

Судя по всему, в список игр, первенство в которых за последнее время машины отобрали у людей, уже можно занести еще одну. Речь о культовом шутере Quake 3 Arena. Компания Google DeepMind объявила о создании искусственного интеллекта, способного играть в эту игру не просто как человек, а даже лучше человека. Сразу оговорим, что речь о режиме Capture The Flag (CTF) — захват флага, в котором для победы нужно захватить вражеский флаг и принести на свою «базу».
Как и в случае с другими схожими проектами создания ИИ для той или иной 3D-игры, главная сложность здесь заключается в том, чтобы обучить бота ориентироваться в огромном трехмерном пространстве, не имея точных топографических данных. Иными словами, уметь сориентироваться на местности без карты.
Специалисты DeepMind использовали метод обучения с подкреплением (reinforcement learning), который уже стал стандартом в отрасли. Аналогичным образом обучалась система AlphaGo и прочие алгоритмы, сумевшие обыграть человека в нескольких видеоиграх Atari. Основное этого метода от классического машинного обучения заключается в том, что ИИ обучается в процессе взаимодействия с окружающей средой методом проб и ошибок, а не на исторических данных.
В самом начале обучения бот не имеет ни малейшего представления о самой игре и что в ней нужно делать. Разобраться во всем ему предстоит в одиночку. Обычно одному боту в противники ставят другого, и они начинают учиться. Но DeepMind решила пойти более сложным путем и организовать групповые занятия для 30 ботов с целью достижения более высокого разнообразия стилей игры.
Сколько потребовалось сыграть игр, чтобы выйти на приемлемый уровень? Около 0,5 млн продолжительностью по 5 минут каждая. Путем несложных подсчетов можно понять, что обучение заняло 1736 дней чистого времени.
Казалось бы, сама концепция, положенная в основу этого метода, простая как двери, но результат впечатляет. Боты DeepMind смогли узнать не только в чем, собственно, состоит цель игры, но и самостоятельно выработали и освоили разные тактики, подразумевающие защиту собственного флага, совместные атаки на базу противника и слаженную командную игру.
Важный момент – каждая новая игра происходила на полностью новой, процедурно генерируемой карте. Таким образом, ботов стимулировали к выработке разных тактик, подходящих к той или иной карте.
В отличие от ботов OpenAI для игры Dota 2, боты DeepMind не имели доступа к числовым данным – потокам чисел, которые отражают такую информацию, как расстояние между противниками и шкала здоровья. Вместо этого они учились воспринимать игру как человек — то есть наблюдая только за экраном. Но это вовсе не означает, что DeepMind проделала более трудоемкую работу; Dota 2 куда сложнее, чем урезанная версия Quake III, используемая в исследовании DeepMind.
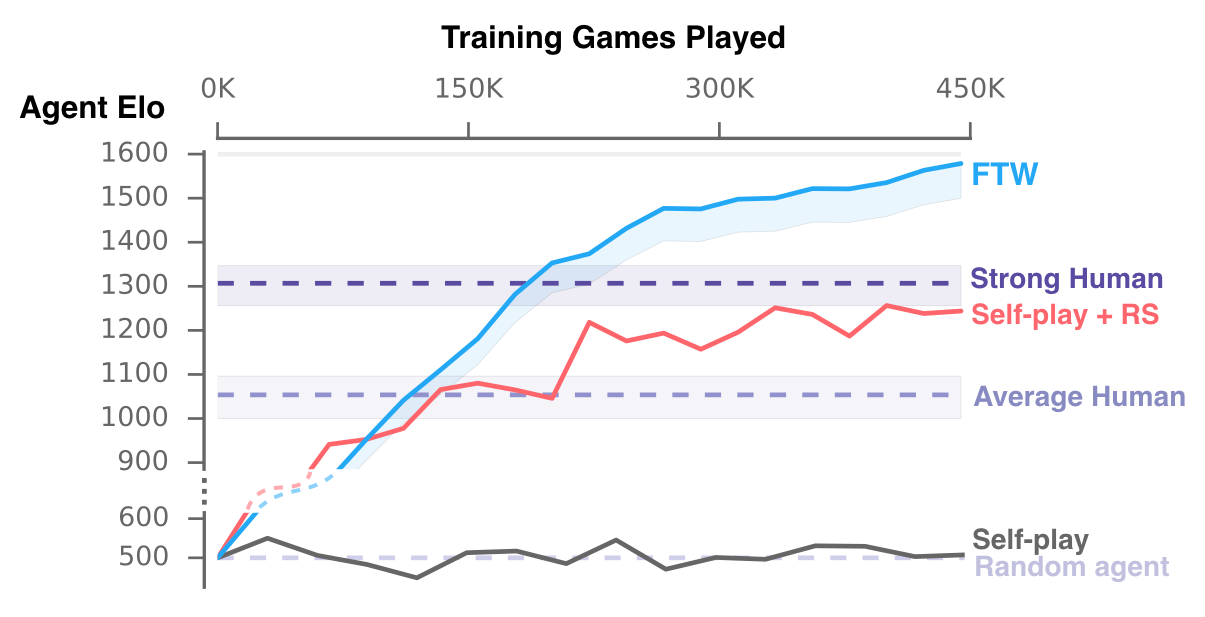
Для оценки возможностей ботов специалисты DeepMind организовали турнир, в котором команды из двух игроков (оба бота, оба человека, бот + человек) сражались друг против друга. В итоге наилучший результат показала команда, в которой оба игрока были ботами. Ее оценка вероятности выигрыша составила 74% против 43% у средних игроков и 52% у профессиональных игроков. То есть, можно сказать, что компьютер больше не уступает человеку при игре в Quake III, по крайней мере в режиме захвата флага.
Справедливости ради отметим, что в командах из большего числа игроков боты играли хуже. Например, для команды из четырех ботов вероятность выигрыша составляла уже 65%. Таким образом, хоть боты и получили базовое знания о командной работе, их оказалось недостаточно для масштабирования на более сложную командную динамику. Иными словами, еще есть над чем работать. Тем более, что цель этого исследования, как и любого другого в этой области, состоит вовсе не в том, чтобы победить человечество в видеоиграх, а в поисках новых способов обучения ИИ ориентироваться в сложной среде для достижения поставленной цели. Другими словами, речь идет об обучении с использованием средств коллективного интеллекта, который (несмотря на обилие доказательств обратного) всегда считался неотъемлемой частью успеха человечества как вида.
Источник: DeepMind и The Verge
- Компания DeepMind, купленная Google в 2014 году за $400 млн, занимается разработками в области искусственного интеллекта.
- Ранее DeepMind разработала алгоритм AlphaGo, который сумел победить человека в игру го. Создание ИИ для этого игры считалось одной из наиболее сложных задач в этой области.





Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: