



Новое исследование обнаружило ограничения современных генеративных моделей искусственного интеллекта, таких как ChatGPT или Midjourney. Модели, обучаемые на данных, сгенерированных ИИ, будь то тексты или изображения, имеют тенденцию «сходить с ума» после пяти циклов обучения. Изображение выше показывает наглядный результат подобных экспериментов.
MAD (Model Autophagy Disorder) – аббревиатура, используемая исследователями Райс и Стэндфордского университет для описания того, как качество выдачи моделей ИИ деградирует при многократном обучении на данных, сгенерированных ИИ. Как следует из названия, модель «поедает сама себя». Он теряет информацию о «хвостах» (крайних точках) исходного распределения данных и начинает выводить результаты, которые больше соответствуют среднему представлению.
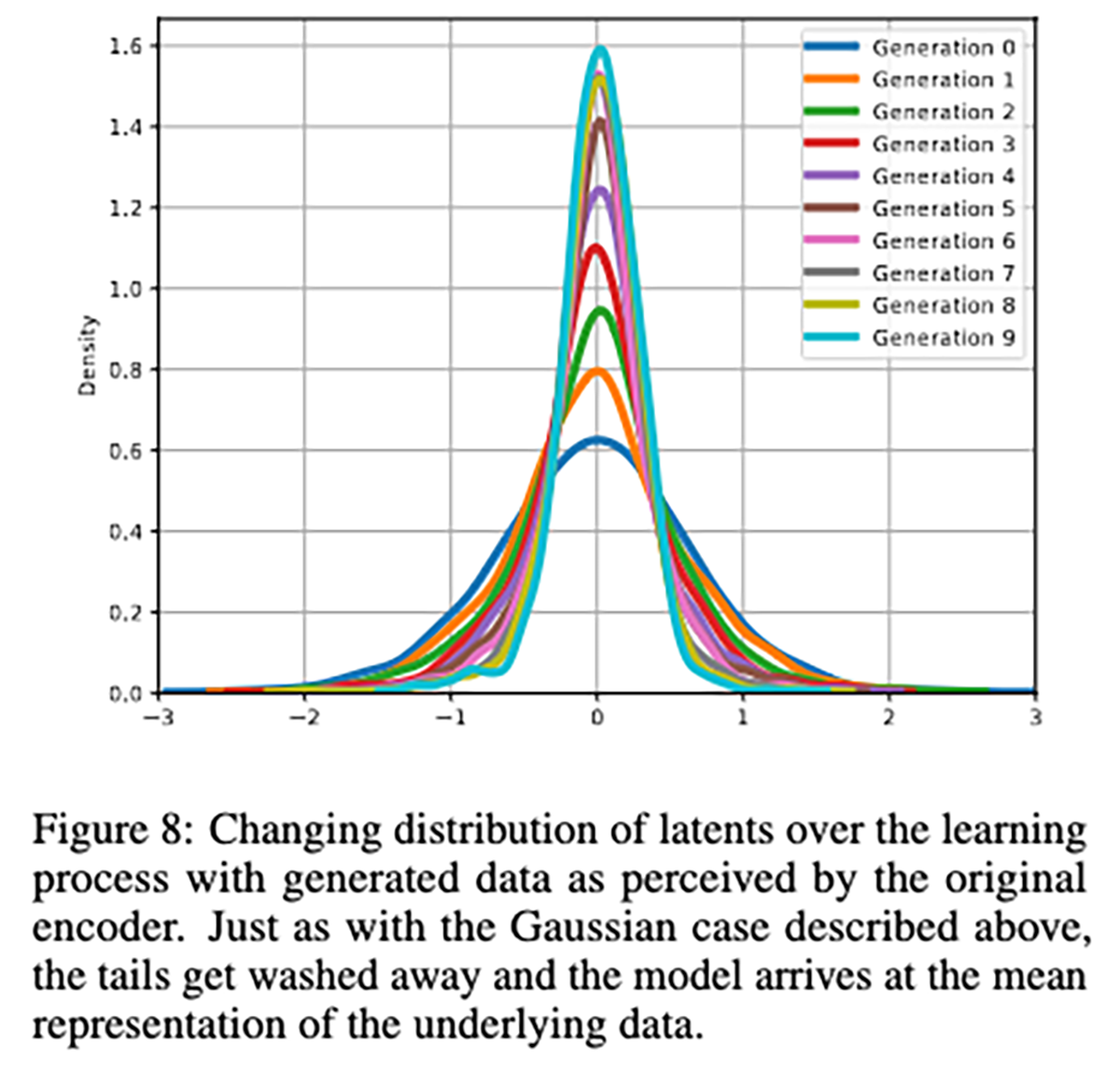
По сути, обучение LLM (больших языковых моделей) на собственных (или аналогичных) результатах создает эффект конвергенции. Это легко увидеть на приведенном выше графике, которым поделился член исследовательской группы Николас Пейпернот. Последовательные итерации обучения на данных, сгенерированных LLM, приводят к тому, что модель постепенно (но довольно резко) теряет доступ к данным, лежащим на периферии графика.
Данные по краям спектра (то, что имеет меньше вариаций и меньше представлено) практически исчезают. Из-за этого данные, которые остаются в модели, теперь менее разнообразны и регрессируют к среднему значению. Согласно результатам, требуется около пяти итераций, пока «хвосты» исходного распределения не исчезнут.
Не подтверждено, что такая аутофагия влияет на все модели ИИ, но исследователи проверили его на автокодировщиках, смешанных моделях Гаусса и больших языковых моделях. Все они широко распространены и работают в разных сферах: предсказывают популярность, обрабатывают статистику, сжимают, обрабатывают и генерируют изображения.
Исследование говорит, что мы не имеем дело с бесконечным источником генерации данных: нельзя неограниченно получать их, обучив модель один раз и далее основываясь на ее же собственных результатах. Если модель, получившая коммерческое использование, на самом деле была обучена на своих собственных выходных данных, то эта модель, вероятно, регрессировала к среднему значению и является предвзятой, так как не учитывает данные, которые были бы в меньшинстве.
Еще одним важным моментом, выдвинутым результатами, является проблема происхождения данных: теперь становится еще важнее иметь возможность отделить «исходные» данные от «искусственных». Если вы не можете определить, какие данные были созданы LLM или приложением для создания изображений, вы можете случайно включить их в обучающие данные для своего продукта.
К сожалению, этот «поезд» во многом уже ушел: существует ненулевое количество немаркированных данных, которые уже были созданы этими типами сетей и включены в другие системы. Данные, созданные ИИ, стремительно распространяются, и 100% способа отличить их нет, тем более для самих ИИ.
Источник: Tom’s Hardware





Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: