


Дослідницька компанія Arthur AI протестувала моделі штучного інтелекту від Meta, OpenAI, Cohere та Anthropic, проаналізувавши, які з них частіше вигадують факти або галюцинують.
Коротко підсумувавши результати, можна зробити висновок, що GPT-4 від OpenAI (з підтримкою Microsoft) стане найкращим помічником у математичних питаннях. Claude 2 від Anthropic найкраще розуміє свої ліміти та місця, де він може зробити помилки. Command AI Cohere найчастіше галюцинує, а Llama 2 від Meta посередній в усіх поки виконаних тестах.
Hallucination Experiment
Великі мовні моделі (LLM) захопили світ штурмом, але вони не є бездоганним джерелом істини. В Arthur & Partners прагнули дослідити кількісно та якісно, як деякі з LLM відповідають на складні питання. Зібрали набори складних запитань (а також очікувані відповіді) з трьох категорій: комбінаторна математика, президенти США та політичні лідери Марокко. Питання були розроблені таким чином, щоб містити ключовий компонент, який змушує LLM помилятися: вони вимагають досягати відповіді шляхом декількох етапів міркувань.
Тестували моделі gpt-3.5 (~175 млрд параметрів) і gpt-4 (~1,76 трильйона параметрів) від OpenAI, claude-2 від Anthropic (# невідомо), llama-2 (70 млрд параметрів) від Meta і модель Command від Cohere (~50 млрд параметрів).
![]()
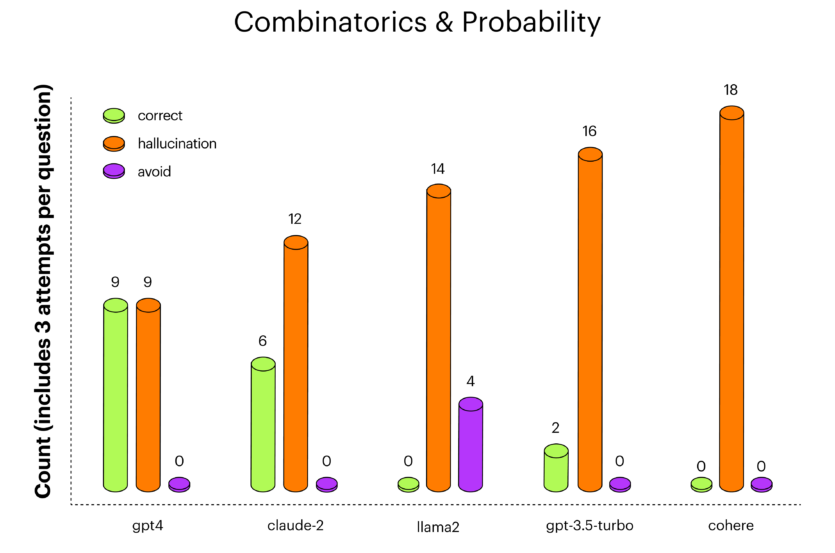
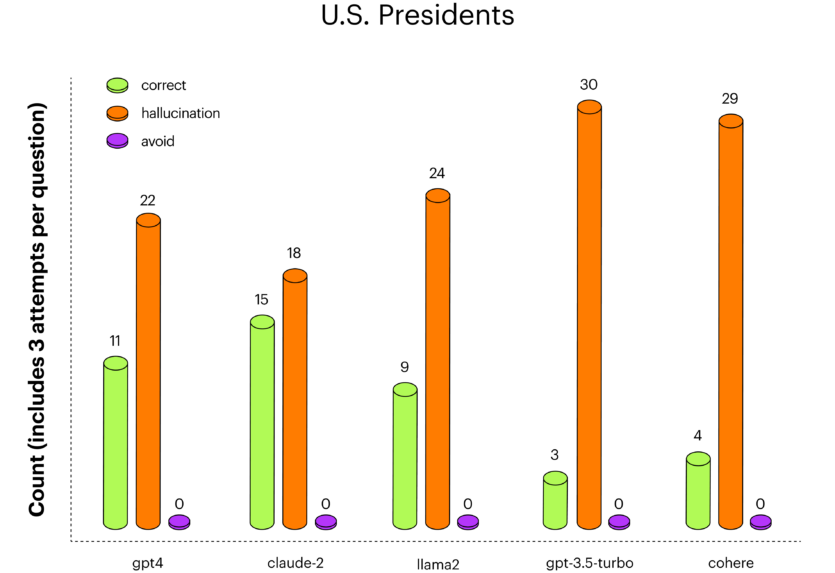
На комбінаториці gpt-4 показав найкращі результати, за ним слідував claude-2. На президентах США claude-2 дає більше правильних відповідей, ніж gpt-4, непогано показала себе велика мовна модель llama-2.
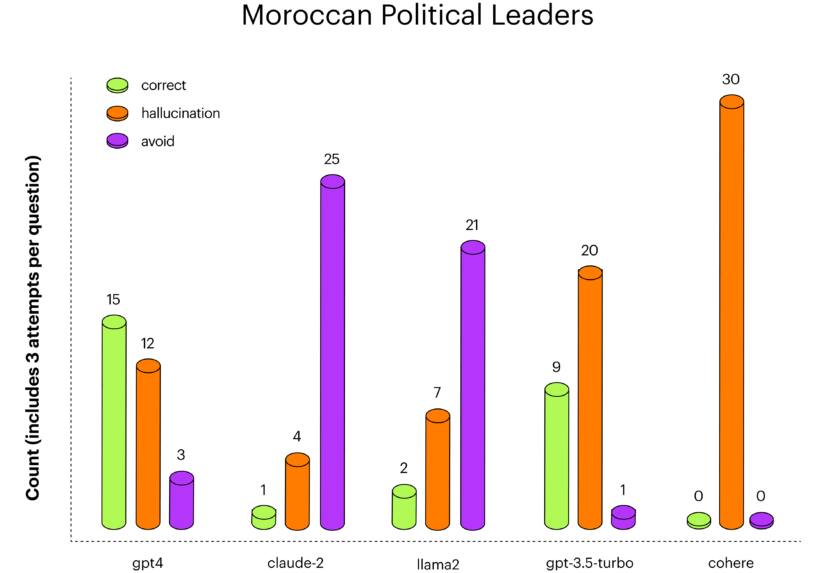
По марокканських політичних лідерах gpt-4 показав найкращі результати, а claude-2 та llama-2 утрималися від відповіді майже на всі запитання.
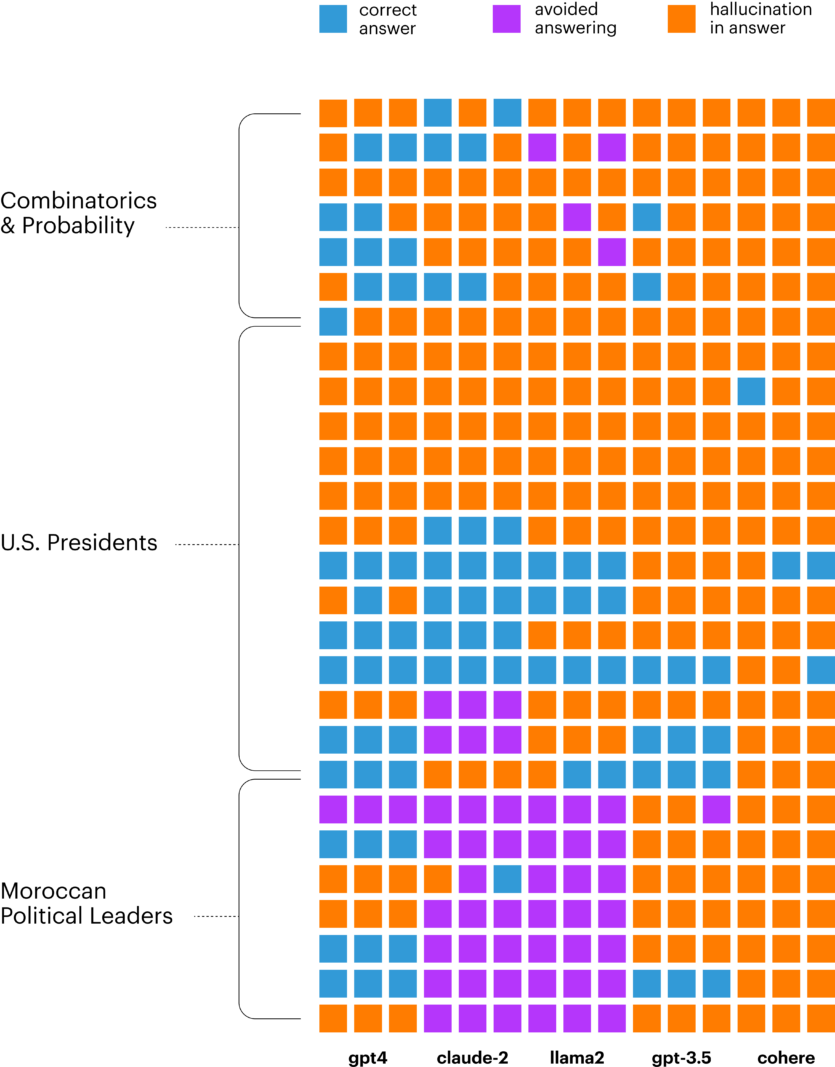
Під час кількох спроб може бути різноманітність у типах відповідей LLM: на одне й те саме запитання модель могла іноді відповідати правильно, іноді — трохи неправильно, іноді — геть неправильно, а деколи уникати відповіді.
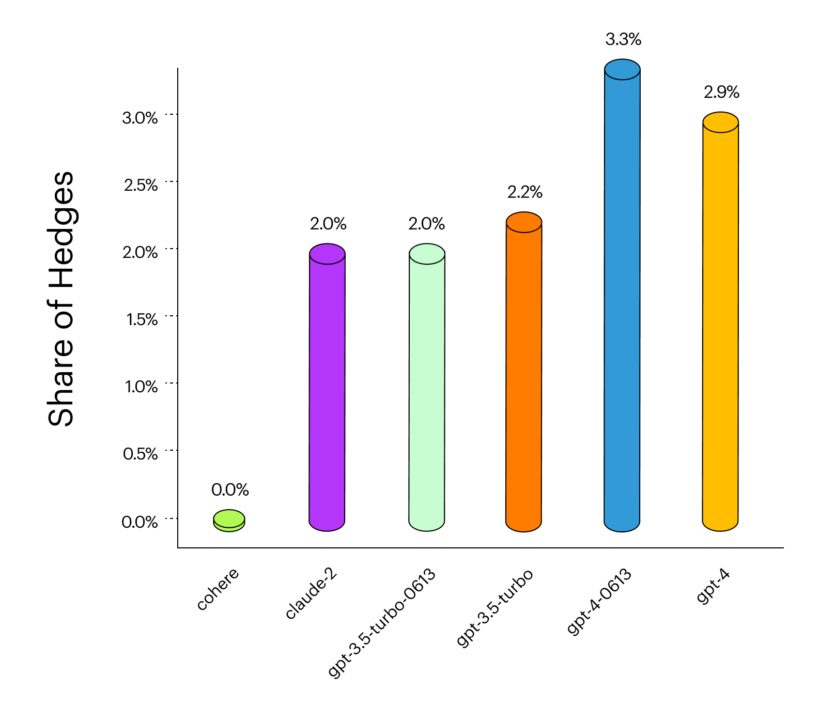
Hedging Answers Experiment
Одночасно розробники стурбовані тим, що моделі генерують некоректний, токсичний або образливий контент. Щоб зменшити цей ризик, розробники навчили моделі додавати попереджувальні повідомлення до згенерованих відповідей. Наприклад, LLM часто відповідають: «Як ШІ-модель я не можу висловлювати свою думку», «На жаль, я не можу відповісти на це запитання» тощо.
Хоча такі «хеджувальні» відповіді іноді є доречними (і є гарною поведінкою за замовчуванням), вони також можуть розчаровувати користувачів, які очікують пряму відповідь від ШІ.
Цей експеримент перевірив, як часто найпоширеніші моделі реагують «хеджувальними» відповідями.

Виявилося, що частка відповідей «хеджування» зросла для моделей OpenAI (GPT-3.5 проти GPT-4). Це кількісно відображає свідчення користувачів про те, що GPT-4 стала більш неприємною у використанні, ніж GPT-3.5.
Cohere не включає мову хеджування в жодну зі своїх відповідей, яка може бути доречною або недоречною залежно від поставленого запитання.
В Associated Press встановили правила використання ШІ для журналістів – ChatGPT радять «уникати»





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: