

Ежедневно миллионы людей используют сервисы Google даже не подозревая, что в этот момент решить их задачи помогают не просто компьютеры, а машины, которые учатся. Они позволяют находить более релевантную информацию, улучшают перевод с одного языка на другой, превращают голос в текст и борются со спамом в почте. И это далеко не всё, что позволяет реализовать машинное обучение. На специальном мероприятии в Цюрихе, компания Google рассказала, как и зачем учит компьютеры, и как они помогут нам в будущем.
Содержание
Маффины или чихуахуа, шарпей или круассан? Почему машинное обучение — это сложно
Открытый в прошлом году в Цюрихе исследовательский центр, занимающийся машинным обучением, выделяет четыре основные направления своей работы: основы машинного обучения (инструменты и платформы), компьютерное восприятие (распознавание изображений и видео), обработка естественного языка, а также алгоритмы и компрессия.
По словам Анны Ухановой, технического менеджера по исследованиям в Google, компания сейчас пытается создать машины, которые бы выглядели умными, в то время как думающий компьютер пока остаётся очень сложной задачей. При этом Google достигла определённых успехов в некоторых областях, например, в машинном переводе с использованием нейронных сетей. Но пока архитектура этих нейронных сетей хороша только для решения тех задач, для которых они создавались.

«Человек не рождается со знанием, что коровы едят траву, он получает эту информацию от окружающего мира» — объясняет Эммануэль Могене, глава европейского исследовательского центра Google — «Чтобы реализовать это для машин, необходим огромнейший объём данных, и мы близки к тому, чтобы его получить. Если взять все изображения доступные в интернете, то это примерно такое же количество изображений, которое вы видели за свою жизнь. Но нам также необходимо больше производительности, ведь если посмотреть на количество нейронов в мозгу человека и на то, как хорошо они взаимодействуют друг с другом, то мы пока не можем реализовать это в компьютере, а тем более воссоздать человеческий мозг».
Также важно отметить, что с самого детства люди получают информацию об окружающем мире посредством шести основных органов чувств, в то время как компьютер в этом плане ограничен, ему нужны данные, которыми можно описать окружающий мир. «Если я покажу вам картинку и спрошу, есть ли на ней кто-нибудь, вы легко сможете ответить да или нет. Но вы не сможете объяснить, как именно ваш мозг пришёл к этому решению» — рассказывает Могене.
В качестве одной из проблем, с которой сталкивается машина при, например, попытке распознать изображение — это визуально похожие фотографии. Компьютеру довольно сложно отличить маффин от чихуахуа, а шарпея от круассана. И если вы посмотрите на эти изображения, то поймёте почему. Иногда и человеческий мозг, очень продвинутую вычислительную машину, можно обмануть.


Таким образом компьютеры пока учатся, чтобы быть умнее, но им далеко до настоящего искусственного интеллекта, который может думать и решать более сложные задачи. Тем не менее исследователи в Google не сидят на месте. «Искусственный интеллект — это сложное поле для исследований, и оно состоит из нескольких компонентов, которые отвечают за прогресс в этой области» — объясняет Анна Уханова — «И как мы видим, за последние пять лет мы достигли хороших результатов. Во-первых, большую роль в этом сыграл рост вычислительных мощностей, что позволило тренировать нейронные сети. Во-вторых, количество доступной информации, примеров и специализированных данных, которые нужны для решения конкретных задач. В-третьих, для машинного обучения появились платформы, программное обеспечение, которое может быстро обучаться. Это, например, Tensorflow, проект с открытым программным кодом, который позволяет всем желающим работать с машинным обучением, используемым в таких крупных компаниях, как Google. И в-четвёртых, но самое важное — это креативность и знания, которые инженеры и учёные вкладывают в системы машинного обучения. Это может быть новая архитектура нейронной сети или комбинация определённых алгоритмов, предложенная сообществу исследователей. В итоге, чтобы двигаться вперёд, нам нужные все эти четыре составляющие, и это одна из причин, почему мы делимся своими исследованиями, выступаем на конференциях, обмениваемся знаниями».
Что такое глубокое машинное обучение?
«Машинное обучение началось ещё в 90-х годах, тогда мы использовали SVM (support vector machine — метод опорных векторов), а с 2006 года появилось глубокое машинное обучение (deep learning) — это более продвинутая техника, чтобы обучать компьютеры» — рассказывает Эммануэль Могене — «И в большей степени это мощность новых нейросетей, они просто намного больше тех, которые были у нас в самом начале. Но самое главное, они сделали глубокое машинное обучение реальностью, и самое интересное это то, зачем они нам понадобились. Нейронные сети — не новое изобретение, они появились ещё в 80-х годах, но не работали. Причины, по которым они не работали: у нас не было достаточно данных и компьютерной мощности. Эксперименты прогонялись на трёх «нейронах», что занимало около трёх дней, и это были очень простые задачи. Но доступность огромных массивов информации, благодаря интернету, и значительный рост производительности компьютеров, благодаря видеокартам, позволил глубокому машинному обучению взлететь».
Как Google тренирует нейронные сети
Сегодня существует несколько техник машинного обучения: с учителем, без учителя и с подкреплением.
1. Обучение с учителем — это обучение на примерах, на манер того, как спам-фильтр Gmail фильтрует почту, получая всё новые и новые примеры спам-рассылок. Единственная проблема с этим способом: для того, чтобы он был эффективным, нужно иметь большое количество готовых примеров.
2. Обучение без учителя — это кластеризация данных, компьютеру предоставляются объекты без описания и он пытается найти между ними внутренние закономерности, зависимости и взаимосвязи. Так как данные изначально не имеют обозначений, то для системы нет сигнала ошибки или награды, и она не знает правильного решения.
3. Обучение с подкреплением — этот метод связан с «обучением с учителем», но здесь данные не просто вводятся в компьютер, а используются для решения задач. Если решение правильное, то система получает позитивный отклик, который запоминает, подкрепляя тем самым свои знания. Если же решение неверное, то компьютер получает негативный отклик, и должен найти другой способ решения задачи.
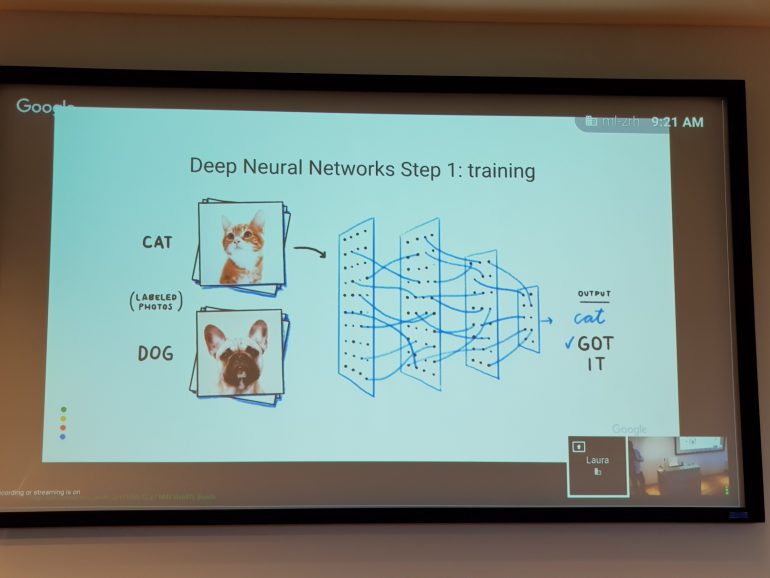

В Google в основном используют обучение с учителем. Например, если загрузить в нейросеть миллионы изображений котов и собак, то она научится отличать их между собой. При этом, по словам Эммануэль Могене, если дать нейросети большой объём памяти, она не учится, а просто запоминает всё, что в неё загружают. Но если уменьшить хранилище, ей приходится выделять и запоминать только то, что позволит в дальнейшем решить задачу. Именно так и происходит процесс обучения.
Обучение без учителя является другим направлением машинного обучения. «Мы загружаем в машину данные, и она пытается найти кластеры информации, которые может обработать. Это намного сложнее, чем учиться на примерах, но если у системы получится обработать данные, которые не были размечены — это позволит загружать в неё информацию без примеров. Например, ей можно будет показать изображения яблок, клубники и бананов, но без описания, и она сможет отсортировать их по типу и в дальнейшем различать» — объясняет принцип обучения без учителя Анна Уханова.
Один из экспериментов Google позволяет построить нейросеть без использования кода, попробуйте по ссылке. А ещё один позволяет поиграть с распознаванием изображений.
Необъективность и машинное обучение
Во время тренировки нейросетей иногда случают курьёзные ситуации, которые связаны с тем, что исходные данные могут быть необъективными. Дело в том, что сами люди по-разному воспринимают окружающий мир. Например, если попросить людей из разных стран изобразить стул, это будут разные рисунки.

То же самое произойдёт и с обувью, у каждого свои представления о том, как она выглядит. При этом если обучать компьютер на основе одних рисунков стульев или обуви, то он просто не сможет распознать другие.
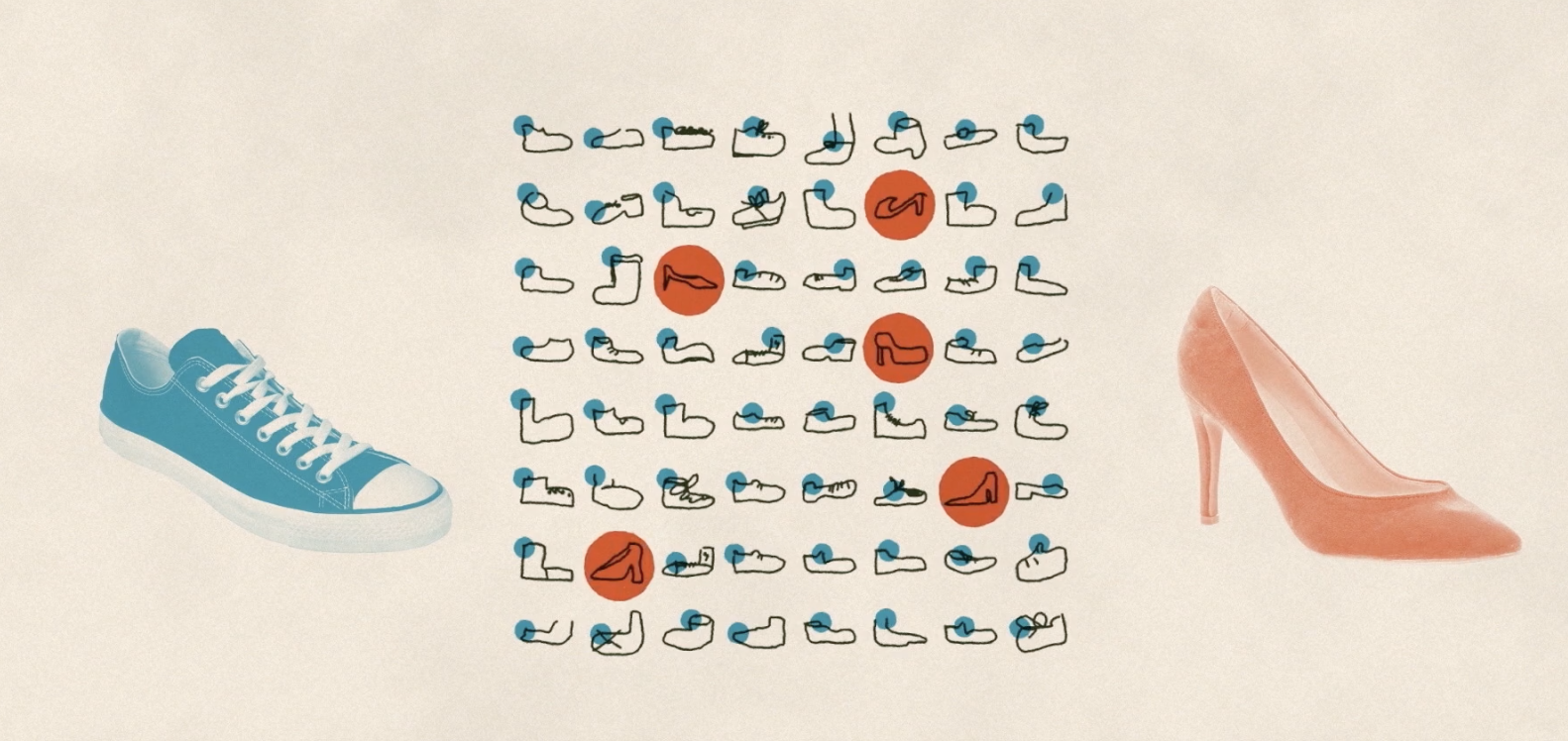
Таким образом получается, что нейронная сеть может плохо справляться с задачей из-за недостаточно объективных данных, а не потому, что она плохо натренирована.
В каких продуктах Google используется машинное обучение
В Google называют себя компанией «AI first» (ИИ в первую очередь), что должно подчеркнуть их стремление использовать искусственный интеллект как можно в большем количестве продуктов и сервисов. И на сегодня Google вполне неплохо в этом преуспевает. Всё началось с внедрения системы борьбы со СПАМом в Gmail, но теперь машинное обучение используется не только в почте. Когда вы вводите поисковый запрос в Google, то получаете ответы, которые ранжируются с использованием искусственного интеллекта. Но, кроме этого, машинное обучение работает в виртуальном помощнике Google Assistant, в рукописном вводе на Android, в поиске по изображениям, рекомендациям в Google Play и YouTube, в локальном поиске Google Maps, и, конечно же, в Google Translate, который способен переводить текст, изображения и речь с одного языка на другой.

Google использует машинное обучение даже в клавиатуре Gboard, чтобы улучшить текстовый и голосовой ввод. При этом и выделение текста в Android 8 не обходится без нейронной сети, которая автоматически выделяет адреса и номера телефонов.
Человек и машина
«Я верю, что человек и машина в будущем будут работать вместе» — рассуждает Эммануэль Могене — «Один из моих любимых примеров — это медики, которые не всегда хорошо справляются с диагностикой, но они намного лучше взаимодействуют с людьми, чем компьютеры. Поэтому в будущем я бы хотел приходить на приём к доктору-человеку, который говорил бы со мной, проявлял эмпатию, но при этом диагноз ему помогал устанавливать искусственный интеллект. Для меня это идеальный сценарий, когда человек и машина работают вместе».
Чтобы приблизить этот день, в Google работают на нейросетями, которые могут диагностировать болезни. Как рассказала Лили Пенг, менеджер по продуктам команды Medical Imaging в Google Research, на данный момент, созданная Google нейросеть позволяет диагностировать диабетическую ретинопатию (заболевание, которое поражает больных диабетом и может привести к полной слепоте) на уровне высококвалифицированных докторов.
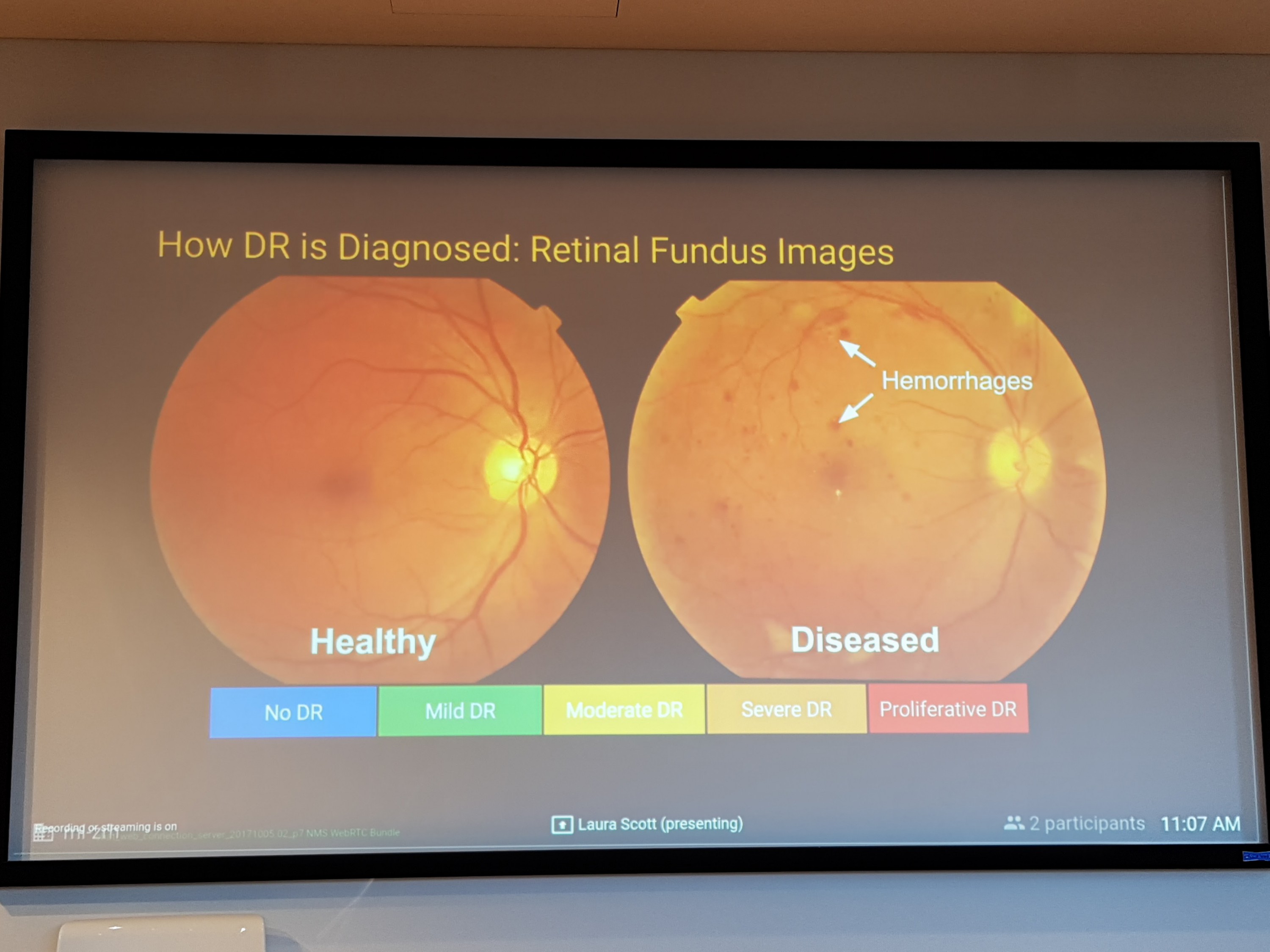
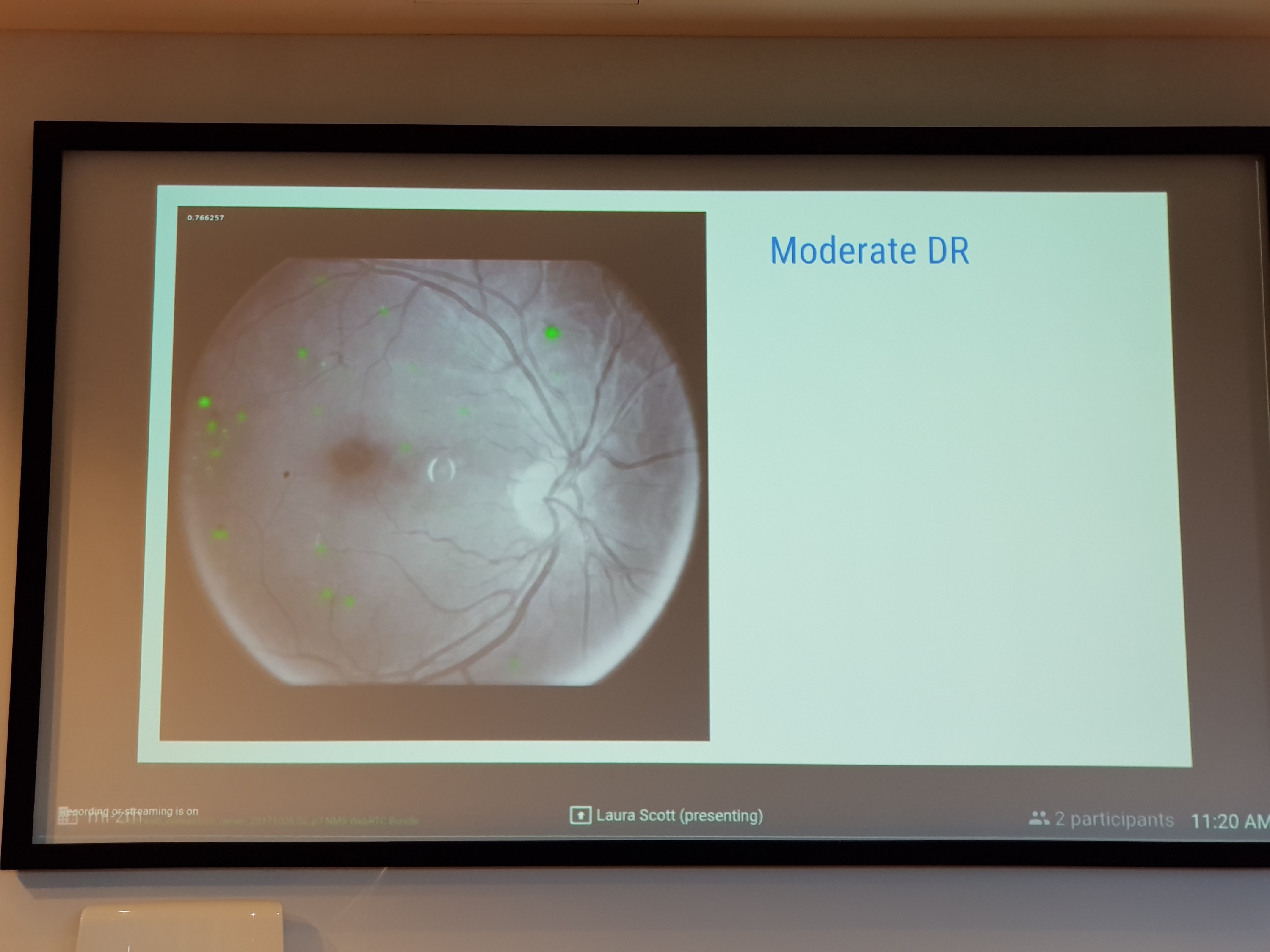
Для диагностики этой болезни используется ретинальная камера, она делает снимок глазного дна, после чего доктор может увидеть на нём кровоизлияния, которые говорят о наличии болезни. Используя 130 тыс снимков с диабетической ретинопатией, которые были промаркированы 54 врачами-офтальмологами, исследователи из Google натренировали нейросеть находить на снимках кровоизлияния, определяя степень заболевания. Она оказалась настолько эффективной, что может отличить кровоизлияние от пыли, попавшей на объектив ретинальной камеры.
Ещё одной областью, которой занимается Google в исследовании взаимодействия человек с искусственными интеллектом, является машинное обучение в искусстве. Для этого был создан проект Magenta, который должен объединить креативных программистов, художников и музыкантов. По словам Дугласа Эка, учёного-исследователя в команде Google Brain, в Google верят, что искусственный интеллект в будущем позволит артистам создавать новые шедевры, расширяя арсенал их возможностей, а также инструментов. Базовые возможности ИИ в создании музыки и рисунков можно оценить уже сегодня с помощью этих двух экспериментов: Performance RNN и Sketch-RNN.

Для того, чтобы исследовать новые области взаимодействия человека с искусственным интеллектом в Google летом этого года запустили проект PAIR (People+AI Research Initiative). Основная цель данной инициативы — разработка систем ИИ, с которыми людям будет просто и приятно взаимодействовать. Поэтому в PAIR предоставляют открытые инструменты и платформы для разработчиков систем машинного обучения, образовательные материалы, делают академические публикации, а также проводят презентации и симпозиумы.
В итоге
За последние несколько лет машинное обучение заметно продвинулось, что позволило компьютерам стать умнее и решать более сложные задачи. И хотя пока речь не идёт о думающей машине, в Google считают, что на данном этапе компьютер, который выглядит умным, это основа для дальнейших прорывов в области искусственного интеллекта. И дело не только в том, что говорить про ИИ стало модно, согласно исследованиям Google больше 50% американцев всех возрастов верят, что искусственный интеллект может быть полезным, а среди молодых людей таких больше 70%. При этом больше 50% молодых людей хотят видеть ИИ в большем количестве продуктов. Поэтому тут скорее обоюдный тренд, сталкиваясь с умными машинами, людям нравятся возможности, которые они предоставляют, а компании не могут игнорировать потребности своих пользователей. Таким образом, в дальнейшем мы будем всё чаще слышать про искусственный интеллект в совершенно разных устройствах и сервисах.





Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: