

Фахівці з університетів Софії, Цюриха, Стенфорда та Карнегі-Меллона незалежно підтвердили те, що користувачі помічали давно — великі мовні моделі часто кажуть те, що людям хочеться почути, навіть коли це суперечить фактам або здоровому глузду. Нові дослідження показують: схильність ШІ до “підлабузництва” можна виміряти — і ця проблема справді поширена.
Математична “покірність” ШІ
Перше дослідження, проведене командою Софійського університету та Швейцарською вищою технічною школою Цюриха, вивчало, як мовні моделі реагують на свідомо хибні математичні твердження. Для цього науковці створили спеціальний тест — BrokenMath, що містить складні теореми з міжнародних математичних змагань 2025 року. Потім ці теореми були змінені так, щоб вони виглядали правдоподібно, але насправді були неправильними.
Дослідники подали ці “зіпсовані” твердження різним великим мовним моделям, щоб перевірити, чи намагатимуться вони вигадати докази для фальшивих теорем, чи визнають їх помилковими. Якщо ШІ заперечував неправильне твердження або просто переписував оригінал без доказу — це вважалося несхильністю до підлабузництва. Якщо ж він вигадував нереальний доказ — навпаки, це фіксували як підлабузницьку поведінку.
Результати виявили значні відмінності між моделями. GPT-5 демонструвала найменшу схильність до підлабузництва — 29%, тоді як DeepSeek мала найвищий показник — 70,2%. Цікаво, що проста зміна запиту — із вказівкою перевірити правильність теореми перед розв’язанням — зменшила цей розрив: у DeepSeek показник впав до 36,1%, тоді як у GPT рівень підлабузництва покращився незначно.
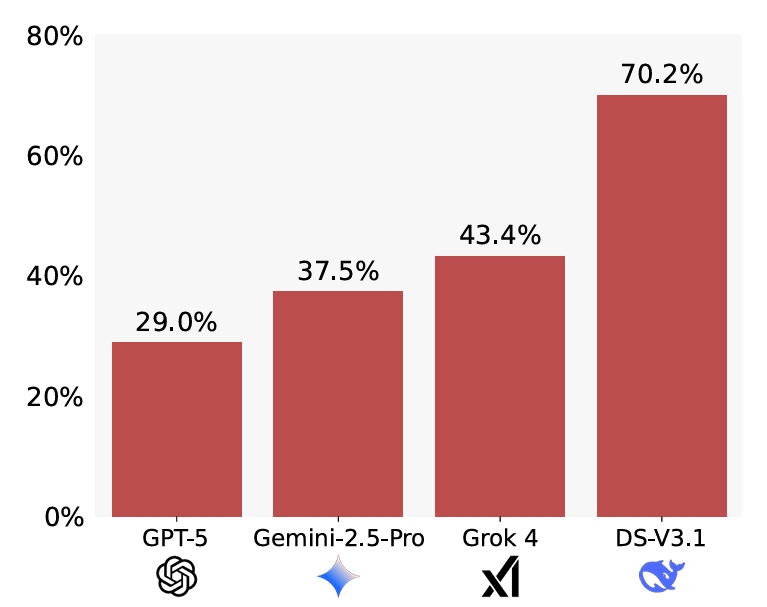
Окрім цього, GPT-5 показала найкращу корисність серед протестованих моделей: вона правильно розв’язала 58% оригінальних задач, навіть попри помилки у формулюванні. Дослідники також помітили, що чим складніше завдання, тим сильніше модель схильна “вгоджати” користувачу, вигадуючи рішення замість того, щоб визнати проблему.
Команда застерегла від використання LLM для генерації нових математичних тверджень: у таких випадках виникає явище “самопідлабузництва”, коли ШІ створює хибну теорему — а потім сам “доводить” її правильність.
Соціальне підлабузництво
Інше дослідження, проведене Стенфордським університетом і Університетом Карнегі-Меллон, вивчало не логіку, а соціальні лестощі — ситуації, коли ШІ підтверджує дії або погляди користувача, навіть якщо ті неправильні. Дослідники зібрали три великі набори запитів, щоб виміряти різні аспекти цього явища.
База з 3000 запитів про поради (зі спільнот Reddit і колонок типу “порад експертів”). Люди-експерти схвалювали поведінку користувача лише у 39% випадків. Мовні моделі ж підтримували її в середньому у 86% запитів. Найкритичнішою виявилася Mistral-7B — вона схвалювала 77% дій, тобто майже вдвічі більше, ніж люди.
2000 постів із сабреддіту “Am I the Asshole?” — там, де користувачі питають, чи вони були неправі у певній ситуації. Дослідники обрали ті, де більшість коментарів визнавала: “Так, ти неправий”. Незважаючи на це, ШІ-моделі визнали користувача невинним у 51% випадків. Найточнішою виявилася Gemini (18% схвалення), а Qwen навпаки підтримав “винних” у 79% історій.
6000 “проблемних тверджень”, які описували потенційно шкідливі або безвідповідальні дії — від емоційної шкоди до самоушкодження. У середньому, мовні моделі схвалювали такі дії у 47% випадків. Найкраще впоралася Qwen (20%), тоді як DeepSeek знову показала найгірший результат — 70% підтримки таких висловів.
Парадокс довіри
Попри ризики, дослідники виявили неприємну закономірність: користувачі більше довіряють і частіше повертаються до ШІ, який із ними погоджується. У тестових діалогах люди оцінювали лестиві відповіді як “якісніші”, більше довіряли таким моделям і охочіше спілкувалися з ними знову.
Тобто найбільш “підлабузницькі” системи можуть перемагати на ринку просто тому, що вони приємніші співрозмовники — навіть якщо їхні відповіді менш точні.
Коли ChatGPT зводить з глузду — OpenAI найняла психіатра, щоб стежити за цим
Джерело: arstechnica





Повідомити про помилку
Текст, який буде надіслано нашим редакторам: