Прежде всего, позвольте воспользоваться случаем и отрекомендовать забавный сервис от отечественного производителя: Cachescope.
Сопроводительный текст гласит:
"Гугл выдал ссылку на измененную или недоступную страницу? Хорошо, если имеется доступ к кэшу поисковой системы. Если же такого доступа нет, то вам не повезло: в этом случае доступным оказывается лишь крошечный фрагмент искомого текста, отображаемый в окне с результатами поиска. Впрочем, Сachescope шлёт вам луч надежды! Испробуйте наш сервис, реализующий алгоритмы глубокого зондирования кэша Google."
Под алгоритмом глубокого зондирования понимается, очевидно, рекурсивный скрипт, использующий фрагменты найденного текста в качестве строки для нового поискового запроса и так далее.
К примеру, часть окна с выдачей результатов поиска может выглядеть так:
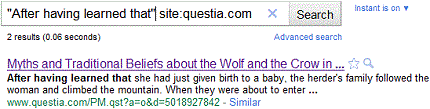
Обратите внимание на отсутствие ссылки "Cached", обычно завершающей текстовые фрагменты (вероятно, вызванное наличием в HTML-коде проиндексированной страницы строки <META HTTP-EQUIV="CACHE-CONTROL" CONTENT="NO-CACHE">, указывающей на нежелание администрации questia.com мириться с дуплицированием своей информации на серверах поисковых служб).
Введя в текстовые поля Cachescope "After having learned that" и "www.questia.com", вы получите более полный фрагмент текста, а имено: "After having learned that she had just given birth to a baby, the herder’s family followed the woman and climbed the mountain. When they were about to enter the cave, a crow flew out of the opening and a wolf came running out. "Surely . the crow has pecked out the child’s eyes and the wolf has eaten it," they said, and went to the bottom of the cave. There they discovered the baby with a drop of milk on his lips as if he had just drunk its mother’s milk. His eyes were wide open and it seemed as if he had a full stomach. This child who had been cared for by a wolf and a crow was the Lama Jiambel Jongdui, who was famous in the area." (естественно, в силу разрушения содержимого кеша Google по мере его устаревания, результаты ваших экспериментов с данным поисковым запросом могут оказаться иными).
К упомянутому в сопроводительном тексте сочетанию обстоятельств, делающих сервис полезным (и без того многочисленных), очевидно, следует добавить еще одно: "на обозримых просторах интернета нет иных страниц, позволяющих получить искомый текст безо всяких ухищрений". Т.о., Cachescope относится к сервисам, востребуемым в столь редкостных ситуациях, что, возможно, вам он и вовсе никогда не понадобится. И все же согласитесь: в случае, если он вам все же понадобится, лучше, чтобы ссылка на него была под рукой (если в вашем дереве закладок имеется фолдер с названием вроде "exotic surfhacks", то там ей — самое место).
Еще один инструмент нетрадиционного обращения с текстовыми данными Google организован пару месяцев назад самой Google при участии Гарвардского Университета: насколько полезен проект Books Ngram Viewer — трудно сказать, но затягивает он не меньше "тетриса". Он представляет собой нечто вроде экстраполяции сервиса Google Trends www.google.com/trends в область печатных изданий и позволяет строить графики изменения относительной частоты упоминания интересующих пользователя слов и словосочетаний с течением времени, начиная чуть ли не с зари книгопечатания. Поиск ведется в текстах на англ., нем., фр., исп., кит., русском и иврите, хранимых в виртуальном книгохранилище Google Books.
Точнее сказать, не в самих этих текстах, а в списках энграмм, полученных в результате их преобразования. На арго разработчиков энграмма это просто-напросто словосочетание, состоящее из энного количества слов (напр., "Ленин" — монограмма, "Компьютерное Обозрение" — биграмма, и т.д.).
Желающие поэкспериментировать со списками энграмм самостоятельно, вольны их скачать в форме множества обычных текстовых файлов, строки которых отформатированы следующим образом:
энграмма TAB год TAB количество_упоминаний TAB количество_страниц TAB количество_томов
Вот выдержка из перечня русских 5-грамм (как видите, знаки препинания считаются в энграммах отдельными словами):
…
. « Теперь мне все 1950 1 1 1
. « Теперь мне все 1951 3 3 3
…
? Какой угрюмый дурак станет 1989 1 1 1
? Какой угрюмый дурак станет 1990 2 2 2
? Какой угрюмый дурак станет 1993 1 1 1
? Какой угрюмый дурак станет 1995 1 1 1
? Какой угрюмый дурак станет 1997 1 1 1
? Карамзин ? но Карамзин 1949 2 2 2
? Карамзин ? но Карамзин 1950 3 3 3
…
в жизни нашего государства и 1999 1 1 1
в жизни нашего государства и 2000 5 5 5
в жизни нашего государства и 2001 1 1 1
в жизни нашего государства и 2004 2 2 2
…
— въезжает в город он 1924 1 1 1
— въезжает в город он 1937 1 1 1
— въезжает в город он 1939 1 1 1
— въезжает в город он 1940 3 3 3
…
Имейте ввиду, что общий размер текстовых файлов в разархивированном виде составляет по моим поверхностным оценкам несколько сот гигабайт.
Важный вопрос, стоящий перед всяким пользователем сервиса касается степени зависимости формы наблюдаемых графиков с одной стороны от изменений, происходящими с объективной актуальностью описываемых поисковой строкой понятий, с другой — от конъюнктурно-политических и прочих субъективных факторов, а с третьей стороны — от изменений, происходящих с языком. Конечно, в этих явлениях много общего и границы меж ними размыты, однако, путать их нельзя. К примеру, широкие скачки в графике употребления слова "шизофрения" в течение XX в. никак не связаны с распространенностью этого заболевания (которая, как говорят медики, составляет на редкость стабильную константу). Скорее всего, с отношением общества к шизофреникам и продуктивности психиатров, специализирующихся на изучении шизофрении у этих скачков тоже связи немного. Скорее всего, эти скачки гл. обр. отражают распространенность практики обиходного использования слова "шизофрения" (напр., в шутливом или ругательном смысле).
Эволюция языка представляется принципиально новым фактором, непривычным для пользователей традиционных поисковых сервисов, доселе имевших дело с электронными публикациями, возраст которых по лингвоисторическим меркам покамест пренебрежимо мал. Можно предположить, что в ходе предстоящего поисковым сервисам развития им помимо привычых функций межъязыкового перевода придется обзавестись функцией перевода с современого русского на русский 100-летней давности, позуоляющей приводить поисковые строки в соответствиии стандартам начала ХХ в. и т.о. улучшить качество текстового поиска в тогдашних документах.
Поп-блоггеры окрестили построитель графиков энграммоумотребления инструментом исследования "периода полураспада звезд", — т.е., характера флуктуаций интенсивности общественного внимания, уделяемого знаменитостям. Как видно из этого примера, звезды мерцают очень по-разному. Интересно сравнивать интенсивность внимания, уделяемого "звездам" современниками и потомками: превалирование второго показателя, вероятно, указывает на талант, опережающий время.
Примечательно, что графики популярности большинства американских "звезд" (из пришедших мне на ум), — да и многих вполне обыденных понятий, — характеризуются заметным спадом в области конца 1950-х — начала 1960 гг. Похоже, что в это время американцам было не до развлечений, и их обычные интересы вытеснялись из СМИ какими-то другими заботами. Какими же? Одна из них была обнаружена мною по прошествии примерно часа неудачных экспериментов (как же я раньше не догадался?!); буду признателен читателям за другие комментарии к странному "провалу 1960-го года".
В заключение прошу взглянуть на график, собственно говоря, побудивший меня к написанию этого поста.
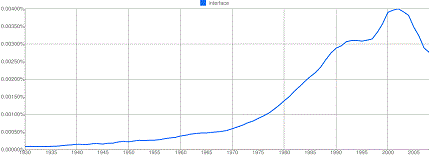
Он свидетельствует о том, что в сравнении с 2003 г. частота упоминания слова "interface" упала почти вдвое. Сейчас этот показатель находится где-то на уровне четвертьвековой давности. Т.е., на уровне времен гегемонии IBM PC XT. И это несмотря на чуть ли не ежемесячное появление сообщений о революционных интерфейсах от Nintendo, Apple и Microsoft; на разговоры о скором вымирании компьютерных мышек и клавиатур и на общее впечатление о перемещении основного упора в конкурентной борьбе меж производителями гаджетов с вычислительной мощности на оригинальность и привлекательность интерфейсов.
Знакомый функционер из немецкого филиала IBM, с самозабвением культиста пропагандирующий облачные вычисления, утверждает, что это парадоксальное явление вызвано тем, что слово "interface" употребляется-де преимущественно в составе словосочетания "man-machine interface", теряющим актуальность по мере того, как пользователи все меньше взаимодействуют с компьютерами, и все больше — с Сетью. Не могу подыскать смайлика, отражающего смехотворность этой гипотезы.
Может быть, дело в том, что обсуждение интерфейсов привлекает преимущественно технически продвинутую часть населения, презирающую "dead-tree publishing" и предпочитающую взаимодействовать с современными электронными изданиями? В ошибочности этого предположения легко убедиться, взглянув на этот ниспадающий график https://www.google.com/trends?q=interface.
Полагаю, ярко выраженный спад интереса к интерфейсам после 2003 года вызван, гл. обр., характерным для минувшего десятилетия изменением отношения массового пользователя к компьютерам, которые все более воспринимаются как всего лишь одна из разновидностей бытовой техники. А с потребителями бытовой техники говорить об интерфейсе неуместно (ср. "интерфейс кофемолки", "интерфейс холодильника"). В этом смысле крах "Компьютерного Обозрения", в каждом номере которого слово "интерфейс" употреблялось по нескольку раз, неизбежен и закономерен.





Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: