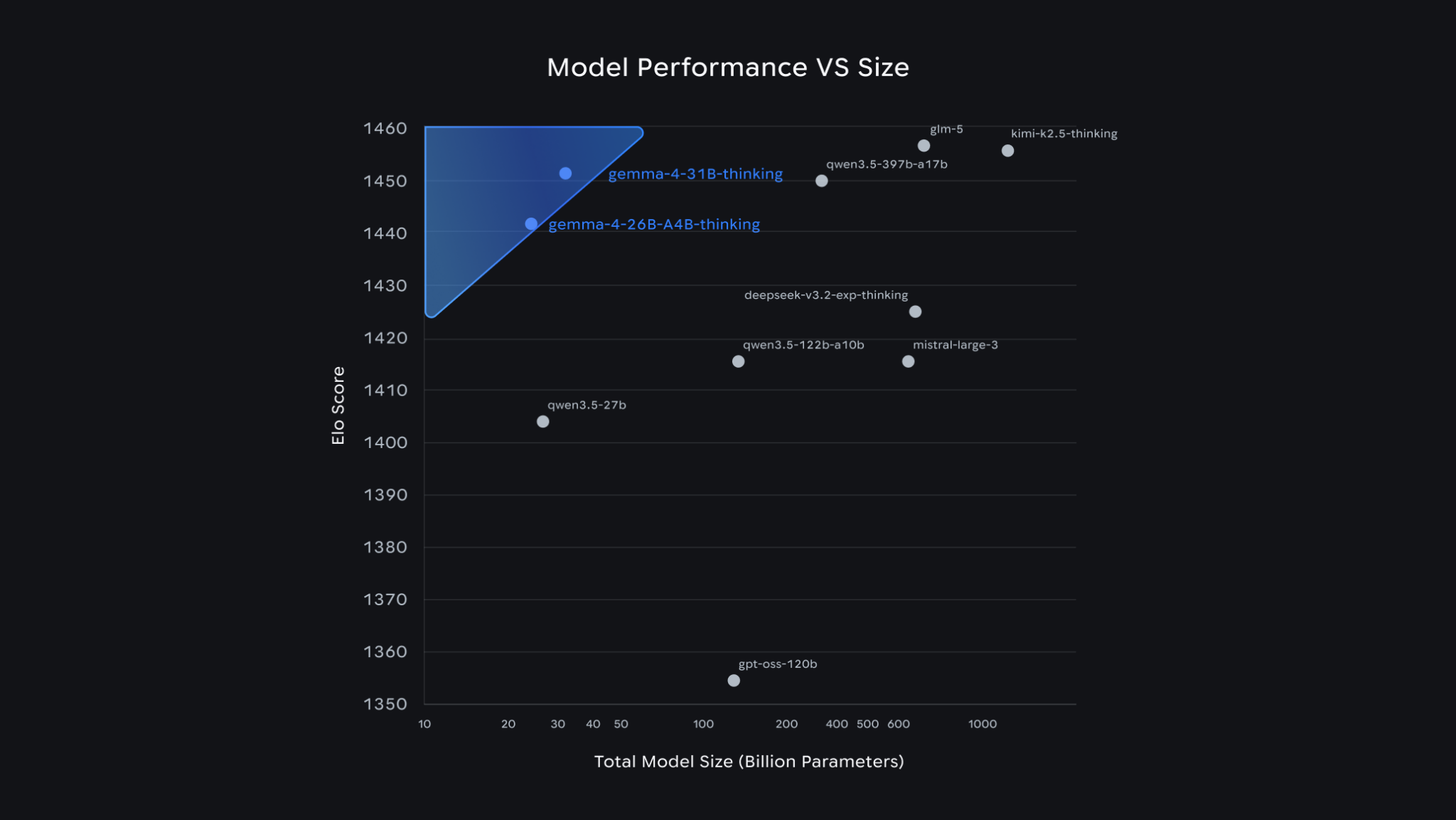
На підтвердження цього компанія посилається на результати 31-мільярдного та 26-мільярдного варіантів Gemma 4, які посіли третє і шосте місця відповідно в текстовому рейтингу Arena AI, випередивши моделі, що у 20 разів більші за розміром. Усі моделі можуть обробляти відео та зображення, що робить їх ідеальними для завдань на кшталт оптичного розпізнавання символів. Дві менші моделі також здатні обробляти аудіовходи й розуміти мовлення.
Окремо Google зазначає, що сімейство Gemma 4 здатне генерувати код в офлайн-режимі — тобто вайб-кодингом можна займатися без підключення до інтернету. Крім того, Google навчила моделі більш ніж 140 мовами.
Google випускає сімейство Gemma 4 під ліцензією Apache 2.0. Попередні моделі Gemma компанія надавала через власну ліцензію Gemma. Цей крок дасть людям значно більше свободи в адаптації нових систем під свої потреби.
“Ця ліцензія з відкритим кодом забезпечує основу для повної гнучкості розробників і цифрового суверенітету; надаючи вам повний контроль над вашими даними, інфраструктурою та моделями. Вона дозволяє вільно будувати та безпечно розгортати продукти в будь-якому середовищі — як у власній інфраструктурі, так і в хмарі”, — заявила Google.
Якщо ви хочете спробувати одну із систем самостійно, ваги моделей доступні через Hugging Face, Kaggle та Ollama. Два великі варіанти Gemma 4 — 26B Mixture of Experts та 31B Dense — розраховані на запуск без квантизації у форматі bfloat16 на одному GPU NVIDIA H100 з 80 ГБ відеопам’яті. При квантизації до нижчої точності ці моделі помістяться на споживчих відеокартах.
Google також зосередилася на зниженні затримки: модель 26B MoE активує лише 3,8 млрд із 26 млрд параметрів у режимі inference, що забезпечує значно вищу швидкість генерації токенів порівняно з моделями аналогічного розміру. Модель 31B Dense орієнтована скоріше на якість, ніж на швидкість, — Google очікує, що розробники донавчатимуть її під конкретні завдання.
Моделі Effective 2B та Effective 4B для мобільних пристроїв розроблялися командою Pixel у тісній співпраці з Qualcomm і MediaTek. Вони оптимізовані не лише для смартфонів, а й для таких пристроїв, як Raspberry Pi та Jetson Nano. Порівняно з Gemma 3 вони споживають менше пам’яті й енергії, а Google заявляє про “майже нульову затримку”.
Окрім мультимодальності та генерації коду, Gemma 4 готова до агентних сценаріїв використання: моделі підтримують нативний виклик функцій (function calling), структурований вивід у форматі JSON, а також вбудовані інструкції для роботи з популярними інструментами та API. Контекстне вікно для моделей E2B та E4B тепер становить 128 тисяч токенів, а для 26B і 31B — 256 тисяч. Для хмарних моделей Gemini цей показник залишається значно більшим — 1 мільйон токенів.
Зміна ліцензії з власної Gemma на Apache 2.0 може виявитися навіть важливішою за технічні покращення. Ліцензія Gemma 3 містила суворі обмеження на використання, які Google могла оновлювати в односторонньому порядку; вона зобов’язувала розробників дотримуватись правил Google в усіх проєктах на основі Gemma і потенційно поширювалася навіть на моделі, навчені на синтетичних даних, згенерованих Gemma.
Apache 2.0 не має подібних обтяжливих умов і комерційних обмежень. Google також уперше підтвердила існування Gemini Nano 4 — наступного покоління мінімальної моделі штучного інтелекту для смартфонів. Нинішній Gemini Nano 3 у телефонах Pixel базується на Gemma 3n; Nano 4 матиме варіанти на 2B і 4B параметрів на основі Gemma 4 E2B та E4B відповідно.
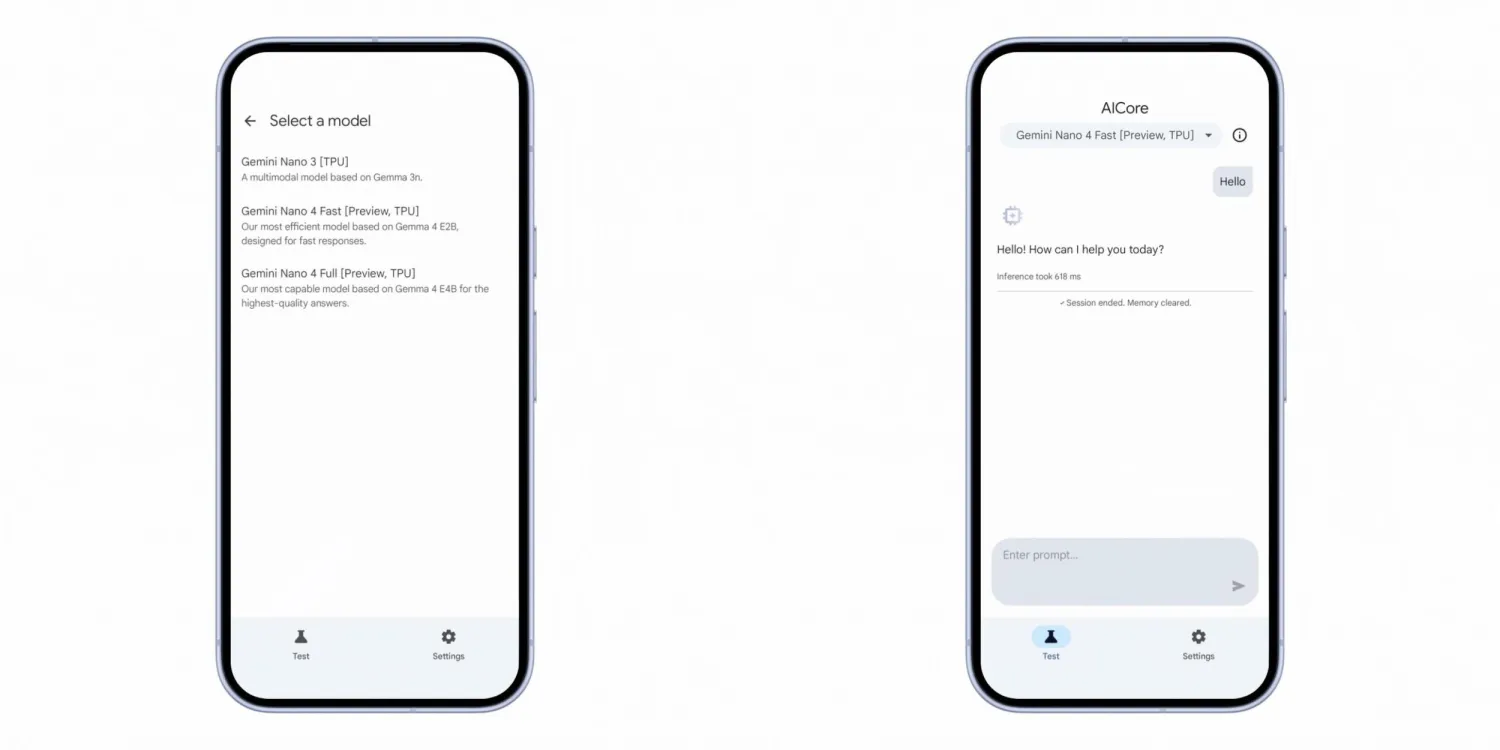
Розробники вже можуть прототипувати агентні сценарії з Gemma E2B та E4B у рамках AI Core Developer Preview — проєкти, створені на цих моделях, будуть сумісні з Gemini Nano 4 після його виходу. Детальніше про це Google може розповісти на конференції I/O, яка відбудеться за кілька тижнів.
Gemini Nano 4 існуватиме у двох версіях. Nano 4 Fast базується на Gemma 4 E2B і оптимізований для максимальної швидкості та мінімальної затримки — він працює втричі швидше за версію на базі E4B. Nano 4 Full базується на Gemma 4 E4B і розрахований на складніші завдання, де важливіша якість відповіді, а не швидкість.
Порівняно з попередніми версіями Gemini Nano 4 працює до чотирьох разів швидше та споживає до 60% менше заряду батареї. Google раніше позначала моделі як “nano-v2” і “nano-v3” — остання вже доступна на Pixel 10 та Galaxy S26. Серед конкретних покращень Nano 4 Google виділяє кілька ключових сценаріїв. У сфері міркувань модель тепер краще обробляє ланцюгові команди та умовні конструкції — наприклад, може автоматично перевіряти коментарі на відповідність правилам спільноти та повертати структурований результат із зазначенням причини порушення.
Математичні здібності також покращилися: модель точніше відповідає на практичні розрахункові запити. Окремо вдосконалено розуміння часу — Nano 4 точніше працює зі сценаріями, що включають календарі, нагадування та будильники. Офіційний запуск Gemini Nano 4 відбудеться на нових флагманських Android-пристроях пізніше цього року.
Важливо, що код, написаний сьогодні для Gemma 4, автоматично працюватиме на пристроях із Gemini Nano 4 без жодних змін. Протягом періоду попереднього перегляду Google планує додати підтримку виклику інструментів, структурованого виводу, системних промптів і режиму “thinking” у Prompt API.
Google представила Gemma 3 — найпотужнішу в світі модель ШІ для запуску на одній відеокарті
Джерело: Engadget





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: